



Vamos conhecer o Docker Swarm?
No seguinte artigo, o autor apresenta o Docker Swarm, mostra exemplos de uso e fala sobre as vantagens de usar a ferramenta.

Essa história toda de container, compose e agora Swarm, parece um balde de lego, né? Todo dia aparece uma tecnologia nova para resolver alguns problemas que vêm à reboque com esses novos conceitos de ambientes distribuídos. Pensando nisso, hoje decidi falar aqui no portal um pouco mais sobre esse componente da arquitetura de microsserviços da Docker. Vamos lá?
O Docker
Todos sabem o que é Docker, certo? Inclusive aqui no portal tem um monte de artigos e eu também já escrevi um artigo sobre Docker Compose. Dá uma pesquisada, tem artigos bem legais feitos por pessoas mais legais ainda!
Então se acomode na cadeira e vamos embora para um pouco de história!
Como escalar e orquestrar containers?
Usar o docker run e orquestrar serviços usando Compose ajuda muito e torna o processo de trabalhar com containers bastante fácil. Porém, todos os cenários que abordei rodam local “standalone”, ou seja, na nossa máquina ou em apenas em um servidor.
Quando pensamos em escalar os serviços horizontalmente entre várias máquinas, tínhamos problemas (porque, lembre-se, nossos containers são isolados e um container não enxerga o processo do outro) e os hosts também precisam se falar por meio da rede. Até 2015 a Docker não tinha uma solução para esse problema.
E aí nasceu o Kubernetes! Que será tema do meu próximo artigo.

Falando um pouco de Kubernetes, a ferramenta ganhou muito espaço por ter sido criada pela Google e escrita em GO, linguagem que cresceu rapidamente e passou a ser bastante usada, também criação da Google.
A Google já usava o Kubernetes há bastante tempo para escalar seus diversos serviços em vários cluster e data centers ao redor do mundo usando containers, mas nessa época ela se chamava Borg. Serviços da Google como o Gmail e Google Docs, por exemplo, já eram disponibilizados pela companhia em containers e escalados usando essa abordagem em cluster.
Em 2015, a Google resolveu compartilhar isso com o mundo, liberaram o código fonte (agora é Opensource!) e deu o nome novo de Kubernetes, que passou, então, a ser mantida e atualizada pela comunidade. Nesse meio tempo, a ferramenta ganhou bastante força e maturidade e virou ponto chave para escalar serviços em várias máquinas, os famosos clusters minions – nós do cluster. Um case legal do Kubernetes é o do Pokemon Go se você tiver curiosidade.
Calma, esse artigo ainda não é o de Kubernetes, só uma prévia.
Contei tudo isso para dizer que até 2015/2016, a própria Docker aconselhava a usar o Kubernetes ou Apache Mesos para criação de cluster para containers. Até então atendeu bem ao propósito, e ainda está bastante forte no mercado, mas em meados de 2016 a Docker criou sua própria ferramenta para isso.
Olá Swarm!
A ferramenta para cluster da Docker é a Swarm, que já existia como uma ferramenta à parte, mas a partir da versão 1.12 passou a ser nativa, ou seja, só atualizar o seu Docker e habilitar o swarm mode se você quiser usar.
Aproveitando, é bom avisar que em 2017 a Docker lançou a versão EE Enterprise Edition e mudou o ciclo de versionamento do Docker. Agora, são duas versões: CE Community Edition e a Enterprise Edition EE, com números de versões baseados no ano e mês de lançamento. Por exemplo: a versão 17.03, a primeira mais estável, foi lançada em março de 2017. O que se manteve com o mesmo ciclo foi a versão da API do Docker Engine.
Voltando
Para inicializar o cluster a partir da versão 1.12, basta apenas um comando: docker swarm init. É isso mesmo, senhoras e senhores! Um comando e inicializamos o cluster.

O que o Swarm resolve?
A partir do nosso master podemos adicionar hosts Docker, ou seja, máquinas rodando Docker para o nosso cluster. Isso facilita no deploy e na gerência dos serviços e tira a responsabilidade do Sysadmin sobre onde vai fazer o deploy dos containers. O Swarm abstrai essa parte, tomando para ele a responsabilidade de escolher os locais onde alocará os containers nos nós do cluster.

Agora chega de contar história. Vamos trabalhar!
