



Criando um dataset de faces com Dlib
No seguinte artigo, Ítalo José apresenta um passo a passo ensinando a criar um dataset de faces com Dlib.


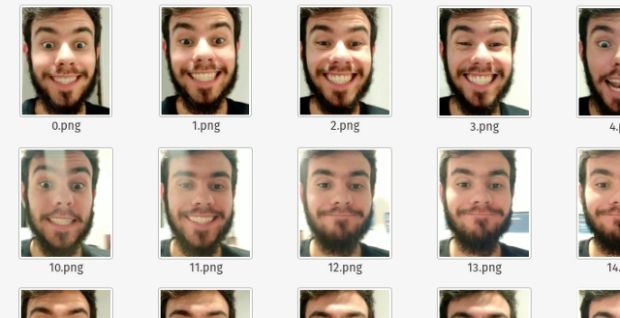
Em algum momento você já precisou criar um dataset de faces, como esse a seguir, e teve que sair recortando um monte de faces em diversas imagens? Bem, podemos fazer isso de forma automatizada!
Neste projeto criaremos um script para gerar um dataset cheio de faces a partir de um vídeo ou uma pasta cheia de fotos de pessoas aleatórias (ou não).
Nele teremos duas dependências:
- OpenCV
- Dlib
Como todos já sabem, o OpenCV é uma biblioteca de visão computacional – é ela quem vão nos ajudar a manipular nossa imagem no Python.
O Dlib também é uma biblioteca contendo N algoritmos e modelos de Machine Learning prontos. No caso de hoje, usaremos sua feature de reconhecimento facial!
Vamos ao código!
Para simplificar, farei tudo em um script só – assim fica algo mais simples e didático.
Para começar já vamos importar todas as bibliotecas e parâmetros que precisamos para rodar nosso script.
from pathlib import Path
import numpy as np
import argparse
import dlib
import cv2
import sys
import os
ap = argparse.ArgumentParser()
ap.add_argument("-v", "--input_video", type=str, required=False,
help="path to input video")
ap.add_argument("-f", "--input_folder", type=str, required=False,
help="path to folder images")
ap.add_argument("-o", "--output", type=str, required=True,
help="path to output directory of cropped faces")
ap.add_argument("-s", "--skip", type=int, default=5,
help="# of frames to skip before applying face detection")
args = vars(ap.parse_args())Algumas explicações sobre os parâmetros:
- input_video: aqui será imputado o path do seu vídeo, caso queria criar seu dataset a partir de um vídeo
- input_folder: aqui será imputado o path de uma pasta cheia de fotos com faces, caso queria criar seu dataset a partir de várias fotos
- output: esse será a pasta onde vamos deixar o script “cuspir” as faces recortadas
- skip: dentro de um vídeo, nós temos 24 frames em 1 segundo, né? Porém se você parar pra pensar, o frame 1 é muito parecido com o frame 2, que é muito parecido com o frame 3, mas o frame de número 1 é diferente do frame de número 4, Existem casos em que não precisamos de um dataset cheio de imagens repetidas, pois você pode enviesar seu modelo com isso. Para resolver esse problema, podemos ignorar alguns frames, trabalhando em um FPS menor. O parâmetro skip serve para indicar a quantidade de frames que queremos pular entre uma extração de face e outra
#1
if not args["input_video"] and not args["input_folder"]:
print('--input_video or --input_folder is required')
sys.exit()
#2
path = Path(args["output"])
path.mkdir(parents=True, exist_ok=True)Depois de receber os inputs do nosso script, faremos algumas validações e veremos se está tudo certinho.
- 1 – Aqui vemos que pelo menos algum input foi dado
- 2 – Independente do input, faces serão criadas em algum lugar, e caso nossa pasta de output não exista, devemos cria-lá para que não aconteça nada de errado ao salvar nossos dados tão queridos
Mas agora começaremos com o processamento do nosso vídeo!
def process_video(video_stream, output, skip):
vs = cv2.VideoCapture(video_stream)
read = 0
processed = 0
# Getting the folder lenth to give a name for our future image face
len_folder = len(os.listdir(output))
# loop over frames from the video file stream
while True:
(success, frame) = vs.read()
# if the frame was not grabbed, then the video was finished
if not success:
break
# increment the total number of frames read thus far
# it will help us to skip some frames
read += 1
# verify if we should process this frame or not
if read % skip != 0:
continue
path2save = os.path.sep.join([output,
"{}.png".format(len_folder+processed)])
save_faces(frame, path2save)
processed+=1
# do a bit of cleanup
vs.release()
Temos nosso método process_video() e agora vamos explicar como ele funciona:
Parâmetros:
- video_stream: aqui recebemos nosso vídeo – ainda é apenas um mero path
- output: nem preciso dizer muito, né? Aqui serão salvos nossos rostinhos
- skip: esse carinha nos informará de quantos em quantos frames deveremos trabalhar
Linha 2—9
- vs: para começar, abrimos nosso “vídeo stream” com
cv2.VideoCapture()para dentro da nossa variável vs - read: essa variável nos ajudará a saber quando devemos pular o frame atual
- processed: usaremos o valor desse carinha para nomear cada uma das imagens do nosso dataset. Você verá ela melhor mais pra frente
- len_folder: assim como o
processed, usaremos esse valor para a nomeação dos arquivos salvos dentro do nossos dataset
