

Git é um sistema de controle de versão reconhecidamente poderoso e flexível para usuário. Entretanto para se ter acesso a todo esse poder ou ao menos parte dele é essencial dominar alguns comandos. Sem um ferramental, mínimo é muito comum sentir-se travado, vítima de sua própria ferramenta. Esse artigo, pretender trazer conceitos e comandos na sua maioria de nível intermediário a um usuário que já tenha uma certa experiência com Git.
Quando trabalha-se no dia a dia com um projeto Git, é muito comum fazer um commit de algumas mudanças mesmo que elas ainda não estejam prontas para um code review ou para serem integradas em uma branch de referência. Por isso, é muito importante que o usuário sinta-se confortável com os comandos capazes de reescrever o histórico no escopo de sua branchde desenvolvimento. Pode ser interessante simplesmente mudar a mensagem de commit ou até mesmo quebrar um commitanterior em vários menores.
Um outro ponto importante deve-se a natureza distribuída de Git em que o desenvolvimento ocorre paralelamente em múltiplas branches, sendo assim é de suma importância saber como combinar os múltiplos commits com toda a flexibilidade possível. Pode ser interessante aplicar os commits de uma branch no topo de outra ou até ir alem ao pegar uma “fatia” de commits de uma branch e aplicá-la em outra.
Essas duas habilidades de reescrever o histórico e rearranjar os commits já trazem uma boa parte do poder de Git ao domínio do usuário. Consequentemente, elas serão tratadas mais a fundo nesse artigo.
Recapitulando conceitos básicos
Nesta seção recapitularemos alguns conceitos e comandos básicos necessário à uma melhor compreensão do restante do artigo. O leitor que sentir-se mais confiante pode optar por ir diretamente à próxima seção.
Com apenas pouco tempo de Git já é possível notar a presença de longas cadeias hexadecimais por toda parte. Essas cadeias são o resultado da função de hash SHA-1 que resulta em 40 casas hexadecimais. Elas são de extrema importância, visto que Git é, em essência, um repositório de objetos em que cada sequência SHA-1 mapeia a um objeto. Como em um dicionário Python, uma hash Perl ou HashMap Java, é esse número que nos leva ao objeto desejado.
Informações e meta-informações do repositório git são em geral armazenadas em objetos no diretorio “.git/objects” (exceto no caso de compactação). Esses objetos podem ser de vários tipos: blobs, trees, commits e tags. Os blobs como em base de dados SQL são capazes de armazenar qualquer tipo de informação como por exemplo o contudo de um arquivo. Já o objeto tree é muito semelhante a um diretório, podendo apontar para globs e recursivamente para outros objetos trees. Os outros dois últimos objetos estão mais relacionados às meta-informações do controle de versão. É sabido que cada commit representa uma foto do estado do repositório. Por isso, cada um deles aponta para um objeto do tipo tree cujas entradas são blobs representando o conteúdo dos arquivos naquele momento ou outros trees representando os diretórios do repositório e assim recursivamente. Por fim, tem-se o objeto tag que permite fazer uma referência a um commit, por exemplo, usando uma stringmais amigável do que o SHA-1.
Como cada um dos objetos vistos anteriormente possui um hash associado fica claro que ele desempenha um papel fundamental no Git, mesmo que nem sempre o manipulamos diretamente. Lidar com um número hexadecimal de 40 dígitos pode não ser muito prático, por isso existe a liberdade de utilizar seus prefixos. Mesmo assim, pode ser mais interessante lidar com uma referência textual. Para cada uma das cabeças de desenvolvimento a funcionalidade de branches desempenha esse papel. Uma branch nada mais é do que um ponteiro para um commit cabeça. Como todo ponteiro que se preze, ele precisa armazenar um endereço, que no caso de Git é o SHA-1. Se inspecionarmos o conteúdo do ponteiro master de um repositório é possível notar a presença do hash. Na nomeclatura de Git denomina-se revisão (rev) um referência arbitrária a um commit, seja por hash, por nome de branch ou qualquer outra forma.