Usaremos nosso famoso PWD (Play With Docker) ou, se preferir, pode usar o Virtualbox, AWS, Azure ou qualquer outra ferramenta. Basta ter no mínimo 3 VMs (dois managers, um worker) para simular nosso cluster. Vou seguir com PWD, afinal, tudo vai ser Docker e vai funcionar em qualquer máquina!
Agora relaxa e vamos com o tio aqui!
Para criar o ambiente é só entrar neste link. Assim que lançar sua primeira instância, usamos o Swarm para criar o cluster. Existe outra forma do PWD criar as instâncias, usando os templates. Para isso, basta clicar no ícone da chave de ferramenta.
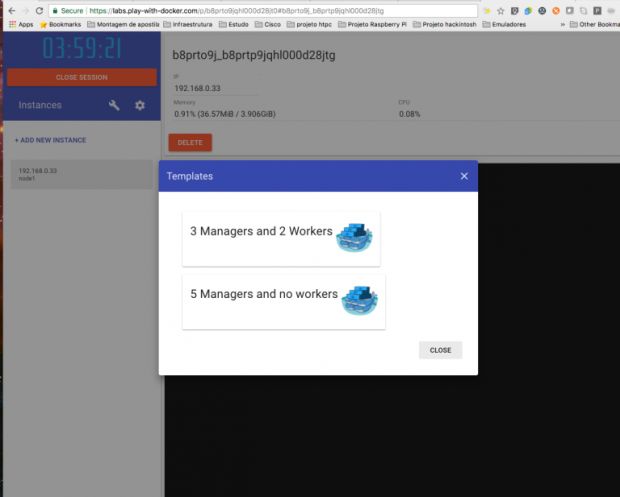
Esse recurso é legal para a galera que já sabe interagir com o Swarm e não quer perder tempo criando o cluster. No nosso caso, vamos usar o modelo tradicional, ok?
Vamos adicionar a primeira instância. A primeira máquina será o manager do Swarm, e precisamos definir e dizer ao Swarm, no momento da incialização do cluster, qual será a interface de rede que será usada quando existir mais de uma interface na máquina.
O comando para inicializar o cluster é este:
docker swarm init --advertise-addr “ip_da_instância”
A saída do comando:
docker swarm join --token SWMTKN-1-2164xvum9q3v5v5x741qq66c3vp19q39siqy53eaxe1iopijes-61yhjqnxmerejd0mpon6o6u9t 192.168.0.33:2377
Esse token vai adicionar um worker ao cluster. Copie e cole esse comando e adicione uma nova instância no PWD.
Observação: este é só um exemplo, quando executar na sua máquina será outro token e rede, fique ligado(a)!
No terminal, cole o comando acima. O terminal vai retornar com a saída “This node joined a swarm as a worker”.
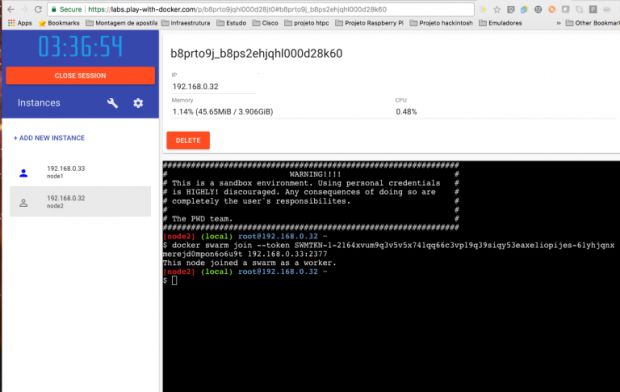
Para adicionar mais Workers ao nosso cluster, é só executar o mesmo procedimento.
Para criar uma redundância para o manager (recomendado) devemos ter uma redundância para garantir a saúde do cluster e dos serviços que estão rodando, temos que criar outro manager. O ideal são três managers ou mais para gerenciar todo o cluster de maneira aceitável em produção, mas para esse exemplo vamos seguir com dois managers.
O comando para pegar o Token para adicionar outro manager, é:
docker swarm join-token manager
O comando acima vai retornar um token para adicionar um manager, e esse token é diferente do que é usado no worker. #ficaadica
Saída do comando:
docker swarm join --token SWMTKN-1-2164xvum9q3v5v5x741qq66c3vp19q39siqy53eaxe1iopijes-0pm316s21bb0rv7g0fxe6p28o 192.168.0.33:2377
Adicione outra instância no PWD e copie e cole o comando gerado no seu terminal (vai ser semelhante ao comando acima), e a saída do comando será essa: This node joined a swarm as a manager.
