

A análise preditiva, business intelligence e mineração de dados, em geral, exigem o armazenamento e processamento de estruturas de dados complexas e muitas vezes totalmente diferentes à medida que as informações são processadas, resolvidas e resumidas. É altamente provável, em especial para informações comerciais e financeiras, que uma quantidade significativa de dados venha de bancos de dados relacionais. Eles seguem uma estrutura rígida e exigem preparação significativa em termos de projeto antecipado do seu esquema e de modelos de dados. A nova geração de NoSQL e bancos de dados baseados em documento simplifica muito desse processamento porque é possível criar e fazer dump de informações em formato flexível. Além disso, você pode trabalhar em métodos para extrair os dados no formato fixo que precisar. Neste artigo, analisarei como usar bancos de dados baseados em documentos para processamento de dados e analítica como parte de sua solução geral de banco de dados.
Arquitetura do banco de dados de documento
Um dos elementos-chave de todos os bancos de dados de documentos é que eles podem manipular e trabalhar com estruturas e conjuntos de dados muito maiores do que o normal. Em especial, devido à sua natureza distribuída e à maneira diferente em que armazenam dados fisicamente, eles são ideais quando houver uma grande quantidade de dados a serem processados, como frequentemente é o caso na mineração de dados.
Esses benefícios são evidentes e documentados em outra parte. Este artigo concentra-se na estrutura e no formato das informações e nas técnicas utilizadas para processar e relatar as informações armazenadas.
Estrutura de dados flexível
Bancos de dados de documentos têm uma estrutura (quase) infinitamente flexível que fornece diversas áreas-chave diferentes de funcionalidade:
- Sem esquema: bancos de dados de documento não precisam predefinir a estrutura dos dados que devem ser armazenados neles. Em RDBM tradicional, especifique a estrutura das tabelas em que os dados são armazenados e tente prever o conteúdo, os valores possíveis e a estrutura das informações. Com um banco de dados de documentos, é possível armazenar informações nos documentos sem ter que se preocupar com a estrutura, se há vários campos e nem mesmo, na maioria dos casos, quais são os relacionamentos de um para muitos e de muitos para muitos. Em vez disso, é possível concentrar-se no próprio conteúdo das informações. Isso pode facilitar muito o armazenamento de matéria-prima e de informações, embora possam ser provenientes de fontes distintas. A maior flexibilidade também significa que é possível combinar e processar informações de diferentes tipos e estruturas. Por exemplo, o processamento de dados textuais é difícil de conseguir com um RDBMS tradicional, porque é preciso garantir que a estrutura (número de frases, parágrafos, etc.) seja flexível o suficiente para suportar as informações recebidas. De forma mais explícita, imagine cotejar os dados do Twitter, Facebook e outras fontes de mídia social e procurar padrões. As informações no Twitter têm um comprimento fixo, e são incluídas em uma única cadeia de caractere pequena. O Facebook não tem elementos separados para saída de informações (texto, localização e indivíduos). Seria necessária uma quantidade significativa de processamento dessas informações de forma a coletá-las, unificá-las e colocá-las em uma estrutura rígida.
- Objetos lógicos: a maioria das soluções de RDBMS é utilizada para modelar informações que normalmente estariam em um formato (relativamente) estruturado. Em seguida, SQL e junções são usados para moldar essas informações em um objeto que é usado internamente. Pode-se observar individualmente diferentes elementos da estrutura de dados global, mas com frequência as informações são combinadas e relatadas de acordo com o objeto que recolhe todos os dados.A partir de uma perspectiva mais complexa, muitas vezes fatiamos e fragmentamos os diferentes elementos de dados de maneiras diferentes, embora na realidade ainda estejamos apenas escolhendo elementos dessa estrutura geral. A estrutura do documento altera essa perspectiva. Em vez de observar pontos de dados distintos e individuais, os documentos observam os objetos como um todo. O rastreamento de informações sobre coletores de dados, por exemplo, pode exigir que todas as informações sobre esse objeto estejam no lugar, embora diferentes coletores de dados possam ter diferentes sensores, números diferentes de sensores e diferentes níveis de complexidade.