Linha 10–15
Aqui começamos a ler nosso vídeo de forma incansável até que o vídeo acabe.
E como sabemos que o vídeo acabou? Bem, nós verificamos a variável success. Enquanto essa variável continuar None (nula), teremos uma imagem (frame) dentro da variável frame.
Linha 19–29
Aqui é onde a mágica começa. Antes de tudo, verificamos se processaremos esse frame ou não. Lembra que se você trabalhar com todos os frames você irá obter um dataset cheio de imagens parecidas? Pois bem, na linha 22 nós verificamos se o resto da divisão da quantidade de frames já lidos, dividido pela quantidade de frames que queremos pular, dá 0.
Confuso, né? Se não entendeu, não se preocupe. Só entenda que aí é onde pulamos alguns frames do nosso vídeo.
Note que na linha 25 temos um método chamado save_faces(). Desculpe, confesso que não fui muito criativo na escolha desse nome, mas é nele que faremos a extração da nossa face. Porém, vamos abordá-lo em um outro momento.
A linha 26 é bem fácil, né? Estamos contabilizando quantas imagens foram salvas no nosso dataset. No final desse loop todo, simplesmente fechamos nossa stream.
def rotate(image, times):
return np.rot90(image, times)
def save_faces(frame, output, verbose=False):
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
detector = dlib.get_frontal_face_detector()
rects = detector(gray, 0)
i=1
while len(rects) is 0 and i<4:
gray = rotate(gray,1)
frame = rotate(frame,1)
rects = detector(gray, 0)
i+=1
for (_, rect) in enumerate(rects):
l_x = int(rect.tl_corner().x - rect.tl_corner().x*0.1)
t_y = int(rect.tl_corner().y - rect.tl_corner().y*0.2)
r_x = int(rect.br_corner().x + rect.br_corner().x*0.1)
b_y = int(rect.br_corner().y + rect.br_corner().y*0.1)
face_image = frame[t_y:b_y , l_x:r_x, :]
cv2.imwrite(output, face_image)
# TODO: receive it by shell parameter
if verbose:
print("[INFO] saved {}".format(path))Agora vamos falar sobre esses dois métodos:
rotate()
Ele é bem simples – basicamente recebe uma matriz do tipo numpy (uma imagem) como parâmetro e rotaciona ela em 90º em X vezes, então se você quiser rotacionar essa imagem em 180º, basta pedir para que seja rotacionada essa matriz (imagem) em 90º duas vezes.
save_faces()
E finalmente o método save_faces(). Vamos começar falando dos parâmetros:
- frame: obviamente, nossa imagem.
- output: nosso path de saída. Porém, agora não só a estrutura de pastas, mas, sim, o path completo da imagem de saída. Por exemplo: /home/italojs/pictures/124.jpg
- verbose: caso esse booleano seja True, imprimiremos uma informação no terminal dizendo que escrevemos nossa imagem com apenas a face de uma pessoa no disco.
Como a função é um pouco grande, vou usar “#” para me referenciar às linhas, tudo bem?
- #6:
gray. Para começar vamos transformar nossa imagem em preto e branco, pois não somos obrigados a trabalhar com três canais (RGB) de informação, né? - #8,9: depois de obtermos nosso
detector, através desse método nós vamos obter os retângulos de todas as nossas faces. - #12: caso estejamos trabalhando com uma imagem que não está na orientação correta – ou seja, em pé, o dlib não conseguirá identificar face alguma. Nesse caso, precisaremos rotacionar essa imagem, então a regra aqui é: enquanto não forem retornados retângulos para nós, ou caso já tenhamos rotacionado a nossa imagem três vezes, nós vamos rotacionar essa imagem em 90º e tentar mais uma vez achar faces nessa imagem.
- #18: aqui é o seguinte: caso o dlib tenha encontrado faces em nossa imagem, ele nos retornará um objeto rectangles que contém uma série de objetos do tipo
rectanglee, não, isso não é um array, é um objeto “rectangles” que contém objetos “rectangle”. Para saber mais, você pode consultar a documentação. Vamos iterar sobre esses rectangles, e para cada um desses objetos (rectangles correspondem à faces, tudo bem?) faremos o recorte com seus respectivos XY que o dlib irá nos proporcionar.
Observação: aquelas multiplicações que faço nas linhas 19–22 servem para fazermos o recorte de um retângulo em cima da face em um tamanho maior do que o dlib nos retorna.
if args["input_video"]:
process_video(args["input_video"], args["output"], args["skip"])
if args["input_folder"]:
process_image_folder(args["input_folder"], args["output"])E voilà, começamos a brincadeira! Aqui temos dois métodos: o process_video(), que será responsável por processar nosso vídeo, e o process_image_folder(), que veremos como funciona mais tarde.
Agora é só rodar!
Vou colocar esse vídeo aqui para que sejam extraídas fotos da minha face. No caso, criaremos um dataset de faces felizes e faces tristes.

