



Tudo o que você precisa saber sobre o Kubernetes – Parte 02
No seguinte artigo, o autor apresenta a segunda parte da série de artigos sobre Kubernetes. Dessa vez, traz a parte prática do sistema.


Voltei! Agora para botar a mão na massa e entender de vez o que é o Kubernetes. Preparado? Caso não esteja, dê uma olhada na primeira parte desta série, na qual faço uma longa introdução sobre o assunto: o que é, como usar, quais são os principais termos, etc. A teoria está toda lá, ok? Hoje, a parte prática. Vamos lá!
Apesar de já ter explicado no primeiro artigo a arquitetura do cluster e ter mostrado a estrutura necessária para compor o Master e os Minions, passando pelos componentes que compõem essa arquitetura, vamos usar o Minikube como ponto de partida.
Em breve vamos falar mais aqui no portal sobre a criação do cluster passando pelo setup e configuração e usando os conceitos que foram explicados.

Neste repositório (artigo-kubernetes) tem tudo o precisaremos para rodar nossa primeira aplicação.
Antes de começar
- Certifique-se de ter o VirtualBox instalado;
- Baixe o Minikube para a versão do seu SO;
- E o Kubectl para poder administrar nosso cluster, que no nosso caso é o Minikube.
- Tudo instalado? Então vamos trabalhar!
- No terminal, vamos subir o Minikube:
minikube start
A saída vai ser semelhante à imagem abaixo. O comando vai baixar a ISO e subir uma VM no Virtualbox. Não vamos precisar interagir com o Virtualbox e nem mesmo abrir para o Minikube funcionar. Se quiser conferir a VM rodando, abra o Virtualbox e lá vai estar uma VM com nome de Minikube e o status running.
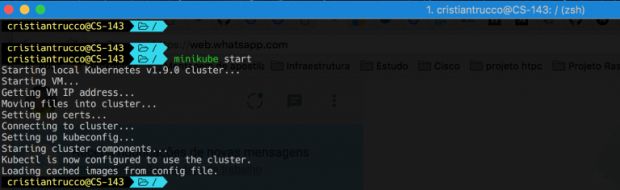
O próximo comando vai listar os nossos nós e usar o kubectl para isso. Lembra que falei que íamos usar esse carinha para interagir com o cluster? Então, agora ele vai ser um dos nossos melhores amigos!
kubectl get nodes <img class="aligncenter size-full wp-image-126737" src="https://static.imasters.com.br/wp-content/uploads/2018/03/TRES.jpg" alt="" width="620" height="125" />
Se tudo ocorreu bem vamos ver o Minikube com status “Ready”, ou seja, está pronto para receber solicitações. Esse comando serve para listar todos os nós do cluster, e como só temos uma VM rodando, só vai aparecer ela aqui.
Ah, faltou clonar nosso repositório que vamos usar para subir o serviço.
git clone https://github.com/concrete-cristian-trucco/kubernetes-basico-nginx.git

Agora vamos entrar no diretório que acabamos de clonar do Git (kubernetes-basico-nginx), como na imagem:
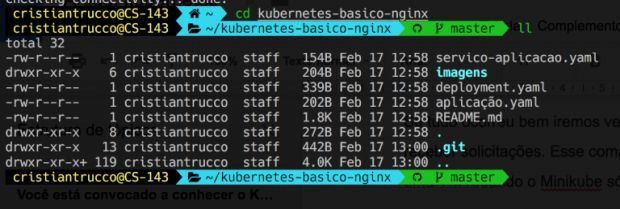
Listei os arquivos desse repositório. Como podem ver, tem três arquivos YAML, que vamos usar para criar os objetos no Kubernetes. Lá, tudo o que declaramos no campo “Kind” no arquivo Yaml, chamamos de objetos. À título de curiosidade, vamos criar um objeto do tipo Pod, mas antes, vamos abrir o arquivo aplicação.yaml para entender o que esse arquivo está fazendo.
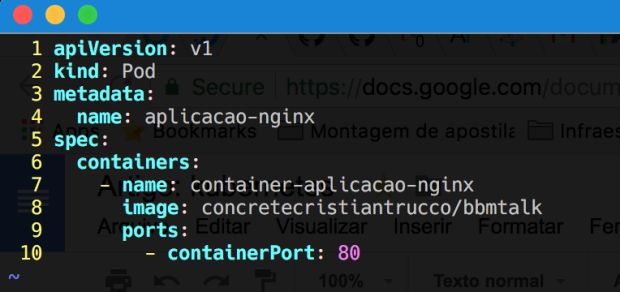
Primeiro especificamos qual API iremos usar, e depois dizemos que tipo de objeto estamos declarando com “kind”. Em seguida, vamos usar um nome para nosso objeto em “metadata” e no “spec” vamos especificar qual é o objeto que o Pod está abstraindo, que neste caso é nosso container de Nginx. Nessa parte informamos o nome e a imagem que o container vai usar e a porta que esse container vai responder, a porta “80”.
Antes de criar o Pod, vamos ver se não tem nenhum Pod rodando no nosso cluster.
kubectl get pods
Esse comando vai listar todos os objetos do tipo Pod no nosso cluster, e como ainda não criamos nada ainda, a resposta será: No resources found.
Agora vamos criar o Pod contendo nossa aplicação Nginx. No diretório no qual temos nossos arquivos yaml, digite o comando:
kubectl create -f aplicação.yaml