- Estrutura migratória: os dados mudam ao longo do tempo, às vezes lenta e às vezes rapidamente. Modificar a estrutura de dados é um processo complexo, que não afeta apenas o banco de dados que você usa, mas também exige mudanças nos aplicativos que acessam e usam essas informações. Com uma estrutura baseada em documento, visto que a estrutura dos dados é fixa, a adaptação dessa estrutura a novas versões e formatos diferentes dos dados originais é difícil e complexa. É preciso criar uma tabela ou modificar a tabela existente para lidar com a nova estrutura, o que significa a conversão de todos os registros criados anteriormente para corresponderem à nova estrutura. Com um banco de dados de documento, a estrutura dos documentos pode ser modificada. De fato, as estruturas dos documentos individuais podem ser diferentes de um para o outro. Visto que você está sempre lidando com documentos inteiros, é improvável que seu aplicativo precise lidar com mudanças até precisar processar os novos dados.
Em vista disso tudo, o que significa na prática coletar, extrair e processar essas informações?
A primeira coisa a levar em conta é o formato dos próprios dados. Bancos de dados de documentos podem armazenar qualquer informação, mas o formato estrutural mais utilizado é JSON, um formato de notação de objeto da linguagem JavaScript. Ele permite armazenar cadeias de caractere, números, arrays e dados (hash) de registro, e as combinações desses tipos básicos.
Para fins de compreensão das noções básicas de processamento de documentos, este artigo utiliza dados bastante simples. Listagem 1 é um documento que rastreia o nível de água e a temperatura de um tanque de água externo:
Listagem 1. Documento que rastreia o nível de água e a temperatura de um tanque de água externo
{
"datestring": "Tue Nov 30 01:40:30 2010",
"hour": 1,
"min": 40,
"waterlevel": 96,
"day": 30,
"mon": 11,
"year": 2010,
"temperature": "28.64"
}
Os componentes de data individuais foram armazenados para obter flexibilidade, embora sejam inteiramente opcionais. O nível de água e a temperatura são armazenados como valores brutos.
Um criador de logs diferente rastreia a temperatura de um tanque de água em três pontos e representa seus dados como um hash dos diferentes valores (consulte a Listagem 2):
Listagem 2. Documento que rastreia a temperatura do tanque em três pontos
{
"datestring": "Tue Nov 30 02:06:21 2010",
"temperature": {
"mid": 23.2148953489378,
"top": 23.6984348277329,
"bot": 23.0212211444848
}
}
Na verdade, colocar os dados em um banco de dados de documentos, como Hadoop ou Couchbase Server, é provavelmente a parte mais fácil do processo. Em comparação, não há processamento nem construção de dados ou de estrutura para retê-los. Não precisamos analisar os dados para identificar uma estrutura; basta armazená-los em sua forma bruta.
É o processamento durante a extração que torna eficiente a mineração de dados com base em documento.
Intercâmbio de dados
Se houver dados dentro de um RDBMS tradicional, como o IBM DB2, será possível usar um banco de dados de documentos para simplificar e unificar de forma mais normal diferentes dados em documentos que podem ser processados por um banco de dados de documentos para tirar proveito do formato unificador.
Talvez você ache errado executar essa operação: se já estão em um banco de dados, por que movê-los? Mas as soluções RDBMS são usadas há anos para armazenar informações textuais e diferentes versões e revisões de dados tabulares. Um banco de dados de documentos pode ser uma forma eficaz de unificá-los em uma estrutura que pode ser usada para mapear/reduzir e para outras técnicas.
