



Filegroup no SQL Server
Vamos falar sobre um assunto relativamente simples, porém, um assunto que ainda gera muitas dúvidas conceituais e de aplicabilidade, o destemido FILEGROUP.

Vamos falar sobre um assunto relativamente simples, porém, um assunto que ainda gera muitas dúvidas conceituais e de aplicabilidade, o destemido FILEGROUP.
O que é, porque e quando utilizar?Bom conceitualmente, FILEGROUP (FG), é uma estrutura lógica que mapeia o banco de dados e seus objetos relacionando com os Data Files (Arquivos de Dados MDF, NDFs).
Segundo o MSDN é:
“Every database has a primary filegroup. This filegroup contains the primary data file and any secondary files that are not put into other filegroups. User-defined filegroups can be created to group data files together for administrative, data allocation, and placement purposes.”
Como assim? Quando criamos o FG, informamos quais arquivos de dados estarão associados a ele, certo? Por exemplo, o Filegroup FG_TableBIG está associado aos arquivos de dados D:\bdteste02.ndf e F:\bdteste03.ndf.
Beleza, Luiz, mas para que serve o FILEGROUP na prática? Quando criamos um objeto, seja ele uma Table, Procedure, Index etc, ele é associado explicitamente ou implicitamente a um FILEGROUP que determina em quais Data Files aquele objeto estará fisicamente alocado.
Por exemplo, usando o case anterior, o Filegroup FG_TableBIG tem dois Data Files D:\bdteste02.ndf e F:\bdteste03.ndf, certo?
Ao criarmos a tabela dbo.Cliente associando ao FG_TableBIG, estaremos dizendo que este objeto estará alocado nos arquivos D:\bdteste02.ndf e F:\bdteste03.ndf, ou seja, toda informação inserida nesta tabela estará fisicamente nesses diretórios.
A distribuição dos dados entre os arquivos é realizada pela Engine do SQL Server com base no algorítimo de Proportional Fill, que é assunto para outro artigo, mas, podemos adiantar que esse algorítimo busca utilizar os dois arquivos proporcionalmente iguais, dividindo a carga de I/O e quantidade ocupada, porém, para isso acontecer tem uma série de observações referente a configuração dos Data Files, que irei abordar em um próximo artigo. Aqui um bom vídeo sobre o assunto.
A imagem a seguir exemplifica a associação entre FILEGROUP, Data Files e Objetos:
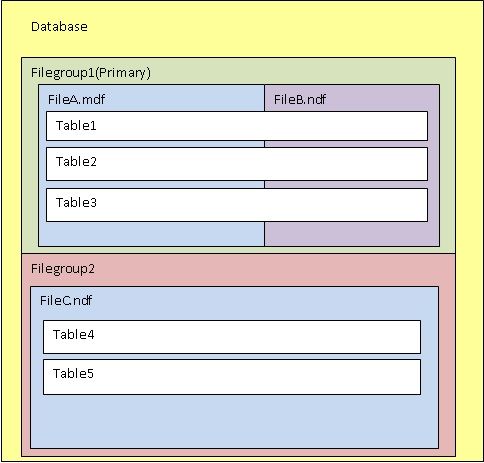
Por padrão, todo banco de dados possui o FILEGROUP PRIMARY e também, por padrão, todos os objetos de sistema estão mapeados nele. No SQL Server 2014 até 32,767 FILEGROUP podem ser criados por banco de dados.
Por default, o Data File MDF está associado ao FILEGROUP PRIMARY e, com isso, é uma boa pratica criar um novo FG associando a um Data File NDF para separação de objetos de sistemas e usuários.
Vamos para a prática:
1. Criando banco de dados com mais de um data file e associando a outro Filegroup:
CREATE DATABASE [DB01]
ON PRIMARY
(NAME = N'DB01', FILENAME = N'D:\DB01.mdf' , SIZE = 1048576KB , FILEGROWTH = 1024KB ),
FILEGROUP [FG_TableBIG]
(NAME = N'DB01_02', FILENAME = N'E:\DB01_02.ndf' , SIZE = 1048576KB , FILEGROWTH = 1024KB )
LOG ON
(NAME = ', FILENAME = N'L:\DB01_log.ldf' , SIZE = 1048576KB , FILEGROWTH = 10%)
GO
Podemos observar que existem dois FILEGROUP PRIMARY e FG_TableBIG e cada um contem seus respectivos arquivos de dados.
2. Adicionando um novo Data File, utilizando um Filegroup já existente no banco de dados:
ALTER DATABASE [DB01] ADD FILE ( NAME = N'DB01_03', FILENAME = N'E:\DB01_03.ndf', SIZE = 1048576KB , FILEGROWTH = 1024KB ) TO FILEGROUP [FG_TableBIG] GO
Ao executar esse script, adicionamos mais um arquivo de dados, associado ao FILEGROUP [FG_TableBIG].
3. Criando tabela e associando ao Filegroup [FG_TableBIG]:
USE DB01
GO
CREATE TABLE Table01
(
ID INT IDENTITY PRIMARY KEY ,
Nome VARCHAR(50) NOT NULL,
DTNascimento DATETIME NOT NULL
) ON FG_TABLEBIG
Observe que ao final do CREATE TABLE apareceu um comando novo, o ON. É neste ponto que especificamos qual será o FILEGROUP para a tabela. O que acontece se não especificarmos o FILEGROUP? A tabela será criada no FILEGROUP default, que neste exemplo será o PRIMARY.
4. Listando todos os objetos mapeados em cada Filegroup:
SELECT
name = left(o.name,30),
filegroup = s.groupname
FROM sysfilegroups S, sysindexes I, sysobjects O
WHERE I.indid < 2
AND I.groupid = S.groupid AND I.id = O.id
O result deste SELECT irá retornar todos os objetos contidos nos FILEGROUPs FG_TableBig e PRIMARY. Note que no primeiro, existe somente a tabela TB01 e no segundo todos os objetos de sistema do SQL Server para este banco de dados.
Quando é interessante criar mais de um Filegroup por Database?Como dito anteriormente, por padrão o banco de dados vem com o Filegroup PRIMARY e implicitamente todos os objetos de sistemas estão mapeados nele. É sempre uma boa pratica dividir objetos de sistemas de objetos de usuários (objetos criados posteriormente), por que Luiz? Primeiro pela organização do seu banco de dados, sendo assim também é uma boa pratica criar Filegroups para Índices e tabelas com muita carga de escrita e leitura, separando fisicamente esses objetos teremos ganhos no processamento de I/O. Além de estarmos mantendo o banco de dados estruturado da melhor forma possível.
Em segundo, tem a questão da utilização do algoritmo de Proportional Fill, que possibilita ganhos extremamente eficientes no quesito de performance. Além disso, existe a questão da contenção das páginas GAM e SGAM. Diminuindo o gargalho sobre estas páginas de sistema, é possível ganhos de performance. Mais sobre os conceitos de GAM, SGAM, aqui, aqui e aqui.
Além dos ganhos de performance mencionados, também existe o lado da recuperação em caso de desastre (Disaster Recovery), existindo a possibilidade de realizar o Restore a nível de Filegroup, diminuindo o tempo de RTO (Recovery Time Objective) e RPO (Recovery Point Objetive) e restabelecendo o banco de dados ou parte dele o mais rápido possível.
Uma vez que é possível realizar Restore de um Filegroup, então também é possível realizar backup. Existem casos em que o banco de dados é muito grande, passando da casa dos terabyte. Porém, uma boa parte dele são de dados históricos, que não são atualizados ou são atualizados muito raramente. Neste caso, o banco de dados poderia estar particionado (conceito aqui) e assim poderíamos criar uma lógica de backup mais inteligente e econômica, diminuindo GBs e tempo de execução.
Para finalizar, Filegroup é uma feature muito interessante que podemos utilizar para o bem do banco de dados e do DBA, auxiliando na administração e manutenção como um todo.
Espero que o conteúdo agregue conhecimento a vocês e que possam levar para o dia a dia.
Fico a disposição no e-mail luizh.rosario@gmail.com e também nos comentários aqui da página.
Bons estudos e até o próximo artigo!
Graduado em Ciência da Computação pela Universidade Paulista, possui artigos publicados em grandes eventos na área de Banco de Dados com foco em Alta Disponibilidade e Distribuição Geográfica dos Dados. Apaixonado por Banco de Dados e Motocicletas, é profissional certificado Microsoft e atual como DBA SQL Server e Sybase.


