

A ideia de que o TDD danifica o projeto e a arquitetura não é nova. DHH sugeriu, há vários anos, com sua noção de Test Induced Design Damage, em que ele compara o projeto que ele prefere com um projeto criado por Jim Weirich que é “testável”. O argumento se resume a separação e indireção. O conceito do DHH de bom projeto minimiza esses atributos, enquanto o de Weirich os maximiza.
Peço-lhe insistentemente que leia o artigo de DHH e assista ao vídeo de Weirich, e julgue por si mesmo qual projeto você prefere.
Recentemente, tenho visto o argumento ressurgir no Twitter, embora não em referência às ideias de DHH, mas em referência a uma entrevista muito antiga entre James Coplien e eu. Nesse caso, o argumento é sobre o uso do TDD para permitir que a arquitetura surja. Como você irá descobrir, se você ler essa entrevista, Cope e eu concordamos que a arquitetura não surge do TDD. O termo que eu usei, nessa entrevista foi, acredito eu – merda de cavalo.
Outro argumento comum é o de que à medida que o número de testes cresce, uma única alteração no código de produção pode fazer com que centenas de testes exijam mudanças correspondentes. Por exemplo, se você adicionar um argumento a um método, cada teste que chame esse método deve ser alterado para adicionar o novo argumento. Isso é conhecido como The Fragile Test Problem.
Um argumento relacionado é: quanto mais testes você tiver, mais difícil será alterar o código de produção, porque tantos testes podem quebrar e exigir reparo. Assim, os testes tornam o código de produção rígido.
O que há por trás disso?
Há alguma coisa com essas preocupações? Elas são reais? O TDD realmente danifica o projeto e a arquitetura?
Há muitas questões para simplesmente ignorar. Então, o que está acontecendo aqui?
Antes de eu responder a isso, vejamos um diagrama simples. Qual destes dois projetos é melhor?
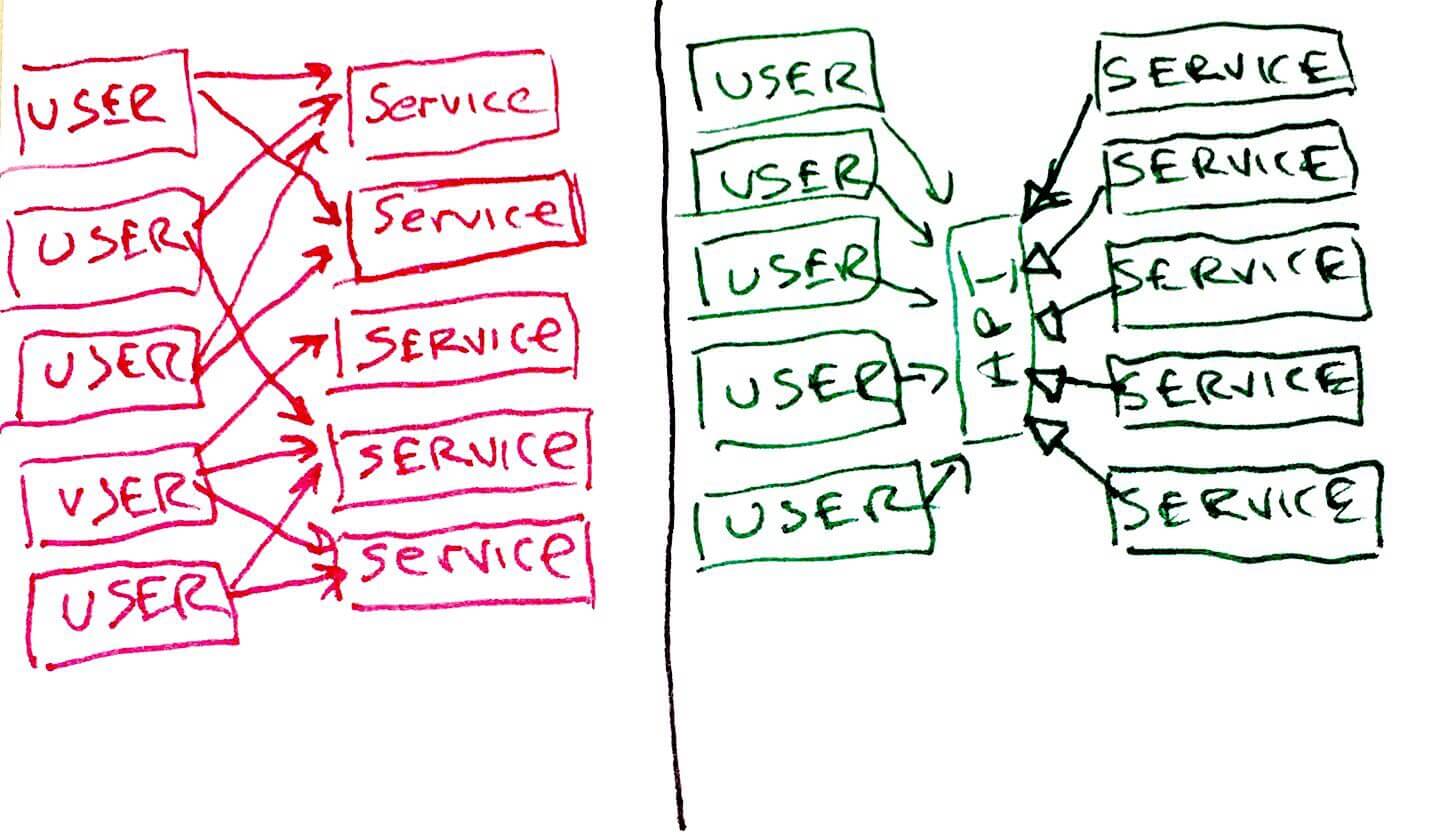