O processo mais simples é carregar seus objetos à medida que eles são formatados e estruturados dentro do banco de dados. Isso é fácil se você estiver usando um sistema ORM para modelar seus dados em um objeto. Fora disso, é possível executar o processo à mão. O script na Listagem 3 executa a operação tirando um registro de componente complexo carregado por meio de uma função que compila instruções SQL individuais para gerar um objeto interno, formatá-lo para JSON e depois gravá-lo em um banco de dados de documentos (nesse caso, o CouchDB):
Listagem 3. Operação para carregar seus objetos
[perl]
foreach my $productid (keys %{$products})
{
my $product = new Product($fw,$productid);
my $id = $product->{title};
$id =~ s/[ ‘,\(\)]//g;
my $record = {
_id => $id,
title => $product->{title},
componentcount => $product->{componentcount},
buildtime => $product->{metadata_bytag}->{totalbuildtime},
testtime => $product->{metadata_bytag}->{totaltesttime},
totaltime => $product->{metadata_bytag}->{totaltime},
keywords => [keys %{$product->{keywordbytext}} ],
};
foreach my $component (@{$product->{components}})
{
push(@{$record->{component}},
componentqty => $component->{‘qty’},
component => $component->{‘componentdesc’},
componentcode => $component->{‘componentcode’},
}
);
}
my $req = HTTP::Request->new(‘POST’ => $base);
$req->header(‘Content-Type’ => ‘application/json’);
$req->content(to_json($record));
my $res = $ua->request($req);
}
[/perl]
Pode-se usar processos similares com outras informações e bancos de dados de documentos. Em Hadoop, por exemplo, é possível criar um novo arquivo único para cada registro de produto.
Ao combinar informações de várias tabelas em um formato único para o processamento, embora não seja obrigatório usar os mesmos nomes de campo (que podem ser resolvidos no tempo de processamento), não há razão, pelo menos, para não padronizar alguns dos campos (datas, pontos de dados) se as informações forem praticamente as mesmas.
Durante o processamento, como no código de exemplo, você talvez queira realizar também pré-processamento e formatação das informações. Por exemplo, você pode harmonizar os dados para usar os mesmos pontos de medição ou combinar os campos que foram usados de maneira diferente nos dados de origem.
Processamento na extração
Com a estrutura do documento flexível em mente, o processamento e a identificação de padrões nessas informações são processos que acontecem ao extrair os dados, em vez de impor a extração e o processo de geração de relatórios no ponto onde os dados são colocados.
Em um RDBMS típico, a estrutura é composta de tabelas e campos que dependem de como você deseja que as informações sejam extraídas posteriormente. Por exemplo, com as informações de criação de log, é possível associar uma tabela de ponto de criação de log (que contém a data) a uma tabela de ponto de dados que contém os dados de log específicos. Você sabe que, a partir do processo, é possível executar uma junção para conectar o ponto de criação de log com seus dados em tempo às informações de temperatura e nível de água para poder rastrear e monitorar os valores ao longo do tempo (consulte a Figura 1).
Figura 1. Executando uma junção
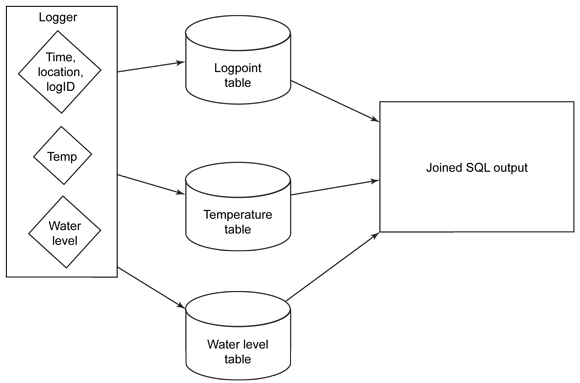
O processamento das informações é feito no ponto de entrada, separando as informações para poderem ser inseridas em tabelas e depois unificadas no ponto de saída por meio da recombinação das informações. O processo requer que você saiba como deseja que as informações sejam relatadas, juntadas e processadas na saída. É possível gravar uma instrução SQL apenas se for conhecida a estrutura da tabela.
Com um banco de dados de documentos, é o processo dos dados brutos que cria a visualização harmonizada das informações que permite que os dados sejam processados, quer sejam dados com base de valor, quer dados temáticos e textuais. As informações são colocadas em vários documentos e o sistema de mapeamento/redução processa essas informações e gera uma tabela de estrutura a partir dos dados (consulte a Figura 2).
