



Como o algoritmo do Git-diff funciona?
Já parou pra pensar em como o Git Diff funciona? Neste artigo, Gabriel Schade apresenta uma explicação completa, contando como ele funciona de forma detalhada.


Olá, pessoal!
Já pararam pra pensar em como o Git Diff funciona? Ok, talvez não seja exatamente assim, mas o LCS (Longest Common Subsequence) é uma maneira de comparar textos. Vamos implementar?
Imagine o seguinte: o algoritmo vai comparar dois textos diferentes – isso pode ser um comentário, um artigo ou, no caso do Git diff, um trecho de código. Vamos usar como exemplo uma publicação em rede social.
Imagine que um usuário escreveu um post e logo depois fez uma pequena edição no texto para corrigir a data:
O cinema no sábado foi muito bom
O cinema na sexta foi muito bom
Ao aplicarmos o algoritmo proposto, teremos como resultado a maior subsequência nos dois textos, que neste exemplo é:
O cinema n_ ____ foi muito bom
Os underlines não fazem parte do resultado, mas acho que ajuda na visualização do que é descartado no processo.
Depois disso, podemos realizar novas comparações (não fazem parte deste algoritmo) para descobrir o que foi apagado e o que foi incluído.
Para descobrir o que foi apagado, basta identificarmos as diferenças entre a subsequência encontrada (o cinema n foi muito bom) e a string original (O cinema no sábado foi muito bom). Para descobrir o que foi incluído, fazemos o mesmo processo, desta vez comparando com a string editada (O cinema na sexta foi muito bom).
Neste artigo vamos focar em realizar a primeira operação, ou seja, encontrar a maior subsequência em dois textos, sem realizar as comparações.
Assim como foi visto no exemplo, a subsequência não precisa ser contínua – podem haver letras diferentes entre os caracteres comuns.
Outro ponto importante é que o objetivo é obter a maior subsequência (em quantidade de caracteres) – geralmente é possível encontrar mais de uma subsequência.
Veja o exemplo a seguir:
primeira string = "BMOAL"
segunda string = "BLOA"Neste exemplo temos a subsequência “BL”, mas o resultado esperado é “BOA”, que também é uma subsequência dos dois textos e possui mais caracteres.
Acho que já deu para entender o problema. Que tal começarmos a pensar na codificação?
Começaremos com uma palavra que assusta alguns programadores até hoje: recursividade. Sim, este é um algoritmo recursivo. Afinal, teremos que comparar letra por letra. Mas isso não vai ser um problema, confie em mim.
Lembre-se que precisamos comparar letra por letra, então vamos pensar nos casos usando as duas string anteriores como exemplo.
O primeiro caso:
As duas letras são iguais. Este é o caso mais simples e você já deve imaginar como resolvê-lo depois do spoiler do algoritmo ser recursivo.
Quando as letras são iguais, basta decompor o algoritmo, adicionando a letra ao resultado e continuando o cálculo excluindo a letra das duas strings.
A LCS de “BMOAL” e “BLOA” são equivalentes à “B” + LCS de “MOAL” e “LOA”.
LCS "BMOAL" "BLOA" = "B" + LCS "MOAL" "LOA"Focamos bastante no conceito, mas vamos pensar um pouco na estrutura de código. Criaremos uma função chamada “longest Common Subsequence Solve” – ela será responsável por resolver esse algoritmo.
Precisamos sinalizar em F# que a função é recursiva, então usaremos a palavra reservada rec. Além disso, também precisamos de dois parâmetros diferentes: um para a string original e outro para a string editada.
open System
let rec longestCommonSubsequenceSolve original edited =
//...Como vamos comparar letra por letra dentro da recursividade, também precisaremos de dois números inteiros para controlar o índice da letra em cada string.
open System
let rec longestCommonSubsequenceSolve original edited indexOriginal indexEdited =
//...Neste ponto, podemos criar uma facilidade para o programador que irá consumir essa função. Como os índices são utilizados apenas para controle interno, podemos criar uma função aninhada para esconder isso do programador que chama a função principal. Veja:
open System
let longestCommonSubsequenceSolve original edited =
let rec solve (original:string) (edited:string) indexOriginal indexEdited =
//...
solve original edited 0 0Desse jeito, tudo que a função longestCommonSubsequenceSolve fará, é repassar o problema para sua função aninhada solve, indicando os índices zero, e garantindo que a comparação completa será feita.