$ cat .git/refs/heads/master c32ca8a9f01ad9436d28e3abfe36808de2e2ec3f
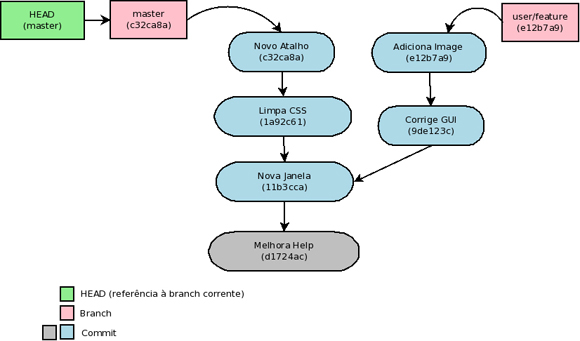
Quando se utiliza o comando “git branch <nova_branch>” ou algum outro que crie uma nova branch, o que ocorre na realidade é uma simples criação de ponteiro em geral para último commit da branch corrente. Como cada commit guarda consigo apontadores para seus pais, é possível reconstruir todo o histórico até chegar a ele. Além disso, como cada commit é uma fotografia, é possível “voltar ao tempo” ou mudar de branch usando o comando “git checkout <rev>” – seja com um SHA-1 ou com um nome mais amigável.
$ git checkout master
Se voltarmos usando um SHA-1, nos encontraremos potencialmente sem branch, pois não temos um ponteiro para o commit dessa nova cabeça . Caso queira iniciar o desenvolvimento a partir desse ponto é recomendável criar uma branch (ponteiro). Para isso basta usar:
$ git checkout -b <nome_da_branch>
Agora que conseguimos nos posicionar com tranquilidade em qualquer parte do histórico, vamos passar para a parte de criar novos commits. Antes que um commit efetivamente aconteça é necessário que as modificações passem pela staging area. Essa é uma área em que o programador tem total liberdade de manipulação para que o commit saia precisamente da maneira desejada. Após um número suficiente de alterações que devam resultar em um commit, use o comando “git status” para entender qual o estado atual de sua arvore de trabalho. Com ele é possível ver quais arquivos foram alterados, renomeados, adicionados, deletados e assim por diante. É possível também ver quais arquivos estão na staging area prontos para umcommit. Toda vez que precisar adicionar um arquivo a essa área use:
git add <caminho>
Se por acaso estiver arrependido e quiser remover um arquivo da staging area, mas conservando suas modificações, use o comando de unstage, que infelizmente não há em uma forma compacta (entretanto, pode-se criar alias no shell).
git reset HEAD <caminho>
Se estiver insatisfeito com as alterações nesse arquivo e quiser desfazê-las, observe que não haverá volta.
git checkout -- <caminho>
Observe que no comando de unstage foi usado a referência simbólica HEAD (cabeça). HEAD na verdade é um ponteiro de ponteiro que aponta para a variável da branch corrente. Sendo assim, esse ponteiro provê muita praticidade já que evita a utilização explícita do nome dessa branch.
$ git symbolic-ref HEAD refs/heads/master $ git branch * master
Salvando modificações temporárias com Stash
Muitas vezes estamos no meio do desenvolvimento com árvore de trabalho suja e precisamos corrigir um bug urgente em outra branch. O que fazer? O ideal seria armazenar as modificações em alguma área temporária para retomá-las depois. Visando simplificar esse processo, Git criou a família de comandos “git stash”.
Com “git status” verificamos que o arquivo a.txt foi modificado, mas ainda não gostaríamos de commitá-lo.
$ git status # On branch user/feature # Changed but not updated: # (use "git add <file>..." to update what will be committed) # (use "git checkout -- <file>..." to discard changes in working directory # # modified: a.txt # no changes added to commit (use "git add" and/or "git commit -a")
Com o “git stash” salvamos essa modificações e com isso o diretório de trabalho fica limpo. Dessa forma estamos prontos para mudar para outra branch.
$ git stash Saved working directory and index state WIP on user/feature: f0be6e8 File HEAD is now at f0be6e8 File $ git status # On branch user/feature nothing to commit (working directory clean)
Depois de feita a correção do bug crítico, voltamos a branch de desenvolvimento. Agora vamos ver a pilha de stash e como não criamos nenhum outro nesse meio tempo, ele será o último. Nesse caso, “stash@{0}”.
$ git stash list
stash@{0}: WIP on user/feature: f0be6e8 File
Vamos aplicar o stash salvo e confirmar que o arquivo a.txt foi atualizado.
