



Escovando bit com operadores KEY Lookup e RID Lookup
O intuito desse artigo é explicar detalhes internos de dois operadores: Key e Rid Lookup.

O Query Optimizer (otimizador de consulta) do SQL Server é responsável por gerar os famosos planos de execução. Sempre que uma query é executada, o query optimizer analisa vários fatores como, índices, seletividade dos dados, quantidade e tamanho dos registros, pressão de CPU, memória, estatísticas (mais sobre estatísticas aqui e aqui) entre outros, e com base nessas informações é gerado o melhor caminho possível para buscar os dados. Esse caminho chamamos de plano de execução, que em baixo nível são os operadores responsáveis por realizar as operações descritas na Query, como Joins e ordenação.
Como o Query Optimizer escolhe e determina os operadores para o plano de execução vai ficar para um próximo artigo, pois engloba diversos assuntos que precisamos abordar. O intuito desse artigo é explicar detalhes internos de dois operadores: Key e Rid Lookup.
Key Lookup
O operador Key Lookup é utilizado para ler dados de campos que não estão no índice nonclustered. Como assim? Bom, sabemos que ao criarmos um índice nonclustered internamente ele armazena o campo chave dele e também o campo chave do índice clustered.
Exemplo 1:
A tabela produto possui os campos ProdID, ProdNome, ProdCat e ProdDate onde o campo ProdID é PK e também chave do índice clustered e o campo ProdCat é chave do nonclustered.
SELECT ProdID, ProdNome, ProdCat, ProdDate FROM Produto WHERE ProdCat = 1101 GO
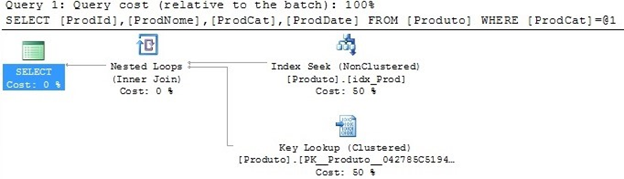
Observe que na Query os campos especificados são: ProdID, ProdNome, ProdCat e ProdDate. Internamente o Query Optimizer utilizou o índice idx_Prod para retornar os campos ProdCat (chave nonclustered) e ProdID (chave clustered) como já mencionado, todo índice nonclustered armazena também a chave do clustered. Porém, ainda é preciso retornar os campos ProdNome e ProdDate; pra isso o operador Key Lookup realizou uma varredura buscando no índice clustered esses dois campos.
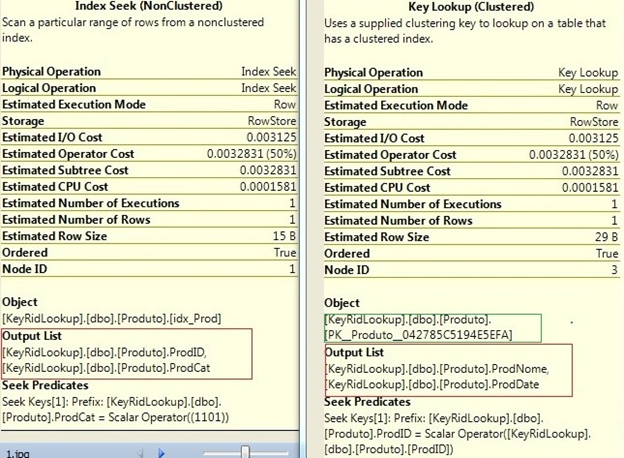
Nas propriedades dos operadores pode-se observar que o operador Index Seek (esquerda) utilizou o objeto idx_Prod (índice nonclustered) para retornar os campos ProdID e ProdCat. E analisando o operador Key Lookup (direita) podemos observar que utilizou o objeto PK__Produto__042785C5194E5EFA (índice cluster) e retornou os campos ProdNome e ProdDate.