Resumindo
O comando informa que um manager foi adicionado no cluster do Swarm. Se você quiser adicionar um worker no cluster e não tem o token, pegue novamente rodando o comando com worker no final:
docker swarm join-token worker
Esse comando deve retornar o token já com o comando que conhecemos. É só repetir os procedimentos já executados para adicionar um worker.
Feito tudo isso
Vamos então ver como está o nosso cluster, lembrando que os comandos do Swarm para gerenciar o cluster só funcionam nos nós que são managers (gerentes). Ou seja, todos os comandos como service e stack do Docker só vão funcionar nos managers. #maisumadica
Para listar todos os nós do cluster:
docker node ls

Reparem que na última coluna é possível saber quais nós são managers, e quando não tiver nenhuma informação na coluna MANAGE, é por que aquele nó é um worker, beleza? Então vamos seguir.
O node1 é o Leader do cluster, responsável por manter o estado dos serviços (containers). A definição de serviços do Docker nada mais é que vários containers atendendo um serviço.
Exemplo: o serviço do Nginx, no qual vários containers (espalhados pelo cluster) rodam e podem atender minhas requisições gerando alta disponibilidade.
Outra função do Manager é gerenciar segredos e descoberta de serviços dentro do cluster.
Caso esse nó (manager) venha a falhar, o outro manager (node3, neste exemplo) vai assumir a responsabilidade de gerenciar os serviços. Se existirem containers que estavam rodando nesse nó que ficou fora o manager vai subi-los para outro nó que esteja disponível.
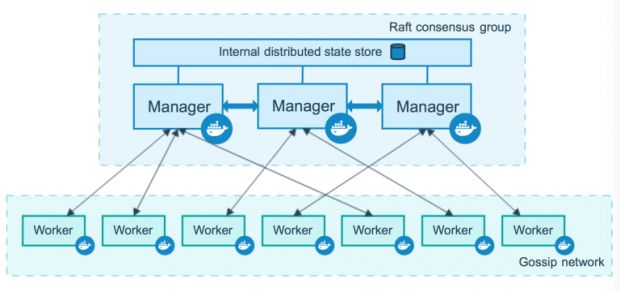
Por debaixo do capô do Swarm existe o Raft como algoritmo de consenso. Ele consegue fazer toda a gerência de quais nós estão disponíveis para rodar a carga de trabalho. Para mais detalhes e entender como Raft funciona, dá uma olhada neste link.
Depois de provisionar nossa infra no PWD com as instâncias criadas e o cluster funcionando, podemos agora fazer o deploy dos nossos serviços.
Primeiramente vamos instalar o UCP (Universal Control Plane), também da Docker, que nada mais é que um Dashboard no qual é possível interagir com a API do Docker de forma visual, e também é um container. Para saber mais do UCP é só clicar aqui.
Para seguir, você precisa baixar/clonar meu projeto que está no Github. Lembrando que precisamos estar no manager, o ideal é que os comandos sejam executados no node1.
Para clonar o repositório do Github:
git clone https://github.com/concrete-cristian-trucco/artigo-swarm-nginx.git
Depois de clonar, entre na pasta:
cd docker-git-nginx/
Com o comando ls -la vamos listar o conteúdo da pasta:
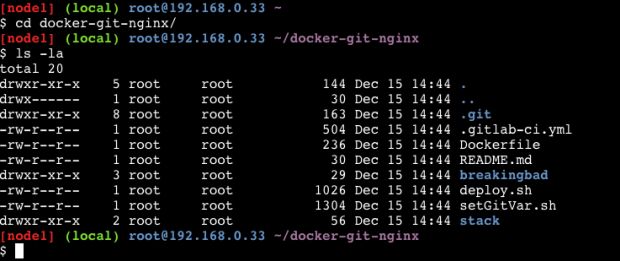
O comando stack do Docker é responsável por subir todos os serviços que vou usar para rodar o UCP. Se você quiser mais informações, só clicar aqui.