>git stash apply stash@{0}
# On branch user/feature
# Changed but not updated:
# (use "git add <file>..." to update what will be committed)
# (use "git checkout -- <file>..." to discard changes in working directory)
#
# modified: a.txt
#
no changes added to commit (use "git add" and/or "git commit -a")
Reescrevendo o histórico
Reescrever o histórico no escopo de uma branch pode ser importante por vários motivos como reordenar alguns commits, melhorar algumas mensagens, quebrar commits grandes em partes atômicas ou até mesmo juntar commits de uma mesma funcionalidade. Alguma dessas necessidades pode surgir como resultado de code review ou até mesmo devido ao processo de desenvolvimento não ser completamente previsível. Por isso, é muito importante contar com um sistema de controle de versão flexível como Git.
É importante notar que o histórico só deve ser reescrito em faixas de commits criadas localmente e que ainda não foram publicadas, ou seja, que ainda não foram potencialmente integradas por outro usuário. Toda vez que parte do histórico é reescrita novos objetos de commit com SHA-1 completamente diferentes dos antigos são criados o que pode conflitar com os antigos commits que foram incorporados por outro usuário.
Um dos motivos que torna a remoção forçada de um commit de uma branch de referência algo altamente indesejado é justamente o conflito que poderá ocorrer com outros usuário que potencialmente já incorporaram esse commit. Por isso é mais recomendável usar “git revert” que criará um novo commit desfazendo alterações anteriores.
Com certos cuidados em mente, vamos agora ao ferramental para manipular o histórico. Se estiver inseguro com relação às mudanças, pode ser interessante criar uma outra branch (“git checkout -b <nome_da_branch>”) para mudar o histórico, deixando a branch original intacta.
Mudando a mensagem do último commit
Uma das alterações mais simples é a mudança da mensagem do último commit. Muitas vezes percebemos um erro de ortografia ou simplesmente queremos melhorá-la. Antes vamos fazer um pequeno desvio para assegurar um mínimo de configuração. Certifique-se que seu editor preferido está configurado.
$ git config --global core.editor vi
As configurações são um conjunto de chaves (keys) e valores (values) sendo o comando “git config” capaz de exibir o valor de uma chave ou alterá-lo quando se passa mais um argumento para o comando anterior, que é justamente o novo valor. Observe que a opção “–goblal” faz com que as alterações fiquem disponíveis para todos os repositório daquele usuário na máquina em questão.
git config --global core.editor "emacs -nw"
Não se esqueça também de incluir o nome e o email, já que eles são muito importante para atribuir os créditos e as responsabilidades do commiter.
$ git config --global user.name "Meu Nome" $ git config --global user.email 'meuemail@meudominio.com'
Agora vamos, voltar ao nosso propósito original que era o comando para edição da mensagem do ultimo commit.
$ git commit –amend
Agora será aberto automaticamente seu editor preferido. Basta reescrever a mensagem da forma desejada, salvar as alterações e sair do editor. Repare que o SHA-1 do commit foi alterado. Pode-se conferir o resultado com “git log”.
$ git log
Se preferir o conforto de uma interface gráfica é possível usar programas como o gitk.
$ gitk
Rebase interativo
Sem dúvida o comando de dia a dia mais importante para reescrever o histórico no escopo de uma branch é o rebase interativo. Com ele é possível fazer praticamente qualquer alteração em uma faixa de commits. Para usá-lo é necessário passar como referência um commit de base, já que os commits filhos até o commit cabeça (apontado indiretamente por HEAD) serão mostrados para manipulação. Se por exemplo pegarmos o pai do antepenúltimo commit, cujo prefixo de SHA-1 é 0bc7ae0, podemos usar esse comando da seguinte maneira (note a presença do “-i”):
$ git rebase -i 0bc7ae0
Com isso, um editor será laçado mostrando os commits a partir de 0bc7ae0 até o commit cabeça (inclusive). Note que essa ordem é a inversa da mostrada por “git log”. Como sempre o Git tentará ajudar colocando informações em comentários, linhas começadas por ‘#’. Vamos analisar cada um desses comandos por vez.
