



Perceptron (P), na prática: filtro neural de mensagens para agentes IA


Construir nossas aplicações agênticas é realmente incrível, mas como bons engenheiros de IA, sabemos que cada token executado custa dinheiro. E quando começamos a escalar agentes, esse custo pode sair do controle muito rapidamente.
Pensando nisso, resolvi criar este post para te mostrar como filtrar mensagens a partir de uma rede Perceptron, garantindo que apenas o que realmente importa seja processado pelo modelo.
Com um bom mecanismo de filtragem, conseguimos:
- Reduzir custos com tokens.
- Evitar chamadas desnecessárias ao LLM.
- Melhorar o desempenho do seu sistema de IA.
Neste conteúdo, vamos explorar como aplicar filtros de mensagens, na prática, garantindo que somente mensagens aprovadas pelo seu critério cheguem ao seu modelo, mantendo eficiência, controle e economia.
O que é a rede Perceptron (P)
A rede do tipo Perceptron é uma das arquiteturas mais simples e fundamentais da história das redes neurais, representando um marco inicial no desenvolvimento da Inteligência Artificial. Proposta por Frank Rosenblatt em 1957, essa rede foi inspirada no funcionamento de um neurônio biológico, buscando simular como sinais de entrada são processados para gerar uma decisão.
Em sua forma mais simples, o Perceptron pode ser entendido como um classificador linear, capaz de separar duas classes a partir de uma combinação linear das entradas. De maneira informal, pode até ser comparado a uma estrutura de if/else, mas com pesos ajustáveis aprendidos a partir dos dados. A rede recebe um vetor de entradas, multiplica cada valor pelo seu peso correspondente, soma os resultados e, em seguida, aplica uma função de ativação para produzir a saída final.
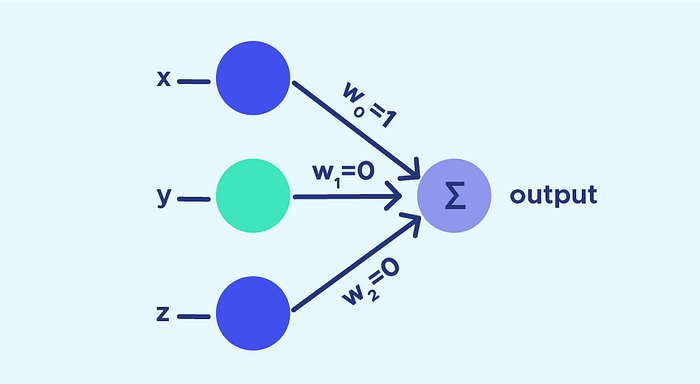
Apesar de sua simplicidade, o Perceptron é surpreendentemente poderoso para resolver problemas linearmente separáveis. Ele estabeleceu as bases conceituais para arquiteturas mais avançadas, como as redes neurais multicamadas e os algoritmos de backpropagation. Compreender o Perceptron é essencial para entender como modelos aprendem padrões a partir de dados e como essas ideias evoluíram ao longo do tempo.
No nosso caso prático, utilizaremos uma lista de palavras como vetor de entrada para determinar uma condição de execução — ou seja, decidir se uma ação deve ou não ser realizada. Essa abordagem pode facilmente evoluir para um roteiro automatizado no futuro, onde as entradas seriam geradas dinamicamente a partir dos dados enviados ao agente. Para este exemplo, porém, trabalharemos com uma lista estática para facilitar o entendimento.
Criando nosso filtro com Perceptron (P)
Agora que já entendemos os conceitos básicos, vamos criar nosso filtro utilizando o Perceptron.
O primeiro passo é importar as bibliotecas que serão utilizadas ao longo do projeto. Todo o desenvolvimento será feito no Google Colab, facilitando a execução e a reprodução dos experimentos.
import numpy as np
from sklearn.feature_extraction.text import TfidfVectorizerAgora, vamos criar a lista de palavras que será utilizada como base para o treinamento do modelo. Em seguida, iremos definir o eixo y do treinamento, atribuindo a cada vetor de entrada um rótulo que indica se aquela pergunta pode ou não ser processada pelo modelo.
Esses rótulos serão valores binários:
- 1 → pergunta permitida (o modelo pode executar)
- 0 → pergunta não permitida
Para este exemplo, consideraremos apenas duas perguntas permitidas:
- “Qual meu saldo?”
- “Qual o valor da fatura?”
