

Pessoal, abaixo segue um resumo sobre Oracle Partitioning utilizado no Oracle 10gR2. Este é um material com objetivo de “facilitar” a administração e implementação do Oracle partitioning. Todos os exemplos foram baseados em tabelas principais de um sistema Fiscal. Este é um procedimento para implementação do Particionamento em um ambiente SINGLE database, sem nenhuma tabela previamente particionada. Os exemplos citados são exclusivos da situação abaixo.
PS: Pode também ser utilizado no Oracle 11gR2.
Particionamento
Um requisito importante de ambientes de banco de dados de alta disponibilidade e alto desempenho, o particionamento divide tabelas e índices em componentes menores e mais gerenciáveis. O Oracle Database 10g oferece o Oracle Partitioning.com as mais amplas opções de métodos de particionamento disponíveis, incluindo intervalo (range), lista (list) e faixa (hash). Além disso, fornece partições compostos de dois métodos, como data da ordem (faixa) e região (lista) ou região (lista) e tipo de cliente (lista).
Vantagens
- Desempenho: Diminui tempos de consulta expressivamente;
- Aumento de Disponibilidade: Acesso 24 horas a informações críticas;
- Gerenciamento: Gerenciamento em “porções” menores de dados;
- Gerencia o ciclo de vida das Informações: Manutenção de dados antigos com eficiência e sem impacto para o ambiente;
- Consumo de Disco: Redução de espaço em disco com a utilização do recurso COMPRESS;
- Redução de Riscos de Corrupção de Dados: Redução da possibilidade de corrupção de dados em várias partições;
- Backup / Recover: Otimização de backup e recover;
Pré-Requisitos
Oracle 10gR2 Enterprise Edition – With Partitioning;
Licença para uso da Versão Enterprise Edition com Particionamento;
Particionando Tabelas e Índices
Tabelas particionadas permitem que os dados sejam divididos em pedaços menores, simplificando a administração e acesso aos dados, esses pedaços são chamados partições. O Particionamento também pode melhorar a performance de modo que algumas queries podem simplesmente “ignorar” partições que não contenham os dados pesquisados. Desta maneira, uma consulta atua somente nos dados necessários para pesquisa, sem causar I/O desnecessário.
- Métodos de Particionamento: Existe alguns métodos de particionamento, abaixo uma breve eplicação:
- Intervalo (Range Partitioning): Particionamento por intervalos (Ex: Datas);
- Faixa (Hash Partitioning): Particionamento em faixas (Dados que não encaixam em listas ou ranges);
- Lista (List Partitioning): Particionamento em listas (Ex: Lista de Estabelecimentos);
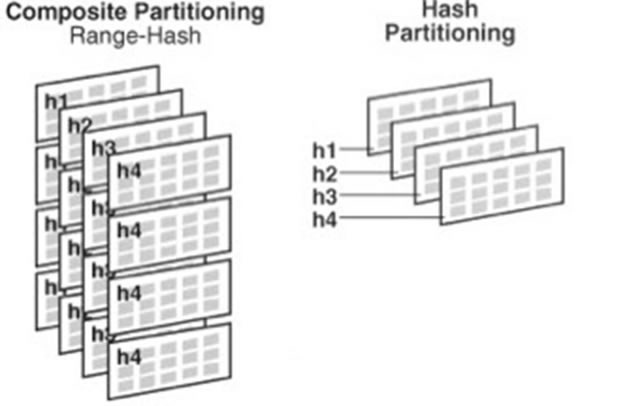
- Composto (Composite Partitioning): Particionamento Composto por 2 (dois) tipos (Ex: Range-Hash Partitioning);
Exemplo gráfico:
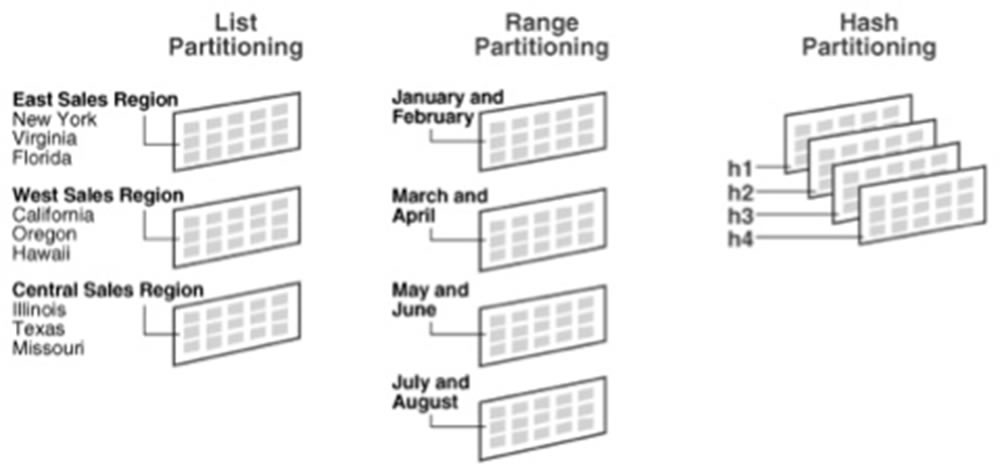
- Funcionamento e Benefícios: Em todos os métodos as tabelas são divididas em partições, como citado anteriormente. No caso do particionamento Não-Composto (apena 1 forma) as tabelas podem ser divididas em apenas 1 (um) método, o que facilita a administração, porém existem algumas desvantagens. Conforme análise feita no ambiente, juntamente com o time de AD da Synchro, recomenda-se utilizar o particionamento composto, visando melhora em:
- I/O: O consumo de I/O para estas tabelas fica distribuído em tablespaces específicas;
- Performance: Queries passam a usar o particionamento de forma omitizada;
- Espaço em Disco: Utiliza-se o recurso de compressão de dados afim de reduzir espaço do banco de dados;
Partition Wise-Joins
O Recurso de Partition-Wise Joins consiste em nada mais do que utilizar campos entre 2 tabelas que se relacionam, visando otimizar acesso entre os índices criados para esses campos entre 2 ou mais tabelas.
Mesmo que somente 1 tabela utilize o particionamento, a tabela que “busca” os dados, através de JOINS, utilizará a partição co-relacionada, otimizando assim o acesso.
Exemplos de Implementação
Abaixo as recomendações para particionamento e compressão de dados em tabelas relevantes:
- Opções de Particionamento: As opções recomendadas são:
- Intervalo-Faixa (Range-Hash Partitioning): Utilizado em tabelas que possuem apenas 1 tipo de “intervalo” de dados. (Ex: Data).
Neste cenário, recomenda-se incluir todas as tabelas que possuem dados históricos apenas filtrados por data, juntamente com um código PK (composta ou não).
Exemplo
Particionar tabela COR_DOF por intervalo de DATA (DT_FATO_GERADOR_IMPOSTO) x CÓDIGO PK (CODIGO_DO_SITE e DOF_SEQUENCE) onde:
- Intervalo de Data dividido a cada 1 ano, onde cada ano da tabela possui 4 partições 1 partição por ano.
- Faixa de CODIGOS PK (CODIGO_DO_SITE e DOF_SEQUENCE) divididos em 6 sub-partições (SP1, SP2, SP3, SP4, SP5, SP6)
- Faixa (Hash Partitioning): Utilizado em tabelas que possuem apenas 1 tipo de faixa de dados fixo.
Neste cenário, recomenda-se incluir a tabela COR_IDF, visando otimizar “JOINS” com a tabela COR_DOF, utilizando o recurso de Partition-Wise Joins.
Exemplo:
Particionar tabela COR_IDF por faixa de CÓDIGOS PK (CODIGO_DO_SITE e DOF_SEQUENCE):
- Faixa de CÓDIGOS PK (CODIGO_DO_SITE e DOF_SEQUENCE) divididos em 6 sub-partições (SP1, SP2, SP3, SP4, SP5, SP6)
Exemplo gráfico:
COR_DOF COR_IDF
** É importante destacar que o método de particionamento implica no tamanho e volume de dados de cada partição
- Visão Geral do Particionamento
| Tabela | Partição | Subpartição | Observação |
| COR_DOF | A2008 | A2008_SP1 | Partição Referente ao ano de 2008 |
| A2008_SP2 | |||
| A2008_SP3 | |||
| A2008_SP4 | |||
| A2008_SP5 | |||
| A2008_SP6 | |||
| A2009 | A2009_SP1 | Partição Referente ao ano de 2009 | |
| A2009_SP2 | |||
| A2009_SP3 | |||
| A2009_SP4 | |||
| A2009_SP5 | |||
| A2009_SP6 | |||
| A2010 | A2010_SP1 | Partição Referente ao ano de 2010 | |
| A2010_SP2 | |||
| A2010_SP3 | |||
| A2010_SP4 | |||
| A2010_SP5 | |||
| A2010_SP6 | |||
| A2011 | A2011_SP1 | Partição Referente ao ano de 2011 | |
| A2011_SP2 | |||
| A2011_SP3 | |||
| A2011_SP4 | |||
| A2011_SP5 | |||
| A2011_SP6 | |||
| A2012 | A2012_SP1 | Partição Referente ao ano de 2012 | |
| A2012_SP2 | |||
| A2012_SP3 | |||
| A2012_SP4 | |||
| A2012_SP5 | |||
| A2012_SP6 | |||
| A2013 | A2013_SP1 | Partição Referente ao ano de 2013 | |
| A2013_SP2 | |||
| A2013_SP3 | |||
| A2013_SP4 | |||
| A2013_SP5 | |||
| A2013_SP6 | |||
| A2014 | A2014_SP1 | Partição Referente ao ano de 2014 | |
| A2014_SP2 | |||
| A2014_SP3 | |||