pick dd33a13 Meu Antepenúltimo Commit pick f6bd651 Meu Penúltimo Commit pick e33196d Meu Último Commit # Rebase 0bc7ae0..e33196d onto 0bc7ae0 # # Commands: # p, pick = use commit # r, reword = use commit, but edit the commit message # e, edit = use commit, but stop for amending # s, squash = use commit, but meld into previous commit # f, fixup = like "squash", but discard this commit's log message # # If you remove a line here THAT COMMIT WILL BE LOST. # However, if you remove everything, the rebase will be aborted. #
Pick
O comando pick, do inglês “pegar”, informa que o commit especificado pelo prefixo de SHA-1 será conservado. Observe que esse é o comportamento padrão. Para simplificar ainda mais, Git permite que seja usado a primeira letra ao invés do nome inteiro de cada comando.
Reword
Esse é um atalho relativamente novo e que permite mudar o texto de um commit. Lembra-se do “git commit –amend” que permitia mudar a mensagem do ultimo commit? Com o reword podemos mudar qualquer mensagem que esteja dentro da faixa do nosso rebase interativo inclusive do último. Dessa forma, temos uma versão mais poderosa do comando visto anteriormente. Antes de reword existir era necessário passar por uma combinação de outros comandos como veremos a seguir.
Edit
Esse comando é bem poderoso, permitindo voltar no tempo à fotografia do commit que deseja-se editar, depois pode-se realizar qualquer tipo de alteração e potencialmente reaplicar os commits mais novos da faixa de rebase interativo. Como o próprio nome indica um rebase interativo pode ser formado por algumas interações de mudança de histórico. Para navegar de nesse processo de potencialmente múltiplas etapas, o comando “git rebase –continue” indica que a etapa corrente pode ser encerrada, já o comando “git rebase –abort” serve para se desistir de todo processo.
Vamos passar agora para alguns exemplos que ilustram a utilização de edit. Suponha que o comando reword não existe, como você poderia criá-lo? Sabemos que com o edit podemos voltar ao tempo para um commit que se deseja editar, e o processo interativo para com esse commit sendo o mais recente do histórico. Com isso basta aplicar o velho conhecido “git commit –amend”, já que ele é capaz de modificar o último commit, que no caso é o commit especificado no comando edit. Para dar continuidade ao processo iterativo não se esqueça de usar o “git rebase –continue”. Com isso, os commits mais recentes que o commit editado serão aplicados ao seu topo.
Vamos agora para um caso um pouco mais interessante, e se quisermos quebrar um commit em vários menores? Voltar no tempo podendo reaplicar commits mais novos de forma automática já está claro usando o comando edit.
No caso usamos o commit cinza como base para o rebase.
$ git rebase -i 0bc7ae0
No editor vamos apenas mudar a opção de pick para edit na linha do penúltimo commit (note que poderíamos perfeitamente usar como base o commit HEAD~2).
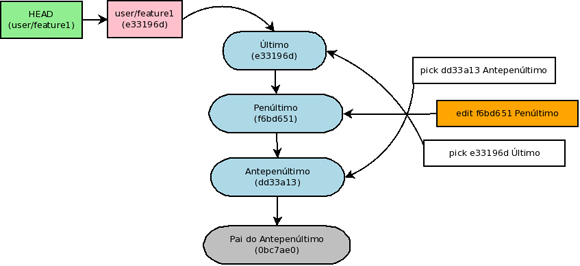
Com isso voltaremos no tempo, para a fotografia do penúltimo commit. Sendo que o commit marcado para edição encontra-se no topo do histórico.
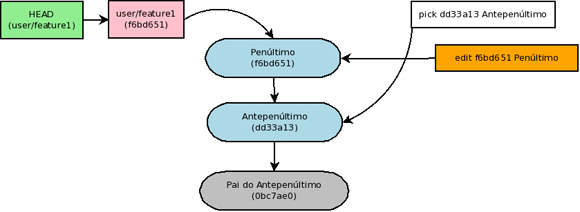
Agora basta combinar outro comando capaz de quebrar um commit e deixar suas alterações na árvore de trabalho. Esse último comando é o “git reset”:
$ git reset HEAD^1
Observe que com o HEAD^1 estamos referenciando o commit anterior ao HEAD. Quando o commit corrente for resultado de um merge (caso em que há múltiplos pais), HEAD^n quer dizer o n-ésimo pai. Entretanto, para acessar níveis mais profundos do histórico como avô e bisavô é possível usar HEAD~n com n igual a 2 e 3 respectivamente (nesse caso se houver múltiplos pais sempre é escolhido o primeiro). Note que HEAD^1 e equivalente a HEAD~1.
