



Machine Learning: Implementando Regressão Linear no Azure – Parte 02
No seguinte artigo, Gabriel Schade apresenta a continuação de sua série "Machine Learning: Implementando Regressão Linear no Azure", mostrando como criar um experimento capaz de predizer preços de automóveis com uma taxa de 91% de acerto!


Olá, pessoal!
Terminaram o pré-processamento dos dados no artigo anterior? Vamos finalizar o exemplo!
Este artigo faz parte de uma série! Para visualizar a série inteira, clique aqui.
Caso não tenha feito, sugiro fortemente voltar para a primeira parte antes de continuar. Dito isso, vamos começar com as etapas restantes!
Considerando o fluxograma abaixo, o que ainda falta fazer?
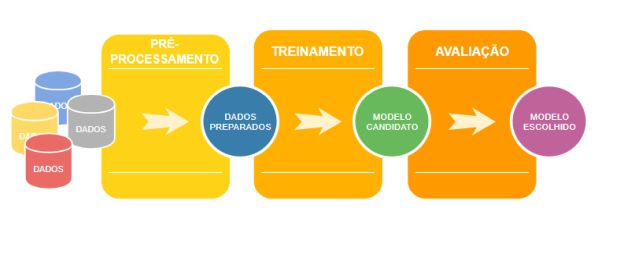
Bom, você deve ter percebido que chegamos até o item Dados Preparados. Pode parecer que ainda falta bastante coisa, mas estas etapas são mais rápidas que o pré-processamento.
Vamos continuar!
Treinamento
Essa etapa será bem mais rápida do que a anterior! Em um exemplo real, este é o momento de analisar e pensar a respeito dos algoritmos disponíveis.
Não entrarei no mérito de definir os algoritmos neste artigo (talvez em um algum futuro), mas podemos nos basear em um guia mais prático da Microsoft.
Atenção
Este guia não dispensa de maneira nenhuma o fato de que você precisa estudar e compreender os algoritmos para tomar as melhores decisões – ele é bastante superficial e visa ajudar quem está completamente perdido.
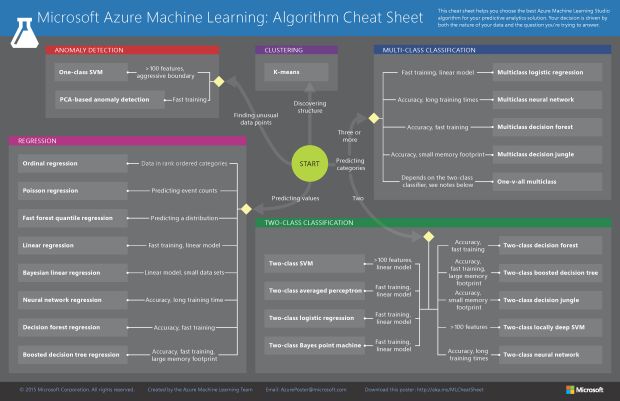
A partir do Start da imagem, podemos seguir quatro caminhos diferentes:
- 1. Finding unusual data points
- 2. Discovering structures
- 3. Predicting categories
- 4. Predicting values
Bom, estamos tentando predizer valores, então seguiremos pelo caminho de número 4. Entre os algoritmos disponíveis, vamos escolher o Linear Regression!
Basta arrastar esse algoritmo para o experimento. Ele pode ser encontrado em: Machine Learning > Initialize Model > Regression > Linear Regression. Basta arrastá-lo e é isso!
Agora precisamos treinar o modelo. Fazemos isso selecionando o componente: Machine Learning > Train > Train model.
Este componente recebe dois parâmetros. Consegue imaginar o que é? Se achou que os parâmetros eram o algoritmo e o conjunto de dados, é isso aí.
Conecte os componentes. Mas e se der erro?
O problema é que precisamos informar qual coluna estamos tentando predizer. Para fazer isso, selecione o componente e utilize novamente o column selector, mas desta vez selecione apenas a coluna price.
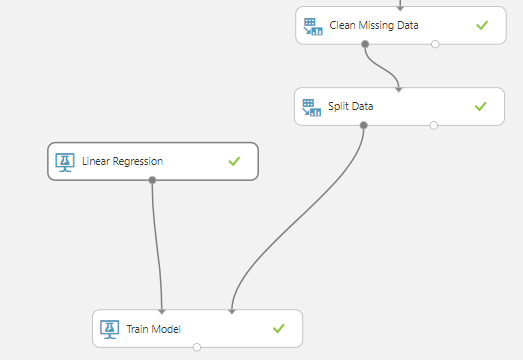
Com isso, só falta criar nosso modelo candidato!
Ele funciona de maneira similar ao modelo de treinamento, também contendo duas entradas diferentes, mas desta vez, a primeira entrada não é o algoritmo, e sim o modelo treinado.
Basta incluir o componente Machine Learning > Score > Score model e conectar as informações.
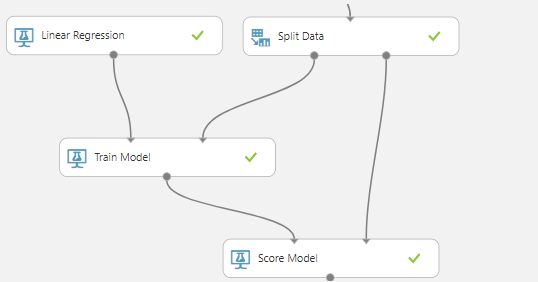
Agora já fechamos a etapa de treinamento. Fácil, né?
Avaliação
A etapa de avaliação é absurdamente simples para este exemplo. Para obter os resultados de nosso experimento basta incluir o componente Machine Learning > Evaluate > Evaluate model. Depois disso, conectamos a saída do Score Model à primeira entrada deste componente e executamos o experimento!
Agora já é possível visualizar os resultados!
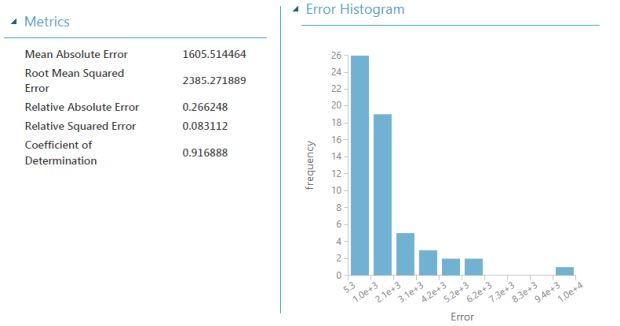
Parabéns! Pode ficar orgulhoso – você acaba de criar um experimento capaz de predizer preços de automóveis com uma taxa de 91% de acerto!
Conclusão
Claro que neste artigo muita coisa foi simplificada. Existe um universo bastante vasto sobre Machine Learning, técnicas de IA e tudo mais.
O objetivo principal era só dar um ponta pé inicial e quem sabe você se interesse pelo assunto.
O que você achou deste artigo? Quer ver mais artigos sobre Machine Learning? Me conte nos comentários.
Até mais!
Mestre em Computação Aplicada com foco em Inteligência Artificial, Microsoft MVP, revisor no periódico científico Pattern Recognition Letters, autor de 4 livros pela editora Casa do Código e livros independentes. Entusiasta de programação funcional, IA e do uso de tecnologia como empoderamento das pessoas.