| A2014_SP4 | |||
| A2014_SP5 | |||
| A2014_SP6 | |||
| F_ANOS | F_ANOS_sp1 | Partição Referente aos anos futuros | |
| F_ANOS_sp2 | |||
| F_ANOS_sp3 | |||
| F_ANOS_sp4 | |||
| F_ANOS_sp5 | |||
| F_ANOS_sp6 |
| Tabela | Partição | Subpartição | Observação |
| COR_IDF | P1 | – | Partição 1 |
| P2 | – | Partição 2 | |
| P3 | – | Partição 3 | |
| P4 | – | Partição 4 | |
| P5 | – | Partição 5 | |
| P6 | – | Partição 6 |
- Tabelas
Abaixo a lista de tabelas onde foi utilizado o particionamento:
Tablespace Usuario Nome Tipo Tamanho (GB)
--------------- ------- ---------- ---- ------------
DATA_SYNCHRO FISCAL COR_DOF TABLE 33
COR_IDF TABLE 44
------------
314
- Tabelas com Restrição
Abaixo a lista de objetos restritos à utilização de particionamento:
TABLE_NAME COLUMN_NAME DATA_TYPE ------------------ ---------------------- ---------- COR_DOF_APROVACAO CRITICA LONG SQLN_EXPLAIN_PLAN OTHER LONG OBR_GER_PROTOCOLOS RESUMO LONG ETAX_DOFIDF_DEBUG CONTEUDO LONG SYN_CUSTOMIZACAO CODIGO_CUSTOMIZADO LONG SYN_HTML_ARQ_ESTILO ESTILO LONG
* Estes objetos não podem ser particionados devido ao fato de possuírem campos com o tipo de dados LONG.
- Índices Recomendados: Todos os índices das tabelas com particionamento devem ser recriados a fim de otimizar a utilização do particionamento. Os índices devem ser criados da seguinte maneira:
- Gerenciamento Local: Na criação, o índice deve ser criado com a mesma estrutura de particionamento da tabela, respeitando partições e sub-partições (CREATE INDEX ….. LOCAL);
- Tablespace Exclusiva: Deve existir pelo menos 1 (uma) tablespace exclusiva para Índices;
- Índices com Restrição: Tabelas sem particionamento não suportam índices particionados.
- Performance: Com a utilização do particionamento, a performance tende a melhorar. De qualquer forma existem algumas observações importantes:
- Alteração em Código PL/SQL: É importante lembrar que o Oracle inicialmente não necessita de alterações de código SQL (Aplicação) para funcionamento do Partitioning. De qualquer forma, alterações no código podem ajudar expressivamente a performance de consultas. Abaixo exemplo:
SELECT * FROM COR_DOF PARTITION (a2011);
SELECT * FROM COR_IDF PARTITION (p1);
Quando especificado o nome da partição, o banco de dados pode obter melhor performance em consultas.
- Compressão de Dados
Juntamente com o particionamento, pode ser utilizado a compressão de dados antigos. A Compressão melhora a performance em consultas, porém existe um aumento de mesma proporção no processamento do servidor onde está alocado o banco de dados.
Abaixo um resumo de utilização de compressão de dados:
| Tabela | Compressão | Índices | Redução |
| COR_DOF | A2008 | Sem Compressão | de 40GB para 38GB |
| A2009 | |||
| A2010 | |||
| COR_IDF | Completa | Sem Compressão | de 44GB para 30GB |
Ganho final em espaço: 16GB
* O trabalho de performance deve ser feito diariamente após a implementação do Partitioning, monitorando o banco de dados a fim de encontrar melhorias.
** Para que novos dados sejam inseridos utilizando o recurso de compressão, o hint
/*+ APPEND */ deve ser utilizado nos comandos INSERT, caso contrário os dados serão inseridos SEM o recurso de compressão.