Agora basta fazer um “git status” para ver que as alterações introduzidas pelo antigo commit HEAD estão de fato espalhadas na árvore de trabalho. Com “git log”, vemos que o antigo commit HEAD sumiu dando lugar ao seu pai como mais recente.
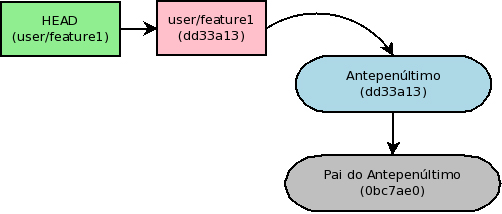
Agora basta adicionar as mudanças com “git add” para colocá-las na staging area e efetivamente fazer o commit, com a mesma liberdade de sempre. No exemplo, geramos dois novos commits: “Novo 1” e “Novo 2”.
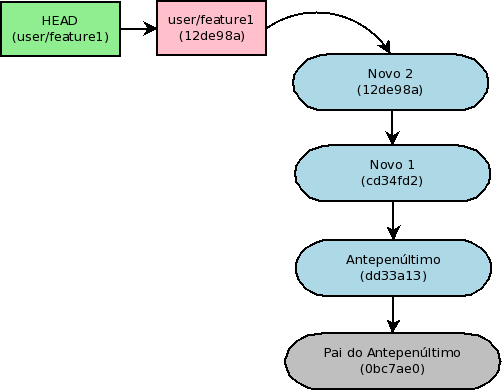
Se estiver contente com o resultado, basta continuar o processo com:
$ git rebase –continue
Se estiver arrependido, não tem problema; basta fazer:
$ git rebase –abort
Com o “git rebase –continue”, o processo continua. No caso tínhamos escolhido conservar o ultimo commit, por isso ele é aplicado automaticamente no topo de “Novo 2”.
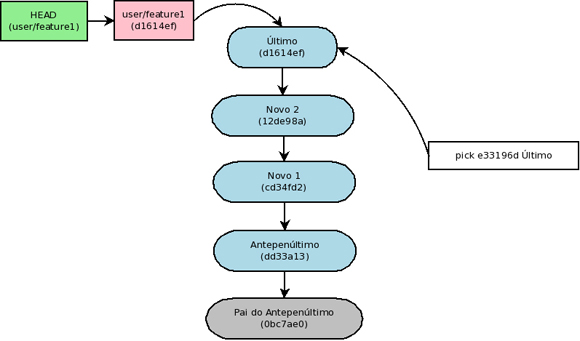
Squash
Aprendemos como quebrar um commit em vários, porém é possível fazer o caminho inverso: combinar vários commits em um único. Para isso pode-se usar o comando squash. Cada commit marcado para squash será combinado com o commit anterior. E para cada commit resultante será mostrado um editor, para que as mensagens dos commits envolvidos possam ser aproveitadas da melhor maneira possível.
É possível combinar os três últimos commits da seguinte forma:
$ git rebase -i 0bc7ae0
Usamos pick para o antepenúltimo commit para que os dois mais recentes se fundam a ele com squash.
pick dd33a13 Meu Antepenúltimo Commit squash f6bd651 Meu Penúltimo Commit squash e33196d Meu Último Commit
Essa operação resultará em apenas um único commit e na tela do editor, poderão ser vistas as três mensagens.
# This is a combination of 3 commits. # The first commit's message is: Meu Antepenúltimo Commit # This is the 2nd commit message: Meu Penúltimo Commit # This is the 3rd commit message: Meu Último Commit
Fixup
Um outro comando também relativamente recente é o fixup, que assim como o reword, ele nada mais é do que um atalho. No desenvolvimento é muito comum fazer alguma correção relativa a um commit anterior e que por isso deve ser integrada a ele. Como o commit que contem a correção vai ser integrado ao commit principal, em geral, a mensagem daquele não é muito relevante. Se usarmos o comando squash, teremos que remover inteiramente a mensagem do commit de correção. Já no caso do fixup, esta mensagem é descartada automaticamente restando apenas a mensagem do commit original. Como podemos ver, esse novo comando traz apenas mais comodidade ao processo de squash.