Sim, é verdade, eu lhe dei uma dica ao colorir o lado esquerdo (sinistro) de vermelho e o lado direito (dexter) de verde. Espero que esteja claro que a solução da mão direita é geralmente melhor do que a esquerda.
Por quê? Acoplamento, é claro. Na solução à esquerda os usuários estão diretamente acoplados a uma infinidade de serviços. Qualquer mudança em um serviço, independentemente do quão trivial ele seja, provavelmente fará com que muitos usuários exijam mudanças. Assim, o lado esquerdo é frágil.
Pior, os usuários do lado esquerdo atuam como âncoras que impedem a capacidade dos desenvolvedores para fazer alterações nos serviços. Os desenvolvedores temem que muitos usuários possam ser afetados por mudanças simples. Assim, o lado esquerdo é rígido.
O lado direito, por outro lado, desacopla os usuários dos serviços usando uma API. Além do mais, os serviços implementam a API usando herança ou alguma outra forma de polimorfismo (esse é o significado das setas triangulares fechadas – um UMLism). Assim, um grande número de mudanças pode ser feito nos serviços sem afetar a API ou os usuários. Além do mais, os usuários não são uma âncora tornando os serviços rígidos.
Os princípios em jogo aqui são o Open-Closed Principle e o Dependency Inversion Principle (DIP).
Observe que o projeto à esquerda é o projeto que DHH estava defendendo em seu artigo, enquanto o projeto à direita foi o tema da exploração de Weirich. DHH gosta da direcionalidade do projeto à esquerda. Weirich gosta da separação e isolamento do desenho à direita.
A substituição crítica
Agora, em sua mente, eu quero que você faça uma simples substituição. Olhe para esse diagrama e substitua a palavra “TEST” por “USER”– e então pense.
Sim. Está certo. Testes precisam ser projetados. Princípios de projeto (?) se aplicam aos testes tanto quanto eles se aplicam ao código regular. Os testes são parte do sistema e devem ser mantidos com os mesmos padrões que qualquer outra parte do sistema.