Ok, mas por que o Key Lookup utilizou o índice clustered? Como sabemos, o clustered contêm todos os campos da tabela, por isso o Key Lookup vai buscar nele as informações que falta no índice nonclustered.
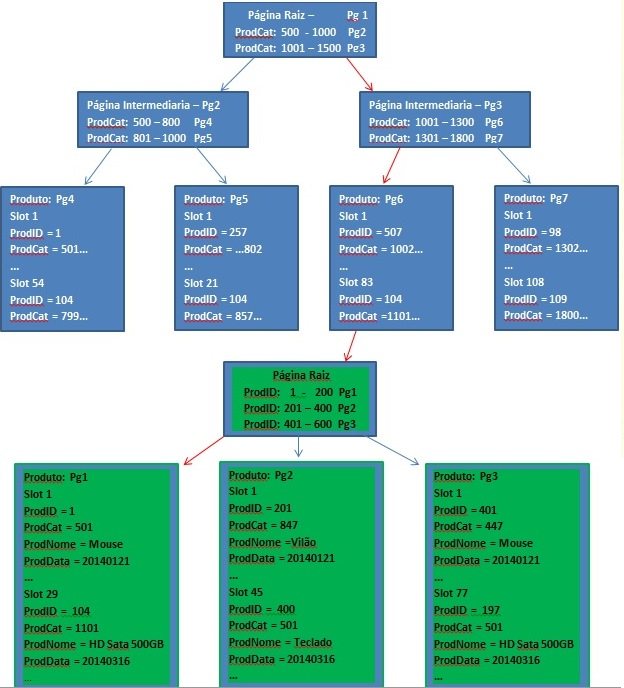
Como isso funciona internamente? Com a imagem a seguir, podemos ilustrar essa operação. A parte em azul representa o índice nonclustered, onde a chave é o ProdCat e em verde o índice clustered com ProdID como chave.
Vamos pensar como o Query Optimizer pra entender o key Lookup. A query tem a cláusula WHERE ProdCat=1101, e como existe um índice nonclustered (idx_Prod) neste campo, o otmizador optou por utilizá-lo. As setas vermelhas indicam o caminho percorrido.
Bom, seguindo o plano de execução, foi feito um Index Seek no índice nonclustered percorrendo as páginas. O ProdCat=1101 está entre 1001-1500? Sim, então vá para página 3; 1101 está entre 1001-1300? Sim, então vá para página 6. Na página 6 encontramos o ProdCat=1101 e também ProdID=104. Com essa informação vamos para a raiz do índice clustered (Key Lookup): ProdID=104 está entre 1-200? Sim, então vá para página 1. Pronto, neste nível encontramos a página onde está as informações que precisamos, os campos ProdNome e ProdDate.
Resumindo: O operador Index Seek utilizou o objeto idx_Prod para retornar os campos ProdID e ProdDate e posteriormente foi realizado um key Lookup no índice clustered buscando as informações dos campos ProdNome e ProdDate.
Rid Lookup
Assim como Key Lookup, o Rid Lookup é utilizado para ler dados de campos que não estão no índice nonclustered, porém, com uma diferença: Rid Lookup só é utilizado em tabelas HEAP. O que é isso? HEAP são tabelas sem índice clustered. Sempre que aparecer um Rid lookup no seu plano de execução significa que existe tabela sem índice clustered.
Neste caso, o índice nonclustered armazena uma chave RID hexadecimal que é composta pelo número do arquivo de dados + número da página + slot, ou seja, ela armazena o caminho físico da informação. Diferente de como é no Key Lookup, o nível folha/intermediário do nonclustered não aponta para a raiz do clustered e sim para o endereço físico no disco.
Exemplo 2:
Simulando o Rid Lookup
Verificando constraints: sp_helpconstraint Produto GO

Verificando Indexes: sp_helpindex Produto go

Excluindo constraint e índices:
DROP INDEX idx_Prod ON Produto -- índice nonclustered GO
ALTER TABLE dbo.Produto DROP CONSTRAINT PK__Produto__042785C5194E5EFA -- PK e índice clustered GO
sp_helpindex Produto GO
sp_helpconstraint Produto GO

Excluímos todos os índices e constraints. Agora a tabela Produto se tornou uma HEAP.
Observe o plano de execução para a consulta a seguir:
SELECT ProdID, ProdNome, ProdCat, ProdDate FROM Produto WHERE ProdNome = 'SQL Server 2014 CTP2' GO
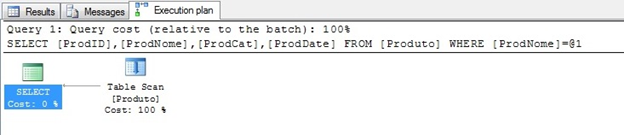
Como não existe nenhum índice na tabela, a única alternativa do otimizador é fazer um Table Scan percorrendo a tabela inteira em busca do nome ‘SQL Server 2014 CTP2’.
Agora, criando o índice no campo ProdNome, vamos ver o que acontece com a mesma query:
CREATE NONCLUSTERED INDEX idx_Produto01 ON Produto (ProdNome) GO
SELECT ProdID, ProdNome, ProdCat, ProdDate FROM Produto WHERE ProdNome = 'SQL Server 2014 CTP2' GO
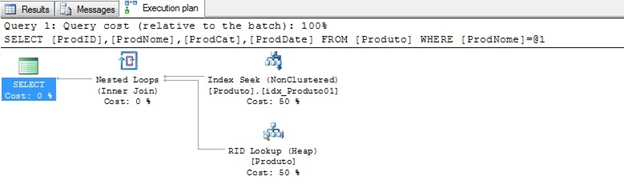
Observe que o plano de execução mudou. Agora temos um Index Seek no índice nonclustered e um Rid Lookup na HEAP.
O nonclusted da tabela Produto internamente possui os campos ProdNome(chave) e ProdID(chave cluster) certo? ERRADO. Lembre-se, a tabela Produto não tem índice cluster, ela é uma HEAP. Portanto, neste caso o índice idx_Produto01 contém o ProdNome e uma chave RID hexadecimal.
Ok, mas se não existe clustered, como que o Rid Lookup funciona? Assim que a página intermediária ou folha do índice nonclustered é acessada é encontrada a chave RID que é o ponteiro direto pra página de dados no disco.
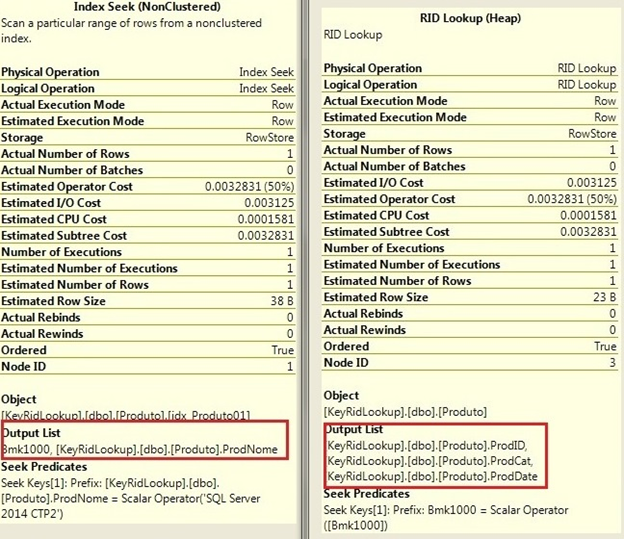
Conforme segue as propriedades dos operadores, podemos identificar que o Index Seek retornou somente o campo ProdNome e o Rid Lookup os campos ProdID, ProdCat e ProdDate.
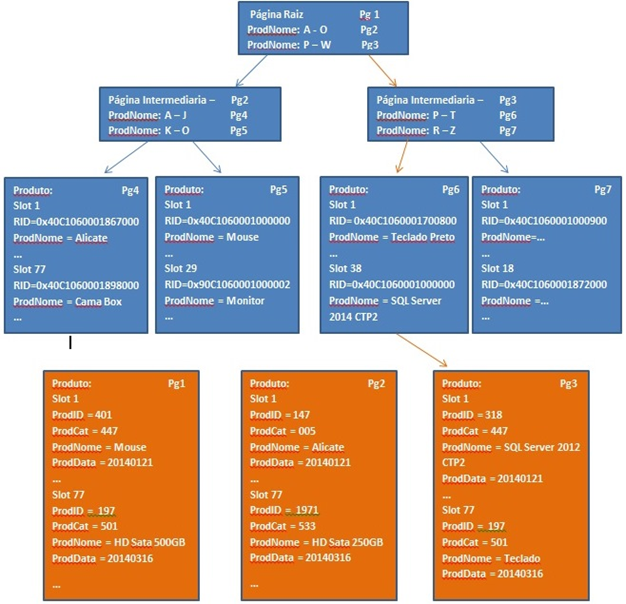
A imagem a seguir representa em azul o índice nonclustered e em laranja as páginas da tabela HEAP Produto.
Simulando os passos do otimizado de consulta, o operador Index Seek percorreu o índice nonclustered, Where ProdNome = ‘SQL Server 2014 CTP2’ está entre P e W? Sim, vá para página 3, está entre R e Z? Sim, vá para página 6. Neste ponto o campo ProdNome é retornado, porem ainda falta os outros, é nesse momento que o Rid lookup entra em ação. Observe que na página 6 existe a chave RID. E é com essa chave que o RID lookup encontra a página de dados onde está o restante das informações. Neste exemplo é a página 3 da tabela HEAP. Pronto, com o Rid lookup os campos ProdID, ProdCat e ProDate também são retornados, concluindo assim a consulta.
Conclusões
O Query Optimizer é uma parte complexa e de extrema importância dentro do SQL Server. Existem várias fases de verificações, validação, otimização até a geração do plano de execução. Neste artigo destacamos apenas dois operadores possíveis e podemos observar que o assunto é extenso.
Com esses testes, podemos concluir alguns pontos interessantes:
- Sempre que aparecer um RID Lookup no plano de execução, significa que existem tabelas HEAP.
- Em teoria e em alguns casos o RID lookup seria mais eficiente que o Key lookup, pois no RID o acesso é direto na página de dados, ao contrario do Key Lookup que percorre todo índice clustered até encontrar a página. Porém, os benefícios de se ter um clustered é tão grande que não compensa e não é aconselhável não criar um clustered na tabela. Existem casos e casos, mas 99% das vezes o ganho de se ter um clusterd é muito maior.
- Sempre que aparecer um Key Lookup, é sinônimo que existem campos na consulta que não estão cobertos por índices, nesse caso, é interessante verificar e analisar a possibilidade de incluir esses campos no índice.
Grande abraço e bons estudos.
Graduado em Ciência da Computação pela Universidade Paulista, possui artigos publicados em grandes eventos na área de Banco de Dados com foco em Alta Disponibilidade e Distribuição Geográfica dos Dados. Apaixonado por Banco de Dados e Motocicletas, é profissional certificado Microsoft e atual como DBA SQL Server e Sybase.