Comandos implícitos
Há dois comandos que são implícitos: reordenação de comandos e remoção de commits. Se usarmos apenas o comandopick em um rebase interativo, reordenando as linhas de comandos, os commits serão reordenados. Note que nesta operação é possível que haja conflitos. No caso da remoção, se um commit for suprimido no editor, ou seja, se ele não aparecer em nenhum comando, ele será suprimido. Pode ocorrer do commit suprimido ficar “inacessível”, caso em que não exista nenhum caminho de uma das cabeças do repositório até ele. Entretanto para recuperar sua referência é possível usar “git reflog” desde que não tenha sido feita nenhuma coleta de lixo.
É desejável que cada commit de uma branch de referência represente um estado consistente do código. Com reordenação é possível, por acidente, deixar arquivos que dependam de outros mais antigos, em um commit anterior ao commit que cria suas dependências, deixando o repositório com uma faixa de commits inconsistente. Por ser um problema que não está sob o controle de Git, é responsabilidade do usuário zelar para que nenhum erro ocorra com essas operações delicadas.
Rearranjando Commits
No Git existe uma certa dualidade na natureza do commit. Ao mesmo tempo que um commit é uma fotografia precisa do repositório, ele pode ser encarado como um conjunto de alterações. Quando se compara a fotografia do commit corrente com a de seus pais é possível determinar precisamente as alterações introduzidas pelo commit em questão. Na condição de portador de mudança, pode ser extremamente desejável incorporar commits de uma branchs em uma outra, trazendo assim as alterações introduzidas por esse commit. Dependendo da maneira como é incorporado, esse commit pode não mais simbolizar a mesma fotografia que simbolizava na branch original, por isso um novo commit pode ser gerando resultando assim em um novo hash SHA-1.
Nessa seção serão abordadas algumas das formas mais comuns de manipular commits. Podemos delicadamente selecionar um único commit para ser incorporado ou faixas de commit com mais ou menos controle sobre a operação. Normalmente o comandos mais indicados para cada situação vem do balanço entre controle e praticidade.
Cherry Pick
Talvez o comando cherry pick seja um dos mais precisos para manipulação de commits. Ele é muito usado quando se necessita incorporar cirurgicamente um commit de uma outra branch no topo da branch corrente (apontado por HEAD).
Um típico caso de uso é quando precisa-se incorporar uma correção de uma branch de desenvolvimento mais nova quando esta correção também impacta uma branch estável mais antiga. Nesse caso é bem provável que a branch de desenvolvimento tenha divergido muito da branch estável, não sendo nem um pouco interessante incorporar mais do que o commit de correção.
A figura abaixo mostra uma branch estável versão 2.2 e uma branch de desenvolvimento devel3.1 contendo a correção crítica (em laranja) que também é válida para a versão 2.2.
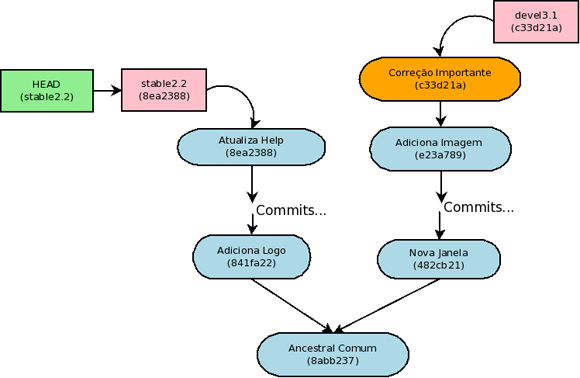
Certifique-se de que esteja na branch em que deseja incorporar o commit – se não estiver basta usar o “git checkout <branch>”. Agora, com o comando “git cherry-pick” vamos incorporar o commit de correção que sabemos ter “c33d21a” como prefixo de SHA-1.
$ git cherry-pick c33d21a
Poderíamos ter usado como alternativa para revisão o nome da branch, já que o commit que desejamos está seu topo.