Correspondência um-para-um
Se você vem me seguindo por qualquer período de tempo, sabe que eu descrevo TDD usando três leis. Essas leis obrigam você a escrever seus testes e seu código de produção simultaneamente, virtualmente linha por linha. Uma linha de teste, seguida por uma linha de código de produção, ao redor e ao redor e ao redor. Se você nunca viu ou experimentou isso, você pode querer assistir a este vídeo.
A maioria das pessoas que são novas no TDD, e nas três leis, acabam escrevendo testes que se parecem com o diagrama à esquerda. Elas criam uma espécie de correspondência um-para-um entre o código de produção e o código de teste. Por exemplo, eles podem criar uma classe de teste para cada classe de código de produção. Eles podem criar métodos de teste para cada método de código de produção.
Claro que isso faz sentido, no início. Afinal, o objetivo de qualquer conjunto de testes é testar os elementos do sistema. Por que você não criaria testes que tivessem uma correspondência um-para-um com esses elementos? Por que você não criaria uma classe de teste para cada classe e um conjunto de métodos de teste para cada método? Não seria essa a solução correta?
E, na verdade, a maioria dos livros, artigos e demonstrações de TDD mostram precisamente essa abordagem. Eles mostram testes que têm uma forte correlação estrutural com o sistema que está sendo testado. Assim, naturalmente, os colaboradores que tentam adotar TDD seguirão esse conselho.
O problema é – e eu quero que você pense cuidadosamente sobre esta próxima afirmação – uma correspondência um-para-um implica um acoplamento extremamente apertado.
Pense nisso! Se a estrutura dos testes segue a estrutura do código de produção, então os testes estão inextricavelmente acoplados ao código de produção – e eles seguem o sinistro quadro vermelho à esquerda!
FitNesse
Isso, francamente, levou muitos anos para se perceber. Se você olhar para a estrutura do FitNesse, que começamos a escrever em 2001, você verá uma forte correspondência um-para-um entre as classes de teste e as de código de produção. Na verdade, eu costumava encarar isso como uma vantagem, porque eu poderia encontrar cada teste unitário, simplesmente colocando a palavra “Teste” após a classe que estava sendo testada.
E, naturalmente, nós experimentamos alguns dos problemas que você esperaria com um projeto tão sinistro. Tivemos testes frágeis. Tínhamos estruturas que se tornaram rígidas com os testes. Sentimos a dor do TDD. E, depois de vários anos, começamos a entender que a causa dessa dor era que não estávamos projetando nossos testes para serem desacoplados.
Se você olhar para parte do FitNesse escrito depois de 2008, verá que há uma queda significativa na correspondência um-para-um. Os testes e o código parecem mais com o projeto verde à direita.
Emergência
A ideia de que o projeto e a arquitetura de alto nível de um sistema emergem do TDD é, francamente, absurda. Antes de começar a codificar qualquer projeto de software, você precisa ter alguma visão arquitetônica no lugar. TDD não irá, e não pode fornecer essa visão. Esse não é o papel do TDD.
No entanto, isso não significa que os projetos não surjam de TDD – eles surgem, apenas não nos níveis mais altos. Os projetos que emergem de TDD estão um ou dois passos acima do código, e eles estão intimamente ligados ao código e ao ciclo vermelho-verde-refator.
Funciona assim: à medida que alguns programadores começam a desenvolver uma nova classe ou módulo, eles começam a escrever testes simples que descrevem os comportamentos mais degenerados. Esses testes verificam os absurdos, como o que o sistema faz quando nenhuma entrada é fornecida. O código de produção que resolve esses testes é trivial e gradualmente cresce à medida que mais e mais testes são adicionados.
Em algum momento, relativamente cedo no processo, os programadores olham para o código de produção e decidem que a estrutura é um pouco confusa. Assim, os programadores extraem alguns métodos, renomeiam outros e geralmente limpam as coisas. Essa atividade terá pouco ou nenhum efeito nos testes. Os testes ainda estão testando todo esse código, independentemente do fato de que a estrutura desse código esteja mudando.