Criaremos mais duas facilidades para programarmos. A primeira delas é utilizar aplicação parcial na função solve para criar uma função derivada, onde só é necessário informar os índices – afinal, as strings de comparação não mudarão no meio do processo.
open System
let longestCommonSubsequenceSolve original edited =
let rec solve (original:string) (edited:string) indexOriginal indexEdited =
let solve' = solve original edited
//...
solve original edited 0 0Neste caso, poderíamos também omitir os parâmetros original e edited da função solve, afinal, ela teria acesso aos valores da mesma maneira, mas para evitar qualquer tipo de efeito colateral, é mais aconselhável manter as funções puras.
A segunda facilidade é a criação de um operador para concatenar um char com uma string. Ele também não é necessário, mas gosto da ideia de somar o resultado – me parece mais natural do que utilizar o sprintf.
open System
let (^) char string = sprintf "%c%s" char string
let longestCommonSubsequenceSolve original edited =
let rec solve (original:string) (edited:string) indexOriginal indexEdited =
let solve' = solve original edited
//...
solve original edited 0 0Agora podemos implementar o primeiro caso. Quando as duas letras comparadas forem iguais, simplesmente vamos adicionar a letra à solução e decompor o problema. Faremos isso com um pattern matching:
open System
let longestCommonSubsequenceSolve original edited =
let rec solve (original:string) (edited:string) indexOriginal indexEdited =
let solve' = solve original edited
match original, edited with
| original', edited'
when original'.Chars(indexOriginal) = edited'.Chars(indexEdited) ->
original'.Chars(indexOriginal) ^ (solve' (indexOriginal+1) (indexEdited+1) )
| _ -> String.Empty
solve original edited 0 0No primeiro caso estamos lidando com as duas letras iguais, mas precisamos fazer algo quando as letras forem diferentes umas das outras.
Neste caso, a solução é bifurcada, podendo tomar mais de um caminho. Vamos realizar a decomposição do problema como fizemos antes.
Até o momento estávamos neste ponto:
LCS "BMOAL" "BLOA" =
"B" + LCS "MOAL" "LOA"Agora “M” e “L” são letras diferentes – como continuamos? Na prática, é simples. Agora temos que seguir os dois caminhos alternativos:
- 1. Pulando a letra da primeira string
- 2. Pulando a letra da segunda string
Depois de calcularmos o resultado das duas opções, precisamos manter a maior subsequência encontrada. Simples, né?
LCS "BMOAL" "BLOA" =
"B" + LCS "MOAL" "LOA" =
"B" + Maior string entre { LCS "OAL" "LOA" e LCS "MOAL" e "OA"}Para o código, a solução é tão simples quanto parece. Resolvemos o primeiro caminho, depois o segundo, e retornamos a string resultante com o maior tamanho. Criaremos uma função aninhada para resolver o problema.
Nesta função aninhada, basta chamarmos a função solve’ duas vezes, adicionando um no índice de uma das strings em cada chamada, e depois disso, comparamos o tamanho e retornamos o maior.
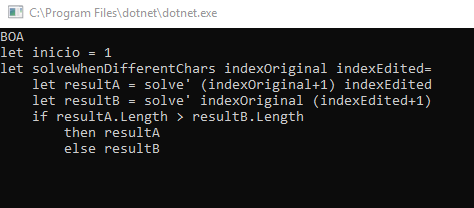
let solveWhenDifferentChars indexOriginal indexEdited=
let resultA : string = solve' (indexOriginal+1) indexEdited
let resultB : string = solve' indexOriginal (indexEdited+1)
if resultA.Length > resultB.Length
then resultA
else resultBNeste ponto você pode usar o sinal de maior ou igual também – isso só irá diferenciar em qual resultado tem prioridade quando ambos têm o mesmo tamanho, o que não é exatamente uma definição de certo e errado.