O arquivo stack.yml
version: '3.1'
services:
ucp-installer:
image: alpine
command: docker run --rm --name ucp -v /var/run/docker.sock:/var/run/docker.sock docker/ucp:2.2.2 install --force-insecure-tcp --san *.${PWD_HOST_FQDN} --admin-username admin --admin-password admin1234
volumes:
- /var/run/docker.sock:/var/run/docker.sock
- /usr/local/bin/docker:/usr/local/bin/docker
deploy:
restart_policy:
condition: 'none'
Minha stack vai disparar a instalação e todos os comandos necessários para rodar o UCP no meu cluster. Agora, vamos entrar no diretório da stack do UCP.
cd stack/
Agora vamos rodar nossa stack para instalar o Docker UCP. Antes disso, porém, vou explicar o comando: estamos passando a flag -c que indica o caminho do arquivo yml, e o final ucp é o nome da stack. Coloquei “ucp” para facilitar a identificação do que essa stack faz, beleza?
Para rodar no terminal do manager – node1:
docker stack deploy -c stack.yml ucp
Depois de rodar o comando, podemos ver no dashboard do PWD uma série de containers e portas aparecendo. A visualização é melhor com o comando docker ps no terminal.
Esses containers foram todos criados com o comando stack e replicados para o cluster, e todo meu cluster onde os nós forem manager existirá um serviço do UCP. Com isso, ganho alta disponibilidade para gerenciar minhas aplicações através de interface gráfica do UCP.
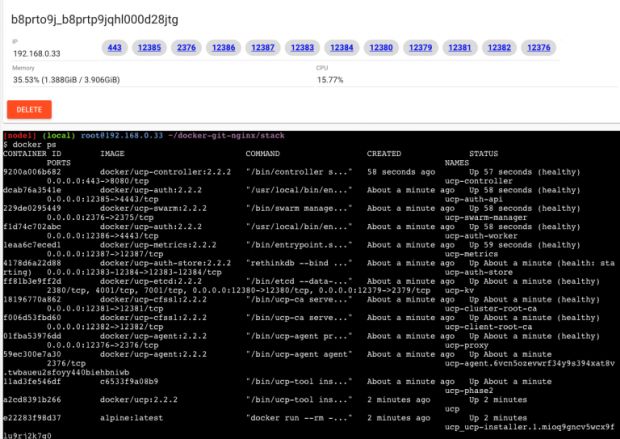
Acessando a porta 443 do cluster ou simplesmente clicando na porta 443 que está sendo exibida no painel do PWD nós vamos chegar ao painel do UCP.
Observação: Pode acontecer de o PWD não redirecionar corretamente de http para o https, no qual o UCP roda. Se isso acontecer (clicar no botão 443 do painel e não redirecionar a página para o dashboard do UCP), clique com o botão direito, copie o link http e acrescente o https. Depois disso, clique em confiar no site, pois não temos certificado configurado. A tela que vai aparecer é essa:
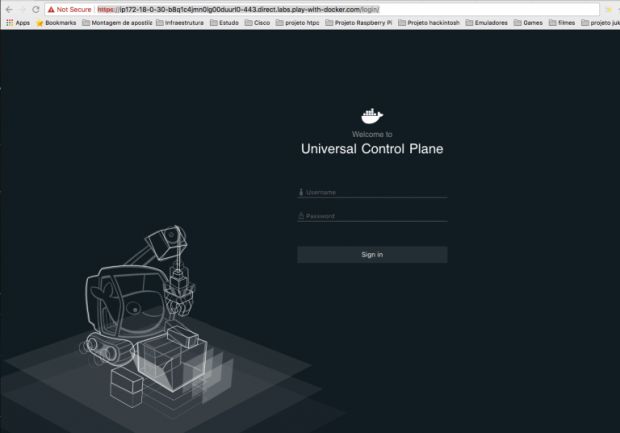
O login e senha foi definido na stack.yml. Se você não lembra, dá uma olhadinha no arquivo! Está nesta linha:
[--admin-username admin --admin-password admin1234]
usuário: admin
senha: admin1234
Depois de logar, a segunda tela vai perguntar se deseja inserir a licença do UCP. Nessa mesma tela tem um link para gerar a licença de trial do UCP no site da Docker (30 dias) ou Skip for now para configurar outra hora. Vou pular esse passo e deixar essa tarefa para você, ok?
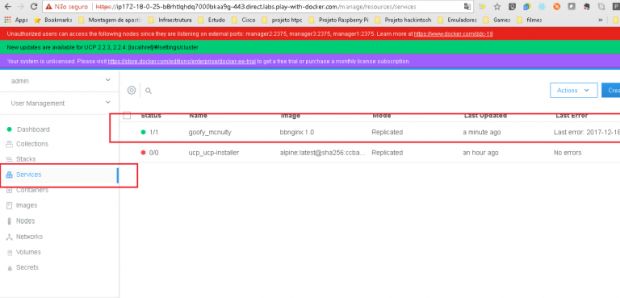
Docker UCP rodando!