Figura 2. Gerando uma tabela estruturada a partir de dados
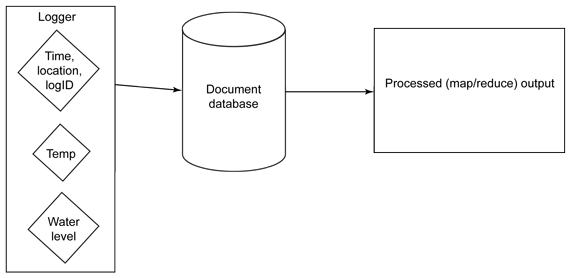
Com o banco de dados de documentos, processe as informações depois de elas terem sido inseridas. Isso significa que é possível processar e até mesmo alterar a forma como os dados são extraídos enquanto ainda estiverem sendo usados e processados os dados brutos em seu formato original. Todo o tempo, você tem total flexibilidade sobre como as informações devem ser relatadas, sem perder nenhuma informação contextual.
Seguir esse método, é claro, exige algumas diferenças para a maneira em que você processa os dados brutos.
Usando Mapear/Reduzir
Existem muitos sistemas diferentes para o processamento de Big Data, para produzir e pegar informações e processá-las para analítica de dados, especialmente com bancos de dados de documentos. As soluções variam em sua abordagem, de mecanismos de consulta simples, semelhantes aos disponíveis em um banco de dados SQL, a análise e entendimento mais complexos baseados em programa. A última solução é frequentemente usada em situações em que é precisa modelar e entender os dados subjacentes para que seu sistema de processamento possa desenvolver o entendimento das informações essenciais em um formato adequado para seu processamento e resumo.
Sem dúvida, a mais comum dessas técnicas é Mapear/Reduzir. Ela tem duas etapas: mapear para extrair as informações e a função de reduzir para simplificar e resumir os dados.
O papel da função de mapear é levar as informações de entrada, os documentos armazenados, e simplificá-los em um formato que forneça uma saída harmonizada e adequada para análise. Por exemplo, utilizando os dados de log anteriores, pode-se obter os dados de temperatura individuais e os dados de temperatura de diversos pontos e enviar essas informações como um único ponto de dados, com base na informação da data e na temperatura, como mostrado na Listagem 4:
Listagem 4. Saída de dados de temperatura individuais e dados de temperatura de diversos pontos como um único ponto de dados
[perl]
function (doc, meta) {
if (doc.temperature && doc.temperature[“mid”]) {
emit(doc.datestring, parseFloat(doc.temperature[“mid”]));
emit(doc.datestring, parseFloat(doc.temperature[“top”]));
emit(doc.datestring, parseFloat(doc.temperature[“bot”]));
} else
{
emit(doc.datestring, parseFloat(doc.temperature));
}
}
[/perl]
O mapa mostrado na Listagem 4 é escrito em JavaScript e projetado para uso dentro do Couchbase Server, embora funcione no CouchDB, mas os princípios básicos também funcionam no Hadoop. A chamada de emissão gera uma ‘linha’ de informações, nesse caso uma chave e um valor. É possível ver uma amostra da saída de dados brutos na Listagem 5):
Listagem 5. Saída de dados brutos
{"total_rows":404,"rows":[
{"id":"1334307543","key":"Fri Apr 13 09:59:03 2012","value":22.6132600653245},
{"id":"1334307543","key":"Fri Apr 13 09:59:03 2012","value":25.903221768301},
{"id":"1334307543","key":"Fri Apr 13 09:59:03 2012","value":29.0646016268462},
{"id":"1322793686","key":"Fri Dec 2 02:41:26 2011","value":22.7931975564504},
{"id":"1322793686","key":"Fri Dec 2 02:41:26 2011","value":23.8901498654126},
{"id":"1322793686","key":"Fri Dec 2 02:41:26 2011","value":23.9022843956552},
{"id":"1292554769","key":"Fri Dec 17 02:59:29 2010","value":26.55},
{"id":"1324617141","key":"Fri Dec 23 05:12:21 2011","value":24.43},
{"id":"1296843676","key":"Fri Feb 4 18:21:16 2011","value":23.75},
{"id":"1297446912","key":"Fri Feb 11 17:55:12 2011","value":24.56}
]
}
O ID na saída mostrada na Listagem 5 é o documento que gera a linha (a partir da chamada emit()). Nesse caso, é possível ver que o primeiro e o segundo registros vêm de documentos com vários sensores de temperatura porque os IDs são idênticos.
