

Olá, pessoal!
Ultimamente tenho estudado e lido bastante sobre Machine Learning, e devo confessar: eu fiquei assustado com a facilidade de criar uma solução dessas com o Azure Machine Learning.
Vamos fazer um exemplo?
Este artigo faz parte de uma série! Para visualizar a série inteira, clique aqui.
Existem duas formas diferentes de utilizar o Azure Machine Learning Studio: uma delas é gratuita e a outra paga. Há algumas diferenças entre as duas versões, mas para fins de estudo, a versão gratuita é excelente.
Você pode ficar por dentro das restrições dessa versão acessando este link.
O exemplo será feito todo através da versão gratuita – você pode autenticar com sua conta Microsoft sem medo! Depois de autenticar no Studio, você será redirecionado para a seguinte página:
Bom, o exemplo de hoje será muito mais um hands-on do que um detalhamento de cada coisa que existe no Studio.
É muito importante que você tenha uma noção mínima de Machine Learning antes de começar a fazer essa implementação. Caso não tenha, dê uma passada neste artigo e depois volte pra cá.
O Azure nos permite fazer o experimento do início ao fim, desde obter os dados, até expor um modelo treinado por web service. Vamos entender o ambiente antes de começar a implementação.
É possível visualizar um menu lateral, conforme na imagem abaixo:

Este menu agrupa os artefatos envolvidos com sua conta. Hoje trabalharemos apenas com um experimento, então selecione o item Experiment.
Tudo começa com a criação de um experimento, então vá até o menu inferior e pressione o botão “+ NEW” no canto esquerdo, conforme na imagem a seguir:
![]()
Este botão mostrará um painel com diversos templates de experimentos. Por enquanto vamos selecionar o primeiro template: Blank Experiment.
Agora estamos na página de criação de experimentos. Você verá que um monte de itens apareceram no menu lateral e um monte de novas ações estão disponíveis no menu inferior.
Ok, vamos começar a trabalhar! Lembram da primeira etapa?
Respondendo algumas perguntas antes de começar
- 1. Escolher a pergunta que estamos tentando responder
- 2. Escolher o conjunto de dados para responder esta pergunta
- 3. Identificar como medir o resultado
A pergunta que vamos tentar responder, é:
- Baseando-se em suas características, qual o preço deste carro?
Para tentar responder a esta pergunta, vamos usar um conjunto de dados sobre automóveis, disponível no próprio Azure Machine Learning Studio.
Por fim, como faremos para medir os resultados obtidos?
Bom, essa é a etapa mais complicada, mas há uma boa estratégia para isso. Primeiro vamos analisar os dados que serão utilizados.
Para fazer isso, expanda o item Saved Datasets > Samples. Com isso, você verá o item Automobile price data (Raw), conforme na imagem a seguir:
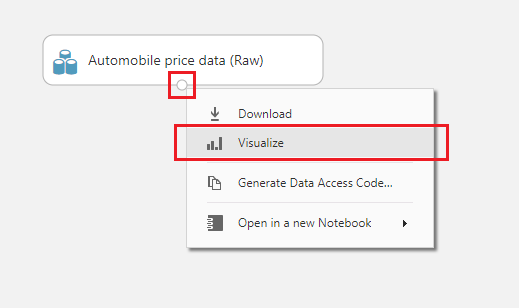
Simplesmente clique e arraste para a área indicada no próprio Studio. Um item do tipo dataset será criado em seu experimento. Para visualizar os dados pressione o círculo na base do item e selecione a opção Visualize.
Sinta-se à vontade para explorar os dados! Há muito informação disponível. Logo de cara, no diálogo, já conseguimos ver que os dados possuem 205 linhas e 26 colunas.
Além disso, temos uma informação importantíssima sobre nossos dados: a última coluna nos dá a informação de preço, então sabemos que trata-se de um aprendizado supervisionado.
Por conta da natureza deste tipo de problema, podemos medir os resultados da seguinte maneira:
- 1. Utilizamos parte dos dados para treinar nosso modelo
- 2. Aplicamos o modelo treinado na segunda parte dos dados
- 3. Comparamos o preço que o modelo informou com o preço presente no conjunto de dados
Com isso conseguimos medir o quão bom (ou ruim) nosso modelo ficou!
Começando as implementações
Com as perguntas respondidas, podemos começar nossa implementação! A única coisa que fizemos até agora foi arrastar os dados para o experimento, mas será que estes dados já estão preparados para o experimento?
Não, não estão. Lembram dos processos envolvidos?
- Pré-processamento
- Treinamento
- Avaliação
Como citado no outro artigo, o pré-processamento geralmente é a etapa mais demorada e complicada – não seria diferente em nosso exemplo!
Pré-processamento
Bom, eu disse um pouquinho antes que os dados não estão preparados, mas o que isso significa, de fato?
Significa que devemos preparar os dados para treinarmos o modelo corretamente, removendo dados inconsistentes ou colunas desnecessárias.
Quando estamos visualizando os dados é possível selecionar cada feature (coluna) do dataset. Ao fazer isso, somos expostos à uma série de informações sobre a feature selecionada. A propósito, na terminologia de Machine Learning é muito comum as colunas serem chamadas de features.
Veja um exemplo de informações sobre uma feature específica:
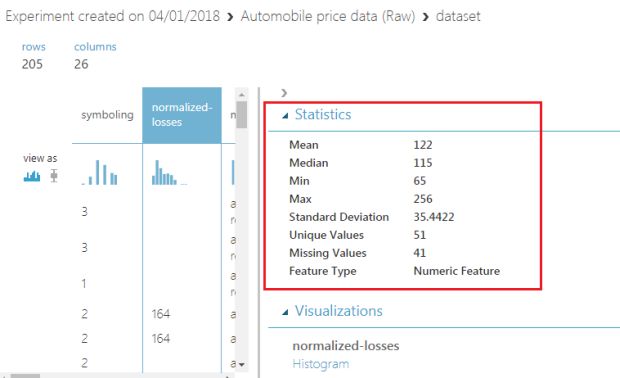
Como a imagem ilustra, há um monte de informações sobre as features. Essas informações variam de acordo com o tipo da feature.
Uma das informações relevantes nesta feature é a quantidade de linhas que não possuem esta coluna preenchida: 41.
Geralmente, em massas de dados gigantes isso não seria um problema, mas quando 41 de 205 registros não possuem a informação, ela pode ser problemática.
Para resolver isso, vamos desconsiderar essa coluna! Escolha o item Data Transformation > Manipulation > Select Columns in Dataset.
Inicialmente, ao incluir este item, você verá que ele possuí um ícone vermelho. Isso porque a transformação precisa ser vinculada a um dataset, e para fazer isso, basta conectar os dois itens.
Pressione o mesmo círculo que usamos para visualizar os dados, mas desta vez mantenha o mouse pressionado e arraste até o item seguinte!
- Mas espere, ainda temos problemas – o que houve?
Simples, ainda não selecionamos quais colunas vamos utilizar! Para fazer isso, pressione o item no experimento. No painel à direita pressione o botão Launch column selector e, por fim, selecione todas as colunas desejadas!
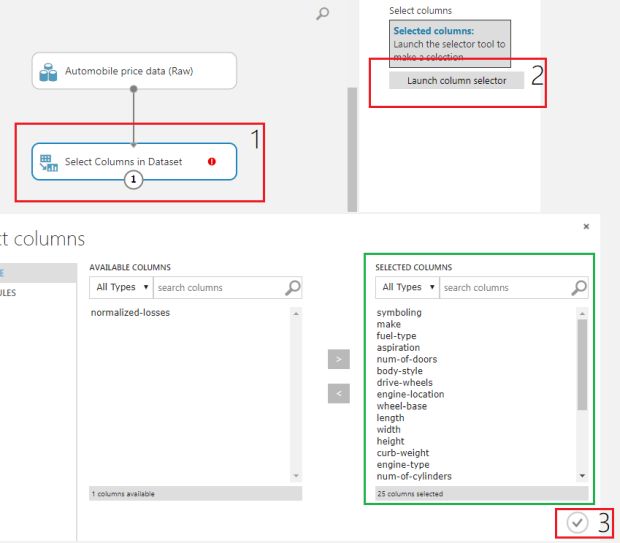
Depois de fazer isso, você deve pressionar o botão “Run” no menu inferior. Isso fará com que seu experimento seja executado e os resultados já possam ser visualizados.
Agora você pode visualizar os dados pressionando a base do item de transformação, assim como fizemos no dataset e você perceberá que a coluna excluída não está mais lá!
- Ótimo, agora os dados estão prontos!
Não tão rápido. Ainda temos que lidar com outros valores que faltam. Desta vez são exemplos mais pontuais e pequenos.
Agora adicionaremos o item Clean Missing Data presente na mesma seção Data Transformation > Manipulation. Conectaremos a saída do item anterior à ela e nas opções do painel à direita vamos selecionar como Cleaning Mode o valor: Remove entire row.
Com isso, removeremos todas as linhas que possuem valores incompletos!
Ao terminar o processo e visualizar os dados novamente, é possível notar que temos 193 linhas, ao invés das 205 originais.
Agora, sim, os dados já estão no formato ideal! O último passo é dividir os dados em dois conjuntos diferentes. Um deles será utilizado para treinamento do modelo e o outro para validação do modelo.
Como isso é uma tarefa bastante comum, temos um item preparado para isso! Utilize o componente em: Data Transformation > Sample and Split > Split Data.
Para isso, basta conectar este componente aos dados e definir o percentual de registros para divisão:
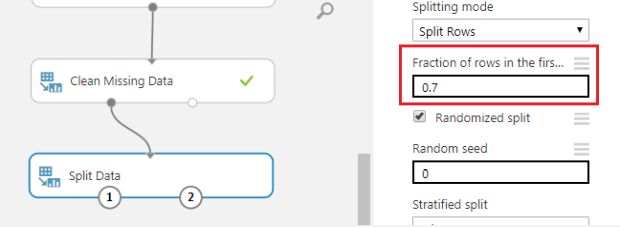
Este item possui duas saídas de dados. Uma delas será utilizada para o treino do nosso modelo e a outra para a validação do modelo já treinado!
Execute novamente o experimento e com isso este processo está finalizado!
Ainda precisamos treinar e validar nosso modelo, mas por hoje o trabalho já está feito. No próximo artigo vamos terminar o trabalho e validar os resultados.
O que você achou deste artigo? Quer ver mais artigos sobre Machine Learning? Me conte nos comentários.
Até mais!

De 0 a 10, o quanto você recomendaria este artigo para um amigo?