Agora incluiremos uma chamada para essa função aninhada lá no pattern matching:
let longestCommonSubsequenceSolve original edited =
let rec solve (original:string) (edited:string) indexOriginal indexEdited =
let solve' = solve original edited
let solveWhenDifferentChars indexOriginal indexEdited=
let resultA : string = solve' (indexOriginal+1) indexEdited
let resultB : string = solve' indexOriginal (indexEdited+1)
if resultA.Length > resultB.Length
then resultA
else resultB
match original, edited with
| original', edited'
when original'.Chars(indexOriginal) = edited'.Chars(indexEdited) ->
original'.Chars(indexOriginal) ^ (solve' (indexOriginal+1) (indexEdited+1) )
| _ -> solveWhenDifferentChars indexOriginal indexEdited
solve original edited 0 0Por fim, temos de fazer a implementação do último e mais simples caso, quando as strings chegam no fim. Para isso, basta fazermos uma comparação simples com o índice e podemos retornar uma string vazia. Afinal, se uma das strings chegou ao fim, não haverá mais nada em comum.
let longestCommonSubsequenceSolve original edited =
let rec solve (original:string) (edited:string) indexOriginal indexEdited =
let solve' = solve original edited
let solveWhenDifferentChars indexOriginal indexEdited=
let resultA : string = solve' (indexOriginal+1) indexEdited
let resultB : string = solve' indexOriginal (indexEdited+1)
if resultA.Length > resultB.Length
then resultA
else resultB
match original, edited with
| original', edited'
when indexOriginal = original'.Length || indexEdited = edited'.Length ->
String.Empty
| original', edited'
when original'.Chars(indexOriginal) = edited'.Chars(indexEdited) ->
original'.Chars(indexOriginal) ^ (solve' (indexOriginal+1) (indexEdited+1) )
| _ -> solveWhenDifferentChars indexOriginal indexEdited
solve original edited 0 0E pronto, temos nosso algoritmo pronto para ser testado!
[<EntryPoint>]
let main argv =
longestCommonSubsequenceSolve "BMOAL" "BLOA"
|> Console.WriteLine
Console.ReadKey() |> ignore
0O resultado deve sair como o esperado! Que tal fazermos mais um teste, agora jogando um trecho de código?
[<EntryPoint>]
let main argv =
longestCommonSubsequenceSolve "BMOAL" "BLOA"
|> Console.WriteLine
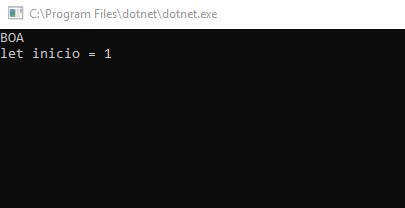
longestCommonSubsequenceSolve "let inicio = 10" "let inicio = 125"
|> Console.WriteLine
Console.ReadKey() |> ignore
0Já conseguimos ver o resultado esperado!
Agora vamos testar uma última vez. Dessa vez, com um trecho de código de uma função completa. Vamos criar duas versões diferentes da função solveWhenDifferentChars – uma delas declarando os resultados como string (como foi implementado) e na outra usando um ToString() na comparação do tamanho das strings:
longestCommonSubsequenceSolve
"""
let solveWhenDifferentChars indexOriginal indexEdited=
let resultA : string = solve' (indexOriginal+1) indexEdited
let resultB : string = solve' indexOriginal (indexEdited+1)
if resultA.Length > resultB.Length
then resultA
else resultB
"""
"""
let solveWhenDifferentChars indexOriginal indexEdited=
let resultA = solve' (indexOriginal+1) indexEdited
let resultB = solve' indexOriginal (indexEdited+1)
if resultA.ToString().Length > resultB.ToString().Length
then resultA
else resultB
"""
|> Console.WriteLineFuncionou? Funcionar, funcionou – mas ficou bem lento.
Podemos resolver isso com a chamada Programação Dinâmica, que possui algumas características, mas a mais simples dela é armazenar os resultados intermediários para não termos que calcular de novo.
Faremos isso criando uma matriz de cache. Sim, ela precisa ser mutável, e olha só: quando isso é algo controlado, não é um crime. Mas sempre que possível, evite.
Essa matriz de cache funciona da seguinte maneira: armazenaremos o resultado da LCS sob duas letras específicas. Cada letra já possui um índice dentro da palavra (indexOriginal e indexEdited em nosso código), e dessa forma, utilizaremos o índice da primeira letra como linha da matriz e o índice da segunda como coluna.