O ponto crítico em mineração de dados com o Mapear/Reduzir é garantir que sejam coletadas as informações e os campos de dados corretos para desenvolver as informações desejadas. Dentro de Mapear/Reduzir, o formato do mapa é crítico. Providencie a saída de uma chave e do valor associado. O valor é obtido durante a fase de redução e chegará à gravação efetiva dessas informações em alguns momentos. Mas escolher o valor correto é crítico. Ao processar texto, o valor pode ser a análise temática da cadeia de caractere ou sentença que está sendo examinada. Ao analisar dados complexos, é possível optar por combinar vários pontos de dados, por exemplo, informações de vendas de mineração, em que se pode escolher a combinação de usuário exclusivo, produto e localização.
A chave é importante durante a mineração de dados porque fornece a base para o modo como as informações são comparadas. No exemplo mostrado na Listagem 5, escolhi a data como um todo, mas é possível criar estruturas mais complexas para permitir seleções mais complicadas. Por exemplo, se uma data for dividida em partes (ano, mês, dia, hora, minuto), é possível agrupar as informações de acordo com regras diferentes.
A Listagem 6 mostra uma versão modificada do mapa que explode a data em partes individuais:
Listagem 6. Mapa modificado que explode a data em partes individuais
[perl]
function (doc, meta) {
if (doc.temperature && doc.temperature[“mid”]) {
emit(dateToArray(doc.datestring), parseFloat(doc.temperature[“mid”]));
emit(dateToArray(doc.datestring), parseFloat(doc.temperature[“top”]));
emit(dateToArray(doc.datestring), parseFloat(doc.temperature[“bot”]));
} else
{
emit(dateToArray(doc.datestring), parseFloat(doc.temperature));
}
}
[/perl]
Isso gera saída de mapa ligeiramente modificada com a data como array (consulte a Listagem 7):
Listagem 7. Saída de mapa modificada com dados como array
{"total_rows":404,"rows":[
{"id":"1291323688","key":[2010,12,2,21,1,28],"value":23.17},
{"id":"1292554769","key":[2010,12,17,2,59,29],"value":26.55},
{"id":"1292896140","key":[2010,12,21,1,49,0],"value":25.79},
{"id":"1293062859","key":[2010,12,23,0,7,39],"value":23.5796487295866},
{"id":"1293062859","key":[2010,12,23,0,7,39],"value":26.7156670181177},
{"id":"1293062859","key":[2010,12,23,0,7,39],"value":29.982973219635},
{"id":"1293403599","key":[2010,12,26,22,46,39],"value":22.2949007587861},
{"id":"1293403599","key":[2010,12,26,22,46,39],"value":24.1374973576972},
{"id":"1293403599","key":[2010,12,26,22,46,39],"value":27.4711695088274},
{"id":"1293417481","key":[2010,12,27,2,38,1],"value":25.8482292176647}
]
}
Agora é possível combinar isso com uma função de reduzir para fornecer dados de resumo em diferentes intervalos. A função de redução pega a saída da função map () e resume essas informações de acordo com a estrutura de chave selecionada, até um formato mais simples. Os exemplos comuns são somas, médias ou contagens. A Listagem 8 fornece um exemplo de função de reduzir que calcula a média:
Listagem 8. Função de reduzir que calcula a média
[perl]
function(keys, values, rereduce) {
if (!rereduce){
var length = values.length
return [sum(values) / length, length]
} else {
var length = sum(values.map(function(v){return v[1]}))
var avg = sum(values.map(function(v){
return v[0] * (v[1] / length)
}))
return [avg, length]
}
}
[/perl]
Devido à natureza do sistema de redução, é preciso lidar com a média original (calculada a partir da saída da função map ()) e uma nova redução (na qual a saída de redução do primeiro nível é combinada com outras para a redução final em determinado intervalo de entrada).
A maior parte da função calcula a média dos dados de entrada (um array de valores da função map ()) e depois calcula a média dividindo a soma total pela contagem.