$ git cherry-pick devel3.1
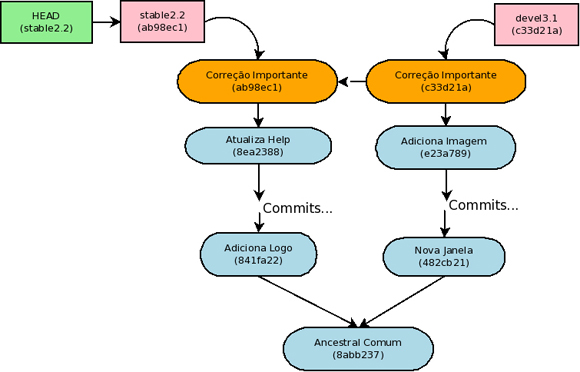
Com isso, vemos que o commit foi incorporado na branch estável 2.2. Observe que como incorporamos as alterações trazidas por ele e que nosso histórico pode não ter nenhuma relação com o histórico original do commit, esse novo commit pode não mais representar a mesma fotografia, por isso um novo objeto commit foi criado, como pode-se constatar pelo novo SHA-1.
Rebase
É muito comum que o desenvolvimento gire em torno de uma branch, potencialmente a master. Nela os commits de vários usuários são incorporados para que fiquem disponíveis a todos.
Localmente quando um usuário vai criar uma nova funcionalidade ou fazer uma correção, é boa prática criar uma branch a partir da branch de referência justamente com essa finalidade. Com isso tem-se um ponto de bifurcação. Se ao mesmo tempo em que o usuário cria novos commits em sua branch local, outros commits são incorporados à branch de referência, pode-se dizer que essas duas branches divergiram.
Do ponto de vista do usuário que possui a branch local, pode ser interessante ou até mesmo obrigatório incorporar as alterações da branch de referência antes de submeter seus commits. É possível que algum novo commit da branch (de referência) corrija algum bug ou que exista um política de “fast foward“.
No caso de correção de bugs, o interesse em incorporar os commits é claro. Já no caso da política “fast foward” o responsável pela branch pretende simplificar o histórico evitando merges complicados em que um commit tenha múltiplos pais. Com essa política espera-se que os commits de cada usuário se apliquem de forma natural ao topo da branch de referência, resultando em um linha contínua de commits. Para simplificar esse processo, antes que um usuário submeta seus commits é necessário que eles estejam aplicados ao topo da branch de referência.
A figura abaixo mostra os novos commits (em laranja) criados na branch local de um usuário.
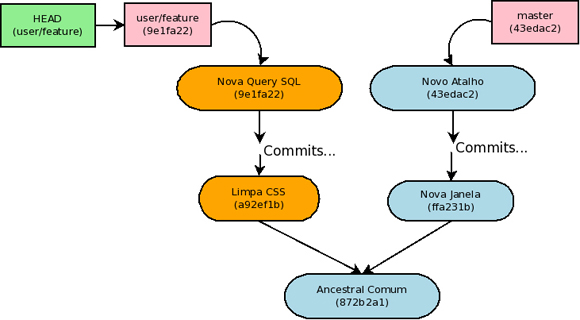
O comando “git rebase” tem justamente a finalidade de “recriar” a branch local aplicando os novos commits introduzidos por ela (em laranja) no topo de uma branch de referência. Como o próprio nome do comando indica, estamos mudando a base de alguns commits, no caso a base dos commits introduzidos na branch local. No exemplo a branch de referencia é a master, então pode-se fazer:
$ git rebase master
Com isso tem-se a branch local formado pelos novos commits da branch de referência com seus próprios commits aplicados ao topo.
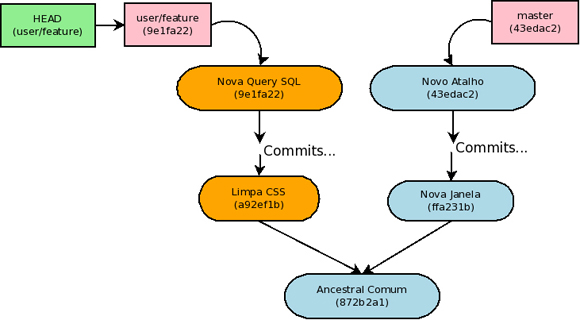
Rebase –onto
Podemos estar interessados em pegar uma faixa de commits de uma branch e aplicá-la ao topo de um commit de referência. Para isso existe o comando “git rebase –onto” na sua forma de três revisões como argumento.