*** Os índices não possuem compressão, pois a performance degrada com a utilização deste recurso. Os índices serão atualizados sem o recurso de compressão.
**** Caso seja necessário adicionar campos em tabelas que possuem o recurso de particionamento, deve-se utilizar a cláusula UPDATE INDEXES ao final do comando ALTER TABLE. Esta cláusula visa atualizar os índices da tabela alterada.
Testes de Performance
Abaixo estão relacionadas algumas consultas e processos com seus respectivos tempos de execução sem particionamento e com particionamento:
* É importante observer que em alguns casos, a performance não se altera, mantendo o mesmo tempo de execução de uma determinada query.
TABELAS: COR_DOF / COR_IDF
SELECT d.dof_sequence
FROM FISCAL.COR_DOF D, FISCAL.coR_idf idf
WHERE D.CODIGO_DO_SITE(+) = IDF.CODIGO_DO_SITE
AND D.DOF_SEQUENCE = IDF.DOF_SEQUENCE
AND d.informante_est_codigo like '1075%'
AND IDF.DOF_SEQUENCE IS NULL --77984
/
TEMPO DE EXECUÇÃO SEM PARTITIONING: 24min
-----------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 33 | 0 (0)| |
|* 1 | FILTER | | | | | |
| 2 | NESTED LOOPS | | 6863K| 215M| 121K (4)| 00:24:22 |
| 3 | INDEX FULL SCAN | IDF_PK | 49M| 421M| 21200 (1)| 00:04:15 |
|* 4 | TABLE ACCESS BY INDEX ROWID| COR_DOF | 1 | 24 | 1 (0)| 00:00:01 |
|* 5 | INDEX UNIQUE SCAN | DOF_PK | 1 | | 1 (0)| 00:00:01 |
-----------------------------------------------------------------------------------------
TEMPO DE EXECUÇÃO COM PARTITIONING + COMPRESSÃO: 1:26min
--------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | Pstart| Pstop |
--------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 33 | 0 (0)| | | |
|* 1 | FILTER | | | | | | | |
| 2 | NESTED LOOPS | | 41524 | 1338K| 7159 (1)| 00:01:26 | | |
| 3 | PARTITION RANGE ALL | | 32343 | 758K| 687 (0)| 00:00:09 | 1 | 8 |
| 4 | PARTITION HASH ALL | | 32343 | 758K| 687 (0)| 00:00:09 | 1 | 6 |
| 5 | TABLE ACCESS BY LOCAL INDEX ROWID| COR_DOF | 32343 | 758K| 687 (0)| 00:00:09 | 1 | 48 |
|* 6 | INDEX SKIP SCAN | DOF_DT_EXT | 32343 | | 14 (0)| 00:00:01 | 1 | 48 |
| 7 | PARTITION HASH ITERATOR | | 1 | 9 | 1 (0)| 00:00:01 | KEY | KEY |
|* 8 | INDEX RANGE SCAN | IDF_CS_DS | 1 | 9 | 1 (0)| 00:00:01 | KEY | KEY |
--------------------------------------------------------------------------------------------------------------------
Crescimento Organizado
Uma das maiores vantagens da utilização do particionamento neste cenário é o crescimento organizado para futuras cargas no banco de dados, otimizando espaço em disco e visando performance para situações futuras onde o volume de dados será maior.
Implementação
A implementação do Oracle Partitioning impacta de forma completa a utilização dos objetos envolvidos. A estrutura de tabelas de índices é alterada completamente gerando indisponibilidade total de acesso aos mesmos.
É necessário uma janela de manutenção para a implementação destes recursos.
Para implementação é fundamental alguns itens, que devem ser previamente atendidos:
- Backup Completo: Backup completo do Ambiente de Banco de Dados;
- Implementação Partitioning: Alteração da estrutura de tabelas envolvidas;
- Validação do Ambiente: Validação do ambiente de Banco de Dados após a implementação do particionamento ;
- Testes por Usuáros: Validação do Sistema pelos usuários;
Conclusão
Após todos os itens anteriormente descritos, podemos concluir sobre a utilização da Feature Partitioning :
- É um recurso que traz benefícios ao ambiente de Banco de Dados;
- Visa o crescimento dos dados de forma organizada / otimizada;
- Otimiza tempos de pesquisa e acesso à dados;
- Permite o particionamento de objetos melhorando a performance;

De 0 a 10, o quanto você recomendaria este artigo para um amigo?