Assim que logar, o UCP vai nos dar toda a infraestrutura do nosso cluster de forma visual: o que estamos rodando, quais serviços estão configurados, qual é a quantidade de nós (tanto managers como workers), containers rodando, volumes, redes, enfim! Tudo o que podemos fazer com linha de comando Docker é possível fazer com o UCP.
Basicamente, o UCP consegue fazer isso porque na nossa stack mapeamos o sock do Docker para dentro do Container do UCP. (/var/run/docker.sock:/var/run/docker.sock). Então, tudo o que acontece no Docker é refletido automaticamente.
Lembrando que o Swarm basicamente são vários Dockers engines apontando para o Swarm Master, o que transforma toda essa infra em um pool de recursos para deploy de containers Docker. Nossa stack foi instalada em todo o cluster, então o UCP tem a visão completa.
Não vou explicar muito o UCP, vamos deixar a sua curiosidade explorar isso. O foco é o swarm, stack e service.
Então vamos voltar para o repositório que clonamos e para a raiz do projeto, onde tem o Dockerfile.
Vamos criar um serviço que vai rodar o Nginx e disponibilizar uma página simples em HTML.
Primeiro precisamos fazer o build da imagem que será usada para o nosso serviço. Lembrando que o build precisa ser executado no diretório do Dockerfile, o mesmo nó no qual executamos o git clone, que é o node1.
docker build -t bbnginx:1.0 .
A imagem será buildada e já podemos criar nosso serviço, com este comando:
docker service create --publish 80:80 bbnginx:1.0
O comando é bem simples, só usar create para criar o serviço e informar para meu cluster que essa aplicação roda na porta 80.
A saída do comando vai dar essa mensagem, pois não temos um Registry (repositório para guardar e centralizar as imagens Docker). No nosso cenário, cada nó precisa ter essa imagem buildada. Não é uma boa prática, torna o processo complexo e pouco gerenciável.
image bbnginx:1.0 could not be accessed on a registry to record its digest. Each node will access bbnginx:1.0 independently, possibly leading to different nodes running different versions of the image. 6nklw2p5hdapw6qfzn9httdpp Since --detach=false was not specified, tasks will be created in the background. In a future release, --detach=false will become the default.
Mas o serviço é criado no node1, podemos ver isso executando o comando:
docker service ls
Ou olhando na guia de serviços do UCP, no lado esquerdo. Lá podemos ver os serviços que estão rodando no Docker.
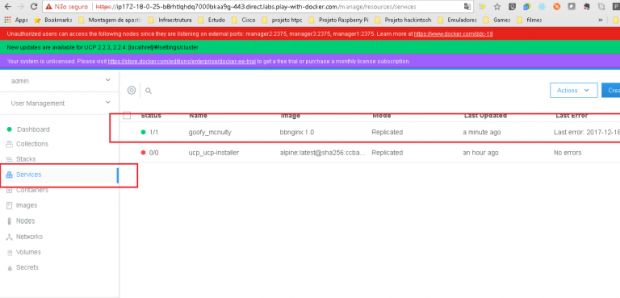
Podemos ver o serviço criado e a quantidade de réplicas, que nesse primeiro momento é 1.
Agora, antes de replicar esse serviço, precisamos resolver o problema do Registry. Vou fazer o build, gerar uma imagem e enviar para o Docker hub, criando meu serviço novamente usando o Registry público da Docker.
Primeiro vamos remover o serviço que criamos pelo painel do UCP, na guia Services. Clique no serviço e depois nos botões Actions e Remove. Aí é só confirmar e pronto! Serviço removido.
Esse procedimento também pode ser feito por linha de comando, usando docker service ls para listar os serviços e docker service rm para remover o serviço, passando o serviço que deseja remover.
Vamos buildar a imagem novamente e fazer o push para o Docker hub, criando o serviço novamente com essa nova imagem.
Observação: Esse procedimento de build e push não precisa ser executado, podemos usar direto a última linha para criar o serviço. O Docker vai baixar a imagem que está no Dockerhub: “concretecristiantrucco/artigo-swarm-nginx:latest”.
er build -t concretecristiantrucco/artigo-swarm-nginx . docker push concretecristiantrucco/artigo-swarm-nginx:latest docker service create --publish 80:80 --name "bbnginx" concretecristiantrucco/artigo-swarm-nginx:latest
Criamos o serviço! Mas, como é possível ver na imagem, só temos um container rodando. Isso não faz muito sentido porque quero alta disponibilidade, certo?