Quando acessado pela primeira vez, o conjunto de dados é agrupado e processado, resultando na média de todos os dados armazenados (consulte a Listagem 9):
Listagem 9. O conjunto de dados é agrupado e processado, resultando na média de todos os dados armazenados
{"rows":[
{"key":null,"value":[26.251700506838258,400100]}
]
}
Durante a saída das informações de data como array, é possível usar os componentes do array como critérios de seleção para os dados gerados. Por exemplo, se for especificado um nível de grupo de um, as informações serão agrupadas pelo primeiro elemento do array, ou seja, o ano (consulte a Listagem 10):
Listagem 10. Agrupamento das informações pelo primeiro elemento do array
{"rows":[
{"key":[2010],"value":[26.225817751696518,17484]},
{"key":[2011],"value":[26.252118781247404,199912]},
{"key":[2012],"value":[26.253719707387862,182704]}
]
}
Se for especificado um nível de grupo de 3, será possível obter as informações resumidas nas combinações individuais de ano/mês/dia (consulte a Listagem 11):
Listagem 11. Resumindo as informações em combinações individuais de ano/mês/dia
{"rows":[
{"key":[2010,11,30],"value":[26.23524809151833,505]},
{"key":[2010,12,1],"value":[26.37107941210551,548]},
{"key":[2010,12,2],"value":[26.329862140504616,547]},
{"key":[2010,12,3],"value":[26.31599258504074,548]},
{"key":[2010,12,4],"value":[26.389849136337002,548]},
{"key":[2010,12,5],"value":[26.175710823088224,548]},
{"key":[2010,12,6],"value":[26.21352234443162,548]},
{"key":[2010,12,7],"value":[26.10277260171637,548]},
{"key":[2010,12,8],"value":[26.31207700104686,548]},
{"key":[2010,12,9],"value":[26.207143469079593,548]}
]
}
É possível usar as funções de redução de resumir e identificar uma variedade de informações. Pode-se combinar uma função reduce() mais complexa com uma representação de texto da temperatura entre diferentes níveis de valor (aviso, erro e fatal) e mesclá-las em uma única estrutura (consulte a Listagem 12):
Listagem 12. Combinando uma função de redução mais complexa com uma representação de texto em uma única estrutura
[perl]
function(key, values, rereduce)
{ var response = {“warning” : 0, “error”: 0, “fatal” : 0 };
for(i=0; i<data.length; i++)
{
if (rereduce)
{
response.warning = response.warning + values[i].warning;
response.error = response.error + values[i].error;
response.fatal = response.fatal + values[i].fatal;
}
else
{
if (values[i] == “warning”)
{
response.warning++;
}
if (values[i] == “error” )
{
response.error++;
}
if (values[i] == “fatal” )
{
response.fatal++;
}
}
}
return response;
}
[/perl]
Agora você pode relatar as contagens de instâncias individuais desses erros em qualquer combinação de intervalo de data/hora, por exemplo, por mês (consulte a Listagem 13):
Listagem 13. Instâncias individuais de erros contadas por mês
{"rows":[
{"key":[2010,7], "value":{"warning":4,"error":2,"fatal":0}},
{"key":[2010,8], "value":{"warning":4,"error":3,"fatal":0}},
{"key":[2010,9], "value":{"warning":4,"error":6,"fatal":0}},
{"key":[2010,10],"value":{"warning":7,"error":6,"fatal":0}},
{"key":[2010,11],"value":{"warning":5,"error":8,"fatal":0}},
{"key":[2010,12],"value":{"warning":2,"error":2,"fatal":0}},
{"key":[2011,1], "value":{"warning":5,"error":1,"fatal":0}},
{"key":[2011,2], "value":{"warning":3,"error":5,"fatal":0}},
{"key":[2011,3], "value":{"warning":4,"error":4,"fatal":0}},
{"key":[2011,4], "value":{"warning":3,"error":6,"fatal":0}}
]
}
Esses são exemplos simplistas projetados para demonstrar o poder e a flexibilidade de mapear/reduzir, mas é fácil ver como lidar com diferentes formatos de documentos e estruturas em suas informações de fonte e também a forma de resumir e extrair informações durante o processo.
Encadeamento de mapear/reduzir
Como já vimos, Mapear/Reduzir é um método prático para análise e processamento de grandes quantidades de dados, quer suas informações e dados de fonte sejam armazenados para começar em um banco de dados adequado, quer não.