$ git rebase –onto <base> <pai_do_inicio_da_faixa> <final_da_faixa>
Ao aplicar esse comando, a branch corrente conterá a faixa de commits aplicada ao commit de base. Vamos ilustrar com um exemplo gráfico para simplificar. Suponha que queremos transformar nossa branch corrente na aplicação dos commits em laranja no topo da branch master. Para isto, primeiramente nos posicionamos na branch em que essas modificações devem ocorrer. Identificamos os SHA-1 da nossa base que é “43edac2”. Agora faltar determinar os SHA-1 que delimitam nossa faixa de commit. Para o pai do início da faixa tem-se “c71da12” e como final de faixa tem-se “a1c87d1”.
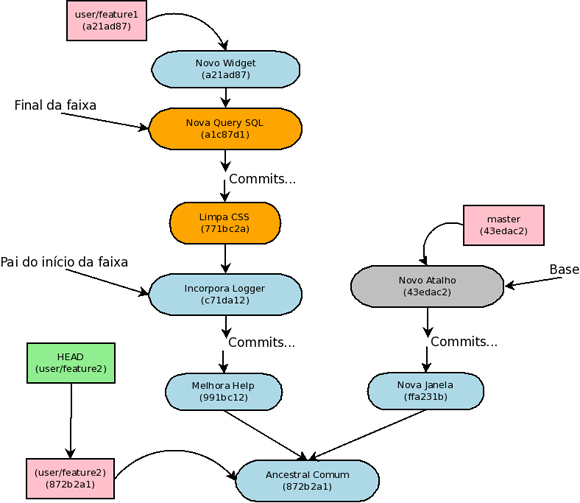
Com as três informações de revisão em mãos basta fazer:
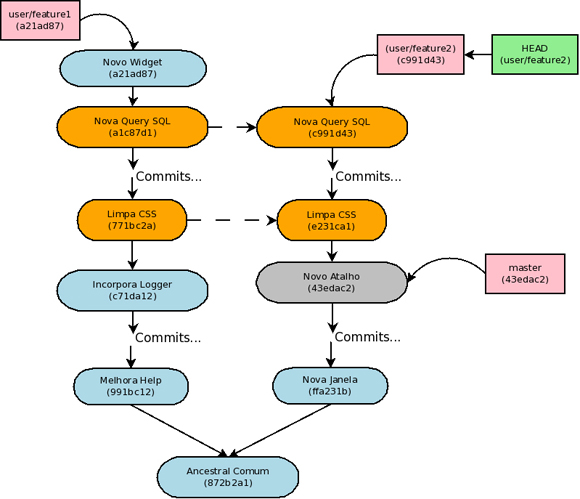
$ git rebase –onto 43edac2 c71da12 a1c87d1
Ou alternativamente:
$ git rebase –onto master c71da12 HEAD~1
Esse comando resulta na seguinte mudança mostrada na figura a abaixo:
Merge
O comando “git merge” também é um ferramenta chave para se rearranjar commits, com ele é possível combinar múltiplas linhas de desenvolvimento. Por questões de espaço não o detalharemos aqui.
Conclusão
O sistema Git é bem poderoso, mas para se ter acesso a parte desse poder é preciso conhecer algumas ferramentas-chave. Neste artigo foi abordado com mais profundidade o ferramental de reescrever o histórico e rearranjar os commits. Com isso espera-se que um usuário básico tome conhecimento de algumas funcionalidade mais avançadas, podendo melhor explorar esse fabuloso sistema de controle de versão.
Referências
***
Sobre o autor: Fernando é formado em Engenharia da Computação pela UNICAMP e possui Duplo-Diploma em Engenharia pela Universidade Francesa Télécom ParisTech. Trabalha há um ano no Linux Technology Center da IBM.
Perfil My DeveloperWorks.
***
O artigo original está disponível em: http://www.ibm.com/developerworks/br/local/opensource/saindo_basico_git/index.html

De 0 a 10, o quanto você recomendaria este artigo para um amigo?