O comando é bem tranquilo e fácil de entender. Basicamente estamos informando ao cluster com o kubectl que queremos criar um objeto “create” passando a flag “f” de file/arquivo e o caminho do nosso arquivo, que aqui no nosso exemplo está no mesmo diretório. Então, só informamos o nome do arquivo: “aplicação.yaml”. A saída do comando informa que o objeto foi criado, como é possível ver na imagem acima.
Agora, quando usamos o comando “kubectl get pods”, podemos ver o objeto criado.
kubectl get pods

Legal, mas temos um problema! Como acessamos esse container?
A resposta é: não acessamos! Até existe um jeito de acessar esse Pod mas não é uma boa prática, pois não expomos um único objeto Pod no cluster, até porque Pods são efêmeros e morrem o tempo todo, então não faz sentido ter esses objetos inconsistentes e com pouca gerência expostos no cluster. Isso sem contar que se esse Pod morrer, não sobe outro no lugar dele. Para resolver esses problemas temos dois outros objetos, o Deployments e o Services.
Então vamos excluir esse Pod. O comando é semelhante a criar um objeto, a diferença é que ao invés de passar “create”, usamos o “delete”.
kubectl delete -f aplicação.yaml

Pronto! Objeto excluído do nosso cluster.
Agora vamos abrir o nosso arquivo deployment.yaml.
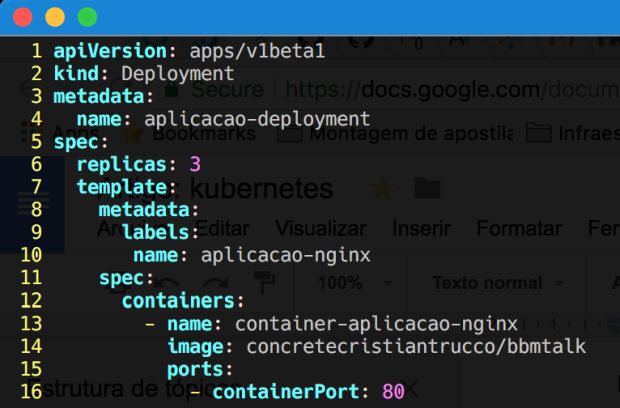
Nesse arquivo informamos o tipo, que é um objeto Deployment.
Deployments servem para dizer ao cluster o estado desejado de um objeto a ser implantado. Estou informando que quero subir três réplicas da minha aplicação Nginx no cluster e que esse estado seja mantido caso um Pod morra e fique apenas dois no cluster.
Neste caso, o Kube vai subir o terceiro Pod, mantendo assim o estado desejado. No final do arquivo, dissemos qual é o tipo de objeto que estamos abstraindo, que no nosso exemplo vai ser o Pod criado no início do nosso lab, passando o nome, a imagem e a porta que vai usar.
O comando será semelhante ao que já conhecemos:
kubectl create -f deployment.yaml

E pronto!
Vamos olhar quantos Pods o Deployment criou? Como fazemos para listar os Pods, mesmo? Só usar o comando:
kubectl get pods
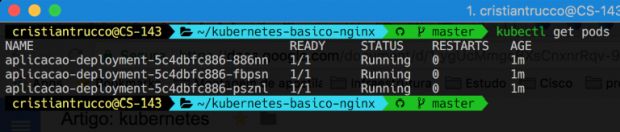
E podemos ver nossos três Pods criados lá! Legal, né? Se caso um desses Pods morrer, o nosso cluster vai tratar de subir outro. Se quiser, faça os testes! Nos exemplos acima dá pra ver como excluímos um Pod. Vou deixar para você testar isso, tudo bem?
Também podemos listar os nossos Deployments criados no cluster.
kubectl get deployment

Podemos observar quantos Pods então rodando, quantos estão disponíveis e o tempo de vida desse objeto.
Mas ainda não chegamos onde queremos. Temos os três Pods, garantimos a disponibilidade do nosso serviço, mas ainda falta acessar de fato esses Pods. No caso, nossa aplicação.
Para resolver isso vamos usar o Service. Ele será o End Point dos nossos Pods, vai abstraí-los e engloba-los. É um objeto do tipo service, também funciona como um balanceador de carga para nossa aplicação.
Vamos abrir o nosso arquivo “servico-aplicacao.yaml“.
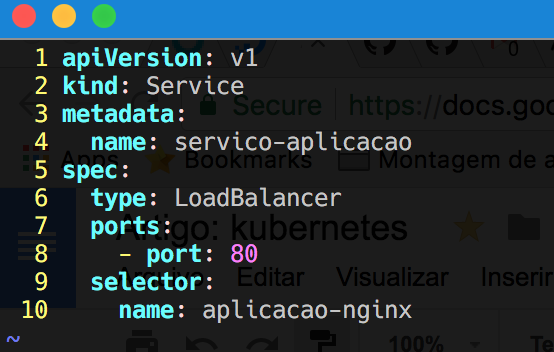
Esse arquivo também é bem tranquilo de entender. Aqui informamos o tipo de objeto, como já aprendemos, que será o Service, passamos o nome desse serviço; o tipo que será o nosso LoadBalancer; a porta dos Pods, que é a 80, e no selector dizemos qual é o objeto que vamos para o service, que é o aplicacao-nginx.
Observação: o nome tem que ser o mesmo que foi usado no nosso exemplo do Deployments.
Então, como já estamos safos, vamos criar esse objeto com o kubectl no cluster.
kubectl create -f servico-aplicacao.yaml