Dentro de Mapear/Reduzir, porém, existem limitações na quantidade de informações ligadas (implícita ou explicitamente) em diferentes documentos que podem ser combinados e relatados juntos. Da mesma forma, para informações muito complexas, um único processo de Mapear/Reduzir pode ser incapaz de manipular o processo na única análise da combinação de Mapear/Reduzir.
Em especial quando comparado com RDBMS tradicional de todos os tipos, a incapacidade de utilizar uma junção para combinar as informações entre vários pontos (incluindo a mesma tabela) torna certas operações na estrutura de Mapear/Reduzir impossíveis de alcançar em uma única etapa.
Por exemplo, ao processar informações textuais e realizar uma análise temática dos dados, você talvez passe por um processo antes de processar as informações e as sentenças a partir de matéria bruta e dividir os dados de origem brutos em blocos de documentos individuais. Isso pode ser conseguido por meio de um simples map() que processa as informações em novos documentos.
Uma etapa secundária poderia, então, processar as informações extraídas para fornecer uma análise mais detalhada dos fragmentos individuais e comparar e contar essas informações (consulte a Figura 3):
Figura 3. Processando as informações extraídas para fornecer uma análise mais detalhada
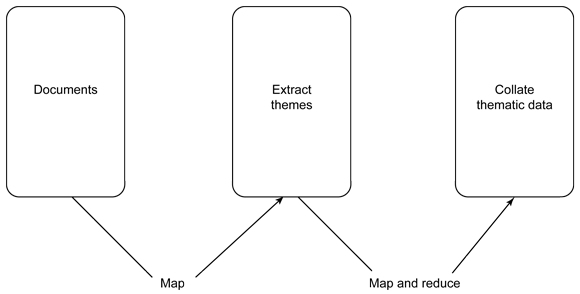
De uma perspectiva prática, o encadeamento de Mapear/Reduzir envolve a execução de uma função de Mapear/Reduzir para uma análise de primeiro nível e usar a chave da saída (da sua função map()) como ID do documento para, em seguida, manter a estrutura de dados que saiu dessa linha reduzida.
No exemplo de criação de log anterior, você poderia ter usado estrutura combinada de aviso/erro/fatal, escrito essa estrutura como novos dados em um novo banco de dados (ou bucket, usado no Couchbase) e, em seguida, executado processamento adicional daquele bucket para identificar tendências ou outros dados (consulte a Figura 4):
Figure 4. Executando processamento adicional para identificar as tendências ou outros dados
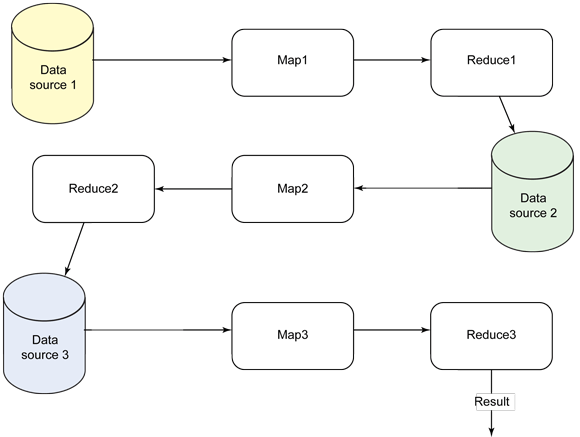
Lembre-se de que Mapear/Reduzir direto é apenas um elemento dos dados. Se forem exportadas e combinadas informações de outras fontes durante o processamento, também será possível usar e combinar essas informações nesse estágio no fluxo de dados.
Por exemplo, ao observar as informações de vendas, você pode ter informações sobre o cliente em um banco de dados, as vendas do cliente em outro e informações sobre o produto em outro. Ao executar Mapear/Reduzir nos dados de vendas, exportando-os para outro banco de dados, combinando-os com os dados do produto e, em seguida, reduzindo novamente antes de combinar com as informações do cliente, é possível gerar dados complexos em fontes aparentemente díspares.