Por exemplo: nas palavras “BMOAL” “BLOA”, o resultado da primeira comparação será armazenado em [0,0]. O resultado de “M” e “L”, será armazenado em [1,1], de “M” e “O” em [1,2] e assim por diante.
Vamos adicionar o parâmetro para a função, iniciar uma matriz de strings vazias e renomear as funções para diferenciá-las da original:
let longestCommonSubsequenceSolveWithCache (original:string) (edited:string) =
let rec solveWithCache
(original:string) (edited:string) (cache:string[,])
indexOriginal indexEdited =
let solveWithCache' = solveWithCache original edited cache
let solveWhenDifferentCharsWithCache indexOriginal indexEdited =
let resultA : string = solveWithCache' (indexOriginal+1) indexEdited
let resultB : string = solveWithCache' indexOriginal (indexEdited+1)
if resultA.Length >= resultB.Length
then resultA
else resultB
match original, edited with
| original', edited'
when indexOriginal = original'.Length || indexEdited = edited'.Length ->
String.Empty
| original', edited'
when original'.Chars(indexOriginal) = edited'.Chars(indexEdited) ->
original'.Chars(indexOriginal) ^ (solve' (indexOriginal+1) (indexEdited+1) )
| _ -> solveWhenDifferentCharsWithCache indexOriginal indexEdited
let mutable cache =
Array2D.init original.Length edited.Length
(fun linha coluna -> String.Empty)
solveWithCache original edited cache 0 0Agora criaremos mais uma função aninhada para realizar o armazenamento dos resultados intermediários:
let cacheResult indexOriginal indexEdited value =
cache.[indexOriginal,indexEdited] <- value
value
let cacheResult' = cacheResult indexOriginal indexEditedComo você pode ver, já fizemos uma versão derivada da função informando os índices. Dessa forma, só precisamos identificar o valor que estamos armazenando.
Note também que, após realizar o armazenamento na matriz, retornamos o valor armazenado. Isso facilita a composição e diminui a quantidade de alterações que precisamos fazer em nosso código.
Agora precisamos utilizar essa função todas as vezes que calculamos um resultado. Primeiro vamos alterar o pattern matching, tanto no caso de quando as letras são iguais, quanto no caso em que as letras são diferentes:
match original, edited with
| original', edited'
when indexOriginal = original'.Length || indexEdited = edited'.Length ->
String.Empty
| original', edited'
when original'.Chars(indexOriginal) = edited'.Chars(indexEdited) ->
cacheResult'
(original'.Chars(indexOriginal)
^ (solveWithCache' (indexOriginal+1) (indexEdited+1)) )
| _ ->
cacheResult' (solveWhenDifferentCharsWithCache indexOriginal indexEdited)Por fim, precisamos adicionar mais um caso para o pattern matching: o caso onde a matriz de cache já contém o resultado que estamos calculando:
match original, edited with
| original', edited'
when indexOriginal = original'.Length || indexEdited = edited'.Length ->
String.Empty
| original', edited'
when cache.[indexOriginal, indexEdited] <> String.Empty ->
cache.[indexOriginal, indexEdited]
| original', edited'
when original'.Chars(indexOriginal) = edited'.Chars(indexEdited) ->
cacheResult'
(original'.Chars(indexOriginal)
^ (solveWithCache' (indexOriginal+1) (indexEdited+1)) )
| _ ->
cacheResult' (solveWhenDifferentCharsWithCache indexOriginal indexEdited)Agora podemos testar mais uma vez!
Se tudo foi implementado corretamente, é provável que o resultado seja próximo do instantâneo. Essa ainda não é a melhor solução, porque pode ser gerado StackOverflow em textos muito grandes. Podemos contornar isso, mas por enquanto ficaremos por aqui!
Gostou desse tipo de artigo? Quer que eu implemente a próxima parte do diff? Me conte nos comentários.
Até mais!
Mestre em Computação Aplicada com foco em Inteligência Artificial, Microsoft MVP, revisor no periódico científico Pattern Recognition Letters, autor de 4 livros pela editora Casa do Código e livros independentes. Entusiasta de programação funcional, IA e do uso de tecnologia como empoderamento das pessoas.