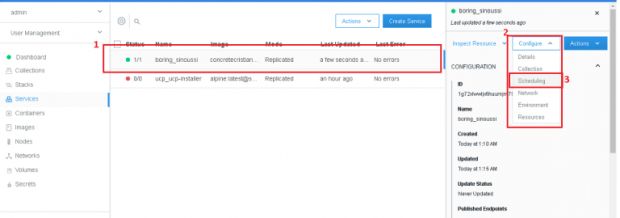
Ao clicar em cima do serviço e depois em configure e scheduling, podemos alterar esse comportamento, aumentando a quantidade de réplicas. Em scale, mude para 3 e depois clique no botão update.
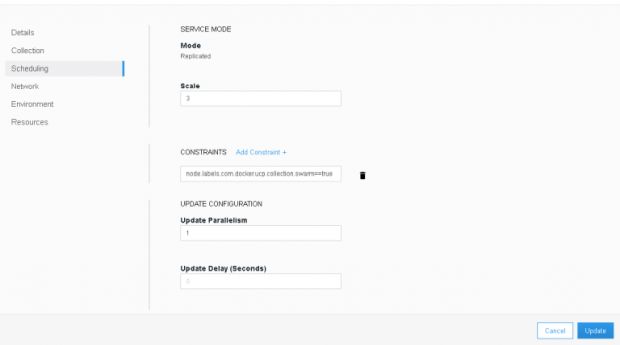
Resumindo: coloquei três containers para atender meu serviço do Nginx para minha página web.
![]()
É só clicar em Containers para ver onde cada container de réplica de serviço está rodando, na coluna Node.
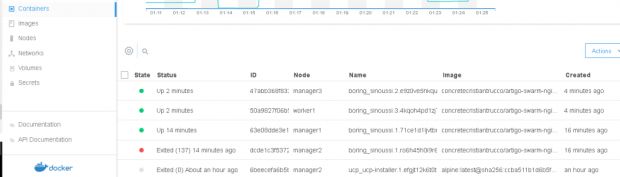
Voltando para o PWD vamos verificar se nosso serviço está rodando na porta 80. Vimos pelo painel do UCP que tem uma réplica rodando no manager1/node1, então acessando o dashboard do manager e clicando na porta 80, o PWD será redirecionado para nosso site com Nginx.
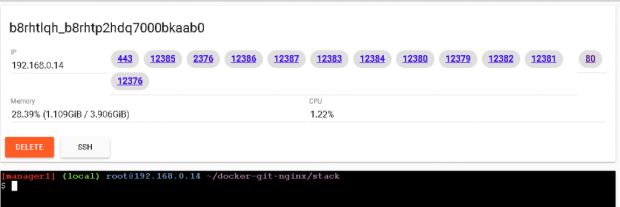
Pronto! Temos um serviço de Nginx rodando e exibindo nossa página.

Na primeira tag é possível ver o ID do container que está processando nossa página.

Conclusão
O Swarm agiliza (em muito) o tempo de deploy, com o stack e service. Transferimos a responsabilidade de alocar os serviços para o Swarm, e ele decide em quais nós vai rodar os containers. Com isso, garantimos alta disponibilidade dos serviços que estão rodando no cluster.
Com o Docker UCP temos uma visão completa da infraestrutura de containers de forma visual. O que facilita muito no trabalho de monitoramento e gerenciamento, visibilidade dos serviços que estão rodando (métricas, estados e quantidades de containers atendendo aos serviços) e por fim deixam a gerência mais simples para as equipes de desenvolvimento e operações, o que faz todo sentido para a galera de DevOps.
Ficou alguma dúvida ou tem alguma coisa a dizer? Aproveite os campos abaixo. Até a próxima!
***
Este artigo foi publicado originalmente em: https://www.concrete.com.br/2018/02/06/vamos-conhecer-o-docker-swarm/
DevOps na Concrete, estudou Analise e Desenvolvimento Sistemas, usando containers e tentando automatizar quase tudo com alguns truques! Entusiasta de cloud, marombeiro desde pequeno e jogador profissional de Street Fighter 5 nas horas vagas.