Essas perguntas serão representadas como vetores de entrada (x) e associadas ao valor 1 no eixo y, enquanto quaisquer outras variações ou perguntas fora desse escopo poderão ser rotuladas como 0.
texts_train = [
"oi",
"olá",
"bom dia",
"qual meu saldo?",
"qual o valor da fatura?",
"explique backpropagation",
"compare gpt e claude",
"como implementar um perceptron",
"asdfasdf",
"ajuda",
"implemente um algoritmo de gradiente descendente",
]
y = np.array([
0,
0,
0,
1,
1,
0,
0,
0,
0,
0,
0
])Em nossa próxima etapa, criamos um objeto TfidfVectorizer, responsável por converter textos em vetores numéricos que podem ser utilizados pelo nosso modelo.
lowercase=TrueConverte todo o texto para letras minúsculas, evitando que palavras iguais sejam tratadas como diferentes devido a maiúsculas.max_features=30Limita o vocabulário a no máximo 30 palavras mais relevantes, reduzindo a dimensionalidade e facilitando o treinamento do modelo.
Após isso treinamos o nosso modelo:
vectorizer = TfidfVectorizer(
lowercase=True,
max_features=30
)
X = vectorizer.fit_transform(texts_train).toarray()
print("X treino:", X.shape)
Agora a estrela do post chega, iremos criar uma classe que gera o nosso modelo e faz uma classificação binária. Ele funciona ajustando pesos (w) e um viés (b) ao longo de épocas em nosso treinamento, com base no erro cometido em cada previsão.
Durante o treino, o modelo calcula uma combinação linear das entradas, decide a classe usando um limiar (zero) e, caso a previsão esteja incorreta, atualiza os pesos e o viés proporcionalmente à taxa de aprendizado. Ao final, o método de predição utiliza esses parâmetros aprendidos para classificar novos dados, retornando 0 ou 1, indicando se a entrada pertence ou não à classe permitida.
class Perceptron:
def __init__(self, lr=0.1, epochs=40):
self.lr = lr
self.epochs = epochs
def fit(self, X, y):
self.w = np.zeros(X.shape[1])
self.b = 0
for _ in range(self.epochs):
for i in range(len(X)):
z = np.dot(X[i], self.w) + self.b
y_pred = 1 if z >= 0 else 0
error = y[i] - y_pred
self.w += self.lr * error * X[i]
self.b += self.lr * error
def predict(self, X):
z = np.dot(X, self.w) + self.b
return (z >= 0).astype(int)
Neste trecho a seguir, criamos uma instância do modelo Perceptron e iniciamos o processo de treinamento utilizando os dados de entrada (X) e seus respectivos rótulos (y).
model = Perceptron()
model.fit(X, y)
print("Pesos:", model.w.shape)
Por fim, criaremos uma função para determinar se deve ou não executar um LLM:
def should_call_llm(text: str) -> bool:
x = vectorizer.transform([text]).toarray()
return bool(model.predict(x)[0])
E agora chegamos ao momento que estávamos esperando: a função responsável por decidir se um modelo de LLM deve ou não ser executado.
tests = [
"qual meu saldo?"
]
if should_call_llm(tests[0]) == True:
print("Chamar LLM")
else:
print("Não chamar LLM")
Com base no que foi aprendido durante o treinamento, essa função recebe uma nova pergunta, transforma o texto no mesmo formato vetorial usado no treino e utiliza o Perceptron para realizar a classificação.
O resultado é uma decisão binária (0 ou 1), indicando se a consulta é válida e pode seguir para o processamento pelo LLM ou se deve ser bloqueada, atuando assim como um filtro inteligente de entrada antes da chamada ao modelo de linguagem.
O melhor disso é que ele entende variações, como:
- Qual meu saldo
- Qual saldo
- Gostaria de saber qual é o meu saldo mesmo?
Veja que, mesmo em um exemplo simples como o nosso, a rede já se mostrou capaz de resolver o problema proposto, atuando como um filtro inteligente para decidir se um modelo deve ou não ser executado. Esse tipo de abordagem é extremamente poderoso na construção de agentes, ao permitir treinar um modelo leve, exportar seu binário e executá-lo em uma API própria, filtrando as mensagens antes mesmo de elas chegarem ao agente ou ao LLM. Por hoje é isso que eu gostaria de trazer.
Sou um grande entusiasta das principais tecnologias de ciência de dados e Machine Learning. Trabalho com Python para análise de dados, construção de modelos de Machine Learning e deep learning utilizando bibliotecas como TensorFlow, PyTorch, Scikit-learn e Pandas. Utilizo Jupyter Notebooks para prototipagem rápida e visualização de dados com Matplotlib e Seaborn. Para implementação de soluções de Machine Learning, uso ferramentas como Docker, Kubernetes e Apache Kafka. Além disso, aplico técnicas avançadas de processamento de linguagem natural (NLP) com NLTK, SpaCy e Hugging Face Transformers. Em big data, uso Apache Spark e Hadoop para processamento e análise de grandes volumes de dados. Criador do Design Pattern BFA BackEnd For Agents e sou apaixonado por criatividade, conhecimento e inovação. Por isso, sempre que possível, realizo palestras, escrevo livros técnicos e atuo como instrutor em escolas como Ada Tech, 4 Linux e cursos online.