Esse processo continua. À medida que testes de complexidade e restrição cada vez maiores são adicionados ao conjunto, o código de produção continua a crescer em resposta. De vez em quando, relativamente frequentemente, os programadores limpam esse código de produção. Eles podem extrair novas classes. Eles podem até mesmo retirar novos módulos. E ainda assim os testes permanecem inalterados. Os testes ainda cobrem o código de produção, mas eles não têm mais uma estrutura semelhante.
E para preencher a estrutura diferente entre os testes e o código de produção, uma API surge. Essa API serve para permitir que os dois fluxos de código evoluam em direções muito diferentes, respondendo às forças opostas que pressionam testes e código de produção.
Forças em oposição
Eu disse acima que os testes permanecem inalterados durante o processo. Isso não é verdade. Os testes também são refatorados pelos programadores numa base bastante frequente. Mas a direção da refatoração é muito diferente da direção em que o código de produção é refatorado. A diferença pode ser resumida por esta simples afirmação:
À medida que os testes se tornam mais específicos, o código de produção fica mais genérico.
Essa é (para mim) uma das revelações mais importantes sobre TDD nos últimos 16 anos. Esses dois fluxos de código evoluem em direções opostas. Os programadores refatoram testes para se tornarem cada vez mais concretos e específicos. Eles refatoram o código de produção para se tornar cada vez mais abstrato e geral.
Na verdade, é por isso que o TDD funciona. É por isso que os projetos podem emergir do TDD. É por isso que os algoritmos podem ser derivados por TDD. Essas coisas acontecem como um resultado direto de programadores empurrando os testes e código de produção em direções opostas.
É claro que os projetos emergem, se você estiver usando princípios de projeto para empurrar o código de produção para ser cada vez mais genérico. É claro que as APIs emergem se você estiver puxando esses dois fluxos de código de comunicação para extremos opostos de especificidade e generalidade. É claro que os algoritmos podem ser derivados se os testes crescerem cada vez mais restritivos enquanto o código de produção cresce cada vez mais geral.
E, claro, código altamente específico não pode ter uma correspondência um-para-um com código altamente genérico.
Conclusão
O que faz o TDD funcionar? Você faz. Seguir as três leis não fornece nenhuma garantia. As três leis são uma disciplina, não uma solução. É você, o programador, que faz o TDD funcionar. E você o faz funcionar entendendo que os testes são parte do sistema, que os testes devem ser projetados e que o código de teste evolui para uma especificidade cada vez maior, enquanto o código de produção evolui para uma generalidade cada vez maior.
O TDD pode prejudicar o seu projeto e arquitetura? Sim! Se você não empregar princípios de projeto para evoluir seu código de produção, se você não evoluir os testes e o código em direções opostas, se você não tratar os testes como parte de seu sistema, se você não pensar em desacoplamento, separação e isolamento, você danificará seu projeto e arquitetura – com ou sem TDD.
Você vê, não é o TDD que cria maus projetos. Não é o TDD que cria bons projetos. É você. O TDD é uma disciplina. É uma maneira de organizar seu trabalho. É uma maneira de garantir a cobertura do teste. É uma maneira de garantir uma generalidade adequada em resposta à especificidade.
TDD é importante. TDD funciona. TDD é uma disciplina profissional que todos os programadores devem aprender e praticar. Mas não é o TDD que causa bons ou maus projetos. Você faz isso.
São apenas os programadores, não o TDD, que podem prejudicar projetos e arquiteturas.
***
Uncle Bob faz parte do time de colunistas internacionais do iMasters. A tradução do artigo é feita pela redação iMasters, com autorização do autor, e você pode acompanhar o artigo em inglês no link: http://blog.cleancoder.com/uncle-bob/2017/03/03/TDD-Harms-Architecture.html

De 0 a 10, o quanto você recomendaria este artigo para um amigo?