Bom, vamos conferir se está tudo ok? Como já sabemos listar os objetos no cluster e queremos listar o objeto Service, fica fácil de entender como interagir com o cluster.
kubectl get service

Como não especifiquei nenhuma porta no meu arquivo “servico-aplicacao.yaml“, o Kubernetes atribui uma porta aleatoriamente para o nosso serviço. Que, como podemos ver na imagem, é 30848.
Observação: pode ser que quando rodar na sua máquina a porta seja outra. Colocar a porta desejada no arquivo do service é um desafio que vou deixar aqui. Bem tranquilo de fazer.
E agora, como acessamos? Como fazemos para pegar a URL e acessar nossa aplicação? Tem dois jeitos. Ou perguntando para o Minikube:
minikube service servico-aplicacao --url

Ou pelo IP da nossa VM do Minikube, passando a porta que foi listada com o comando kubectl get services, que nada mais é o que esse comando acima faz.
minikube status

Ao colocar o endereço no nosso navegador, usando o IP e a porta que já pegamos com os comandos acima, podemos acessar de fato nossa aplicação:

E está aí nossa aplicação funcionando! Se abrir outra aba você pode ver que vamos cair provavelmente em outra instância, pois estamos usando o Service LoadBalancer.
Usei a mesma imagem que está no Docker Hub e que foi utilizada no exemplo do artigo sobre Docker Swarm, que publiquei há algumas semanas aqui no portal, para mostrar que podemos atingir o mesmo objetivo com ambos orquestradores de cluster. Essa também é uma aplicação simples e leve de reproduzir por ser stateless.
O último comando para mostrar é acessar o Kubernetes pela parte gráfica. Como estamos rodando com o Minikube, basta executar:
minikube dashboard
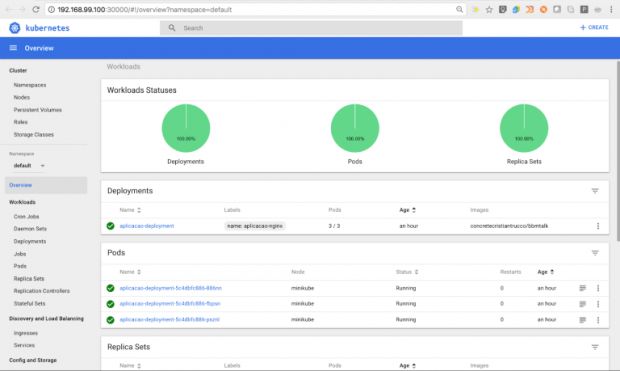
Como podemos ver, o comando vai abrir o navegador automaticamente e podemos acessar a interface gráfica do nosso cluster. Conseguimos gerenciar nossos objetos criados por meio dessa interface, assim como fazemos com o kubectl. O Kubernetes exibe uma monitoria dos serviços que estão rodando no nosso cluster. Não vou focar nessa parte. Você, marujo, pode explorar. Dei apenas o mapa do tesouro, agora cabe a você achá-lo!
Conclusão
O Kubernetes é muito mais do que isso, tanto na parte de configuração quanto na implementação. No repositório do GitHub tem mais detalhes e exemplos dos comandos usados aqui, depois dá uma conferida lá! Tentei reduzir essa série para deixar o mais claro possível, com exemplos práticos, como usar a ferramenta. Se ainda ficou alguma dúvida ou tem algo a dizer, aproveite os campos abaixo. Até a próxima!
Algumas referências, se você quiser saber mais:
- Minikube: https://kubernetes.io/docs/getting-started-guides/minikube/
- Kubernetes: https://kubernetes.io/
- Kubernetes GitHub: https://github.com/kubernetes/kubernetes
***
Este artigo foi publicado originalmente em: https://www.concrete.com.br/2018/02/23/tudo-o-que-voce-precisa-saber-sobre-kubernetes-parte-2/
DevOps na Concrete, estudou Analise e Desenvolvimento Sistemas, usando containers e tentando automatizar quase tudo com alguns truques! Entusiasta de cloud, marombeiro desde pequeno e jogador profissional de Street Fighter 5 nas horas vagas.