Conclusão
Bancos de dados de documentos invertem completamente a estrutura normal de dados e as regras de processamento em sua cabeça. Já não é possível analisar, construir e formatar as informações em um formato tabular para facilitar o processamento. Em vez disso, os dados são armazenados em qualquer formato em que são recebidos e, em seguida, é feito o processamento que os analisa, manipulando os diferentes formatos e estruturas durante o processo. Esse processo pode simplificar grandes quantidades de dados até pedaços menores com muita facilidade. O processo de backend que permite bancos de dados muito grandes e distribuídos normalmente melhora, em vez de dificultar, o processo. É possível processar dados muito maiores e mais complexos usando a arquitetura de diversos nós. Como este artigo demonstrou, sua principal preocupação é construir um documento adequado e escrever a combinação correta e Mapear/Reduzir para processar os dados de forma eficaz.
Recursos
Aprender
- “O que é PMML?” (Alex Guazzelli, developerWorks, setembro de 2010): leia este artigo sobre o padrão PMML usado por empresas de analítica para representar e mover soluções preditivas entre sistemas.
- Analítica Preditiva: Leia a página da Wikipédia sobre analítica preditiva para obter uma visão geral de aplicações e técnicas comuns usadas para fazer previsões sobre o futuro.
- Leia o livro PMML in Action: Unleashing the Power of Open Standards for Data Mining and Predictive Analytics (maio de 2010).
- A opção Data Mining Group (DMG) é um consórcio independente liderado por fornecedores que desenvolve padrões de mineração de dados, como a Predictive Model Markup Language (PMML).
- Visite a seção Páginas de recursos de PMML da Zementis para explorar PMML completos.
- Visite a seção página de Mineração de Dados na Wikipédia.
- Faça parte das grupo de discussão do PMML no LinkedIn.
- Zona de software livre do developerWorks: encontre informações práticas, ferramentas e atualizações de projeto amplas para ajudá-lo a desenvolver com tecnologias de software livre e utilizá-las com produtos IBM.
- Para ouvir entrevistas e discussões interessantes para desenvolvedores de software, confira os Podcasts do developerWorks.
- developerWorks: Permaneça atualizado com os webcasts e eventos técnicos do developerWorks.
Obter produtos e tecnologias
- Hadoop suporta parte da estrutura NoSQL, como o formato sem esquema e a capacidade de usar Mapear/Reduzir para processar os dados armazenados.
- InfoSphere Warehouse é um conjunto de ferramentas completo para desenvolver e analisar dados que suporta muitas das técnicas de mineração de dados.
- WEKA é um kit de ferramentas baseado em Java que suporta uma série de diferentes algoritmos de mineração de dados e estatística.
- SPSS é um pacote estatístico que inclui recursos eficientes de análise preditiva.
- Couchbase Server é um banco de dados NoSQL de documentos com consulta e indexação baseadas em Mapear/Reduzir
- Inove seu próximo projeto de desenvolvimento de software livre com o software de teste IBM, disponível para download ou em DVD.
Discutir
- Participe do blogs do developerWorks e participe da comunidade do developerWorks.
***
Sobre o autor: Martin ‘MC’ Brown é escritor profissional há mais de 15 anos e é autor e colaborador em mais de 26 livros abrangendo uma variedade de tópicos, incluindo o recém-publicado “Getting Started with CouchDB”. Seu conhecimento abrange inúmeras linguagens de desenvolvimento e as plataformas Perl, Python, Java, JavaScript, Basic, Pascal, Modula-2, C, C++, Rebol, Gawk, Shellscript, Windows, Solaris, Linux, BeOS, Microsoft® WP, Mac OS, e muito mais. Ele foi editor de LAMP Technologies para a revista LinuxWorld e contribui regularmente para ServerWatch.com, LinuxPlanet, ComputerWorld e IBM developerWorks. Ele baseia-se em uma formação rica e variada como membro fundador de um ISP líder no Reino Unido, gerente de sistemas e consultor de TI para uma agência de publicidade e grupo de soluções de Internet, especialista técnico para uma rede de ISP intercontinental, designer e programador de banco de dados e como consumidor compulsivo confesso de hardware e software de computação. MC atualmente é Vice-Presidente de Publicações e Educação Técnica da Couchbase e é responsável por toda documentação publicada, programas de treinamento e conteúdo, além da Couchbase Techzone.
***
Artigo original está disponível em: http://www.ibm.com/developerworks/br/library/ba-datamining/index.html

De 0 a 10, o quanto você recomendaria este artigo para um amigo?