python3 face_generator.py --input_video feliz.mp4 --output ./datset --skip 10E então teremos o resultado abaixo:
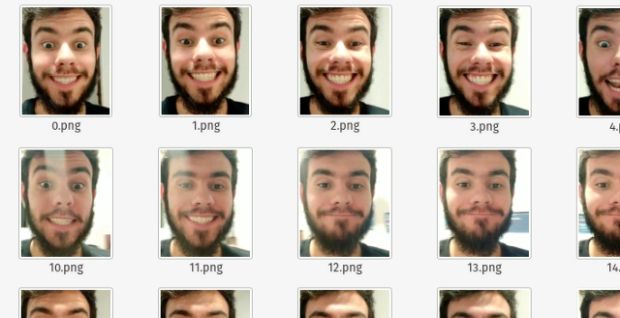
Agora vamos ver o seguinte caso:
Imagine que você quer trabalhar em cima de um dataset de imagens, com muitas imagens de pessoas, ou faces. Porém, essas imagens não estão de ponta cabeça – esse é o caso que vamos solucionar agora.
Olha essa imagem – eu tenho uma pasta cheia dessas fotos e quero extrair o rosto dessas fotos, porém, o dlib não trabalha com fotos sem estar na orientação certa (até trabalha, mas não encontra nenhuma face).

Observação: a foto ta borrada pois eu não tenho autorização para divulgar o documento dessas pessoas.
def process_image_folder(input_folder, output):
# TODO: make the saved and image_name global
processed = 0
len_folder = len(os.listdir(input_folder))
for name in os.listdir(input_folder):
path_image = os.path.join(input_folder, name)
if not os.path.isfile(path_image):
continue
path2save = os.path.sep.join([output,
"{}.png".format(len_folder+processed)])
save_faces(cv2.imread(path_image), path2save)
processed+=1Vai ser moleza!
Olha só, eu tenho quase a mesma estrutura que o “process_video”. Porém, aqui, ao invés de ler uma stream de um vídeo, eu itero sobre todos os arquivos que tenho em uma determinada pasta (linha #6), verifico se o item atual é um arquivo e mando a imagem pro save_faces().
Depois disso é só rodar nosso script. No entanto, com outro parâmetro: o --input_foldere sem o --skip.
python3 face_generator.py — input_folder ./images — output ./datsetSe você reparou, em nenhum momento parametrizamos o “verbose” de fato, mas isso vou deixar de lição de casa para que, além de copiar, você faça modificações no código para entendê-lo de fato.
O código completo (e mais estruturado) você encontra neste repositório do GitHub.
Valeu!
Engenheiro de visão computacional e deep learning na Nextcode, Microsoft MVP na categoria de AI e um dos Community Leads da comunidade do Facebook, o "developer circles". Vem compartilhando conteúdos técnicos sobre visão computacional, Machine Learning e Deep Learning pelo Brasil.




{kind=link}