



Como analisar o desempenho do SQL Server – Parte 06
Nesta última parte, vamos analisar os tipos de contadores de desempenho do SQL Server, os contadores de desempenho de IO, memória e CPU.

Nesta última parte do artigo sobre desempenho do servidor SQL Server, vamos analisar os tipos de contadores de desempenho do SQL Server, os contadores de desempenho de IO, memória e CPU. O anterior pode ser visto neste link.
Contadores de desempenho de uso do SQL Server
Pedidos em lote
Caso você precise de um contador para representar melhor o desempenho geral do seu servidor, processamento em lote é recomendado. Ele faz com que seja possível capturar a real carga de trabalho do servidor (quantas solicitações o aplicativo está fazendo), e como o servidor está lidando com a carga de trabalho. A análise desse contador precisa ser analisada mais adiante: o aumento do valor pode significar que o servidor tem um desempenho melhor, porque pode aceitar e lidar com mais solicitações, mas também pode significar que o aplicativo está enviando mais solicitações (carga de trabalho mais pesada), por exemplo, mais seu aplicativo está servindo, mais requisições do cliente.
Transações
O número de transações ativas (de qualquer tipo). Esteja ciente de que há pelo menos dois contadores que são chamados de Transactions, um no objeto SQL Server:General Statistics, e outro no objeto SQL Server:Transactions. Estou me referindo ao último. Saber o número de transações ativas é importante para definir um plano no seu entendimento da carga de trabalho.
Processos bloqueados
Isso é especialmente útil ao solucionar picos de desempenho ou desempenho irregular. Por exemplo, se puder correlacionar momentos em que o desempenho cai com momentos em que o bloqueio aumenta, pode ter encontrado uma área para focar sua investigação sobre problemas de desempenho: o bloqueio.
Erros
Entender se os erros ocorrem em sua carga de trabalho é um ponto-chave na solução de problemas de desempenho. Eliminar erros é um caminho fácil para aumentar por si só o desempenho do servidor.
Número de conflitos por segundo
Relacionado com o número de erros, monitorar a taxa de conflitos pode apontar rapidamente a direção a seguir para encontrar um problema de desempenho. É difícil acreditar que você não esteja ciente de que os conflitos estejam ocorrendo, dado o impacto que estes têm sobre a aplicação. Mas já vi casos em que os conflitos foram absorvidos na aplicação ou simplesmente não havia comunicação entre a organização e o controle da aplicação, ou simplesmente não havia um DBA para monitorar o servidor.
Crescimento do log
Mal posso pensar em qualquer outro evento em execução no SQL Server que tenha um impacto mais dramático no desempenho do servidor do que o crescimento do log de registro. Durante o crescimento do log, cada solicitação de gravação congela o servidor e aguarda o log ficar disponível para gravar os registros necessários novamente.
O crescimento do log não pode usar inicialização instantânea de arquivo, já que deve esperar até que o arquivo de log seja criado e o espaço em disco recém-alocado seja preenchido com zeros. Muitas vezes, o problema é agravado por um arquivo de log que está fora de controle, com incrementos de 10%, e que agora está crescendo em centenas de megabytes ou mesmo gigabytes de cada vez. O impacto no desempenho é geralmente devastador e também é difícil de rastrear quando sai do controle. O servidor mostra como um mergulho súbito de desempenho (na verdade, muitas vezes, sofre também um congelamento completo) que dura alguns segundos ou mesmo minutos, e então tudo volta a ser rápido até que o crescimento do log saia do controle novamente no próximo registro. O artigo Como reduzir o log do SQL Server oferece uma explicação dos motivos pelos quais o crescimento do log pode ocorrer. Os dados e o crescimento do log também podem ser acompanhados por valores diferentes de zero, caso o PREEMPTIVE_OS_WRITEFILEGATHER espere por informações contendo estatísticas.
Tamanho do(s) arquivo(s) de dados (KB)
Monitorar o tamanho do arquivo de dados é interessante por si só, mas há outra razão pela qual esse contador deve ser coletado: ele pode mostrar quando ocorrem eventos de crescimento do banco de dados. Ao contrário do crescimento do log, o crescimento dos arquivos de dados não tem um contador próprio (vergonha!). Mas os eventos podem ser deduzidos a partir de mudanças súbitas no tamanho do arquivo de dados. Note que o crescimento dos dados pode alavancar a inicialização instantânea de arquivo para que o impacto no desempenho não seja tão dramático. Você deve sempre garantir que a inicialização instantânea de arquivo está habilitada no SQL Server; caso contrário, o impacto pode ser grave, especialmente se você encontrar eventos de crescimento de arquivos TEMPDB (o que, na minha experiência, ocorre na maioria das implementações).
Contadores de desempenho relacionados a IO
Leituras de páginas por segundo
Trata-se da velocidade com que as páginas de dados são lidas a partir do disco. Esse será o fator principal para leitura do disco de IO. Normalmente, a carga de trabalho deve ler apenas uma pequena quantidade de dados do disco rígido, e os dados devem ser armazenados em cache na memória. A leitura constante desses dados é um sinal de varreduras completas de dados (o que indica, na maioria das vezes, índices ausentes) e/ ou memória insuficiente (RAM).
Flush de log por segundo
Trata-se do do tempo de espera para leitura e escrita em (ms). Você pode rapidamente ter uma ideia de quando o bloqueio ocorre devido a operações de espera para gravação de eventos no log. Para aplicações de uso intensivo com OLTP bem escritos, a taxa em que as transações podem gravar logs muitas vezes é o principal problema de desempenho.
Escrita de página por segundo
Intencionalmente incluo novos dados depois das gravações de log, porque, na maioria das vezes, o log é que é o problema. Apenas algumas cargas de trabalho são dados de escrita pesada. O restante é apenas log. Contudo, os dados de escrita podem interferir com IO de disco, especialmente sobre com gravações de log, e pode causar atrasos na escrita do log, o que acaba se tornando muito visível no desempenho, já que a velocidade do aplicativo cai. O padrão típico é de algum tempo com bom desempenho, seguido de tempos com queda de desempenho. Tempo é relativo: em algum momento, você vai achar 1-2 minutos um tempo muito longo e 10-15 segundos como um curto período de tempo, mas outras vezes 10-15 minutos serão espaços longos de tempo e 1-2 minutos serão um tempo curto. O padrão irregular é a chave, com uma forte correlação entre quedas de desempenho e dados sendo aguardados ou escritos. O padrão é causado por pontos de verificação e o momento para acionar o ponto de verificação pode ser ativado depois do intervalo de recuperação. Olhando para páginas de pontos de verificação por segundo, rapidamente corroboramos essa hipótese.
Páginas de pontos de verificação por segundo
Este contador é o culpado habitual pela queda de desempenho no contador de páginas gravadas.
Espera para gravação de log
Este contador de desempenho expõe a informação de espera durante as gravações de log. A vantagem de usar os contadores de desempenho contra os DMVs é aproveitar a infraestrutura dos contadores de desempenho, ou seja, recolher os valores de uma forma contínua usando os coletores do sistema operacional.
Página de trava de espera de IO
O mesmo que foi exposto para a espera de gravação do log, esta é um informação de espera medida através dos contadores de desempenho. Estritamente falando, isso não mede IO exatamente, só mede quando bloqueio causado por IO ocorre. Não será possível distinguir entre ler e escrever IO com este contador.
Velocidade de backup e restauração por segundo
Muitas vezes, os requisitos de IO das operações de backup de manutenção são esquecidos quando se faz análise de desempenho. Entendendo a pressão que sofre adicionalmente o IO durante a operação de backup e analisar o servidor através desse contador é importante por si só, mas é ainda mais importante para compreender a correlação entre picos desse contador e a degradação de desempenho geral do servidor. Este é um cenário que já vi muitas vezes: os picos de sobrecarga no plano de manutenção e no rendimento global do servidor fazem com que os problemas de desempenho aumentem significativamente, mas ninguém entende o porquê.
Objeto PhysicalDisk
Esta categoria é o contador de sistema operacional para monitorar as operações de IO. O foco não é exatamente a taxa de transferência, mas sim o comprimento da fila, indicando operações de IO que levam muito tempo para finalizar. Para uma explicação mais completa, leia Desempenho dos contadores do disco do Windows, Monitorando o uso e Monitorando o comprimento da fila. O sistema operacional expõe contadores de IO para cada unidade individual separadamente e sempre analisa esses dados juntamente com as próprias estatísticas de IO do SQL Server, conforme relatado pelo IO virtual Status DMVs. Outra boa fonte de leitura é esta wiki do SQL Server Technet: Monitoramento do uso do disco.
Processos/Operações de dados de IO por segundo
A categoria de contador de processo tem uma instância diferente para cada processo do sistema operacional em execução e é muito importante para analisar quando IO global do sistema não coincide com IO relatado pelo SQL Server. Muitas vezes, você vai descobrir que outro processo está causando problemas a IO, fazendo com que os discos fiquem ocupados e aumentando o tempo de resposta do SQL Server. Infelizmente, monitorar esse contador é difícil a longo prazo, porque as instâncias surgem conforme processos executáveis do sistema operacional, começam e terminam.
Página(s) por segundo
Apesar de estar na categoria de contador de memória, a compreender se e quando ocorre paginação no servidor é fundamental para entender o desempenho de IO e como a paginação pode introduzir um grande aumento nos pedidos de IO. Veja o documento Monitoramento da paginação.
Contadores de desempenho relacionados à memória
Expectativa de vida da página
A PLE (Page Life Expect) é utilizado para medir o tempo médio que uma página permanece em cache na memória antes de ser expulsa por causa da necessidade de ler mais dados do disco. O DBA pode dar a este contador um valor mágico de 300 (5 minutos). Isso é originado da regra dos 5 Minutos para negociação de acesso de memória no disco, artigo publicado em 1985, depois revisto como A regra dos Cinco Minutos Dez Anos Depois e novamente revista como A regra dos Cinco Minutos 20 Anos Depois. Neste último, publicado em 2011 na SQL Magazine Q&A, Paul Randal diz: “O valor de 300 segundos é uma recomendação da Microsoft em um documento que foi escrito há muitos anos. Não é uma orientação relevante nos dias de hoje e, até mesmo anos atrás, eu teria argumentado que apontar para um valor fixo não é uma recomendação válida”.
Analisar a PLE é útil, pois ela dá um valor único para começar a analisar a saúde da memória do servidor, mas não entre em pânico se o valor for 297 e relaxe se for 302… O mais importante é entender as tendências e a dinâmica desse valor. Um padrão irregular (depressões periódicas) indica algum evento que veio e criou um grande distúrbio na memória do servidor, talvez uma consulta periódica que fez uma varredura, expulsando grande parte dos dados em cache. Uma tendência geral na redução da PLE indica que sua carga de trabalho aumenta, mas o hardware do servidor é o mesmo e é um grande indicador de potenciais problemas futuros.
Em máquinas com nós NUMA, o que atualmente quer dizer praticamente todos os servidores, você deve prestar atenção na PLE por nó usando o SQL Server: Nó de Buffer/Página de contador de expectativa de vida. Leia também A expectativa de vida da página não é o que você pensa.
SQL Server: Gerenciador de memória
Esta categoria rastreia o quanto da memória é utilizado dentro dos processos do SQL Server. Os próprios valores absolutos são de algum modo exóticos, mas ter uma linha de base para comparação e olhar para as tendências coletadas em longo prazo é uma ótima maneira de determinar o que mudou e quais componentes do SQL Server devem ser colocados sob pressão para investigação de problemas de memória.
Concessão de memória pendente
Estou chamando este contador na categoria de gerenciamento de memória, porque é particularmente importante na compreensão do bloqueio causado pela espera de uma concessão de memória que ainda não foi atendida. Concessões de memória são necessárias somente para determinados operadores de consulta, e consultas que solicitam grandes concessões de memória tendem a causar estragos no seu desempenho do SQL Server. Leia Entenda a concessão de memória do SQL Server para obter mais detalhes.
Concessão de memória em fila espera
Relacionado ao contador anterior, este contador mostra a informação sobre as concessões de memória ainda pendentes.
Processos/Bytes Privados
A categoria Processos de contador de desempenho do sistema operacional tem uma instância para cada processo no sistema e permite que sejam acompanhados facilmente outros processos que podem consumir memória, fazendo com que a pressão da memória externa finalmente acarrete em degradação do desempenho.
Contadores de desempenho da CPU
Processador de objetos
Realmente espero que este contador não precise de uma explicação. O sistema operacional relata o uso da CPU.
Pesquisas de páginas por segundo
Estou mencionando este contador aqui, na categoria de CPU, porque ele é um contador crítico e que deve ser analisado quando se considera o uso da CPU no SQL Server. Quando este contador se correlaciona fortemente com o uso da CPU, fica clara a razão pela qual o uso da CPU aumentou: mais páginas foram digitalizadas, as consultas simplesmente analisam mais dados e, portanto, consomem mais CPU. O culpado habitual é, novamente, a varredura de tabela (problema que pode acontecer por índice ausente, modelagem de dados pobre ou um plano de consulta ruim).
Processos/% do tempo de processador
A categoria Processos de contador de desempenho do sistema operacional tem uma instância para cada processo no sistema e permite que sejam acompanhados facilmente outros processos que podem consumir CPU, causando a degradação de desempenho do SQL Server.
Bloqueio relacionado a contadores de desempenho do SQL Server
SQL Server: Bloqueios
Acompanhar e analisar o desempenho dos contadores de bloqueio pode revelar se o bloqueio está relacionado a algum motivo importante e que está causando problemas de desempenho. Verificar especialmente o valor do tempo de espera (em ms) te dará uma visão de quantos por cento do tempo estão sendo gastos com consultas que estão sendo bloqueadas à espera de desbloqueio de travas. Você não será capaz de determinar exatamente o que a consulta está bloqueando, mas saber que as esperas de bloqueio são significativas permite que você se concentre na análise das cadeias de blocos. A sp_whoIsActive é uma grande ferramenta para essa análise.
SQL Server: Estatísticas de espera
Também são relatadas como contadores de desempenho as informações que são importantes para os diversos tipos de espera. Analisar este contador é semelhante a analisar as estatísticas de espera usando as DMVs, mas os contadores de desempenho têm a vantagem de estarem disponíveis em todo o conjunto de ferramentas de contadores de desempenho do sistema, tornando fácil coletar, armazenar e analisar os dados. Nem todos os tipos de espera possuem informações expostas sob a forma de contadores de desempenho.
SQL Server: Travas
Se você obtiver valores altos no Average Latch Wait Time (ms), deve realizar uma investigação para encontrar o problema com a trava. Recomendo a leitura do artigo Diagnosticar e resolver travas de contenção no SQL Server.
Contadores de desempenho de rede
Dica de profissional: rede não é o problema. O desempenho da rede entra em cena geralmente apenas para implementações usando espelhamento de banco ou de grupos de alta disponibilidade. Esses recursos são, de fato, gulosos por largura de banda e requerem uma conexão rápida, com baixa latência entre os nós. Além disso, tanto DBM e AG tendem a empurrar os problemas para cima da pilha, resultando em degradação do desempenho quando o tráfego de rede não pode se manter com a carga de trabalho.
Espera de rede IO
Este contador mostra as estatísticas de espera relacionadas ao servidor e que foram bloqueadas porque o cliente não está consumindo os conjuntos de resultados. Na maioria das vezes, isso não indica um problema de rede, mas um problema de design do aplicativo: o cliente está solicitando grandes conjuntos de resultados.
Enviar e receber bytes IO por segundo
Estes contadores mostram o tráfego de rede gerado pelo Service Broker e pelo Database Mirroring. Os grupos de disponibilidade têm uma categoria de contador mais especializada em SQL Server: trata-se da réplica de disponibilidade.
Interface de rede
Este é o contador de desempenho onde toda a atividade de rede é exibida, a partir de todos os processos do servidor.
Objeto TCP/Objeto IP
Estas categorias são importantes para monitorar a saúde do fluxo de dados, e não a quantidade. Especificamente, elas podem indicar erros de rede, pacotes cuja transferência falhou e tentativas de conexão (bem sucedidas ou não).
Definindo seus próprios contadores
É possível criar contadores de desempenho personalizado a partir de T-SQL. O SQL Server: Usuário ajustável foi criado especificamente para isso e permite que sejam apontados os valores predefinidos pelo usuário a ser monitorado e coletados pelas ferramentas de contadores de desempenho do sistema. Dessa forma, é possível publicar valores para o contador usando sp_user_counter1 através do sp_user_counter10:
EXECUTE value sp_user_counter1;
Um recuso para desenvolvedores de aplicativos: também é possível adicionar contadores de desempenho ao próprio aplicativo. A publicação de contadores de desempenho criadas na gestão do código do aplicativo é trivialmente fácil, e é possível automatizar o processo de forma a torná-los mais claros, consulte o artigo Usando XSLT para gerar código de contadores de desempenho.
Análise de desempenho avançado
Os desenvolvedores estão familiarizados com a análise de desempenho usando perfil da amostra, com ferramentas como Vtune, F1 ou WPA. A técnica de perfilação de amostra consiste em tomar periodicamente uma amostra da pilha de cada segmento no processo perfilado, até várias centenas de vezes por segundo. O processo é não invasivo, que não requer um processo especialmente instrumentado, qualquer processo pode ser perfilado. Também é bastante leve, e pegar várias centenas de amostras por segundo tem um impacto mensurável sobre o desempenho do processo a servir de amostra. O truque é interpretar as observações. Usar o servidor de símbolos públicos da Microsoft pode resolver as amostras coletadas para nomes de funções reais no código-fonte (note que a minha experiência F1 e WPA faz um trabalho muito melhor em lidar com o código LTCG de SQL Server do que o Vtune). Com um pouco de bom senso, pode-se fazer uma educada adivinhação do que exatamente o SQL Server fazendo durante o período amostrado. Essa técnica só faz sentido se você está vendo o uso significativo da CPU. Se o desempenho é ruim e você vê consultas lentas, mas baixo uso da CPU, isso significa que as consultas estão esperando e você deve se concentrar na análise de informações em espera. Profiling de amostra de um processo bloqueado irá revelar nada de útil.
WPA é uma das minhas ferramentas favoritas de desempenho e pode fazer mais do que apenas uma amostra de perfis. Ela pode visualizar vestígios de XPerf ETW, e isso a torna extremamente poderoso. Documentação e whitepapers existentes para WPA tendem a se concentrar em multimídia e desenvolvimento de jogos, mas se você é um espírito aventureiro e quiser saber mais sobre como funciona o banco de dados favorito, usar WPA para analisar obras do SQL Server pode revelar uma grande quantidade de informações e ajudá-lo a obter melhorias de desempenho pontuais que podem ser aproveitados na sua aplicação. Um dos meus casos de uso favoritas para WPA é coletar atividade de IO (isso irá coletar cada pedido de IO feito ao servidor) e, em seguida, visualizar o disco em um relatório gráfico. Essa é uma forma incrivelmente simples, mas poderosa, para visualização de IO com métricas aleatórias contra os padrões seqeenciais. Se você tem algum sentimento de que o WPA e o XPerf/ETW estão de alguma forma relacionados com o SQL Server Extended Events, é porque eles estão, e muito. Finalmente, algumas leituras importantes antes de usar WPA:
- Guia de Início Rápido: o básico sobre WPA
- Whitepaper sobre análise de desempenho
- O documento perdido do Xperf – uso de disco
- Rastreamento de Windows IO
O método USE
USE significa Utilização, Saturação e Erros, e o método USE é uma abordagem formal para investigar problemas de desempenho do servidor. Seu foco é a identificação de recursos em um sistema e, em seguida, para cada uma das medidas, a utilização (por cento em uso em comparação com o máximo de largura de banda), a saturação dos recursos (trabalho extra na fila porque não pode usar 100% dos recursos) e erros.
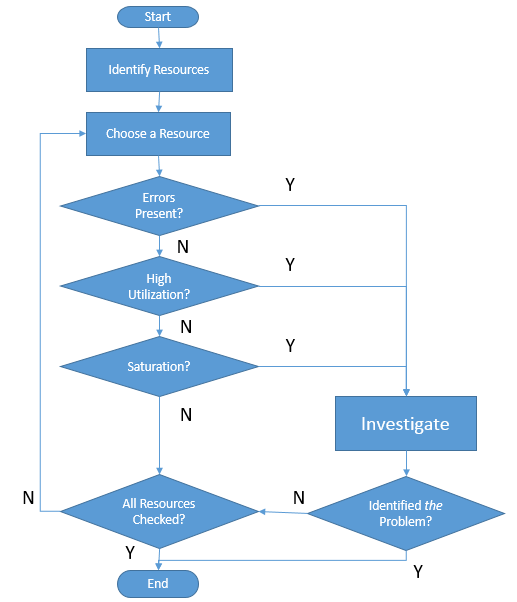
Quando usado em um contexto SQL Server, a parte difícil é identificar os recursos e como medir a utilização, a saturação e os erros. Alguns recursos são óbvios: disco, CPU, memória e rede. Às vezes, usar logo de início o método USE para medir os parâmetros de hardware é uma boa maneira de começar uma investigação por problemas de desempenho, pelo menos você vai saber de imediato qual é o componente de hardware que está saturado, se houver. Mas saber como funciona o SQL Server pode revelar recursos internos mais detalhados e que podem ser analisados com mais profundidade. Em Entender como o SQL Server executa uma consulta, mostrei esta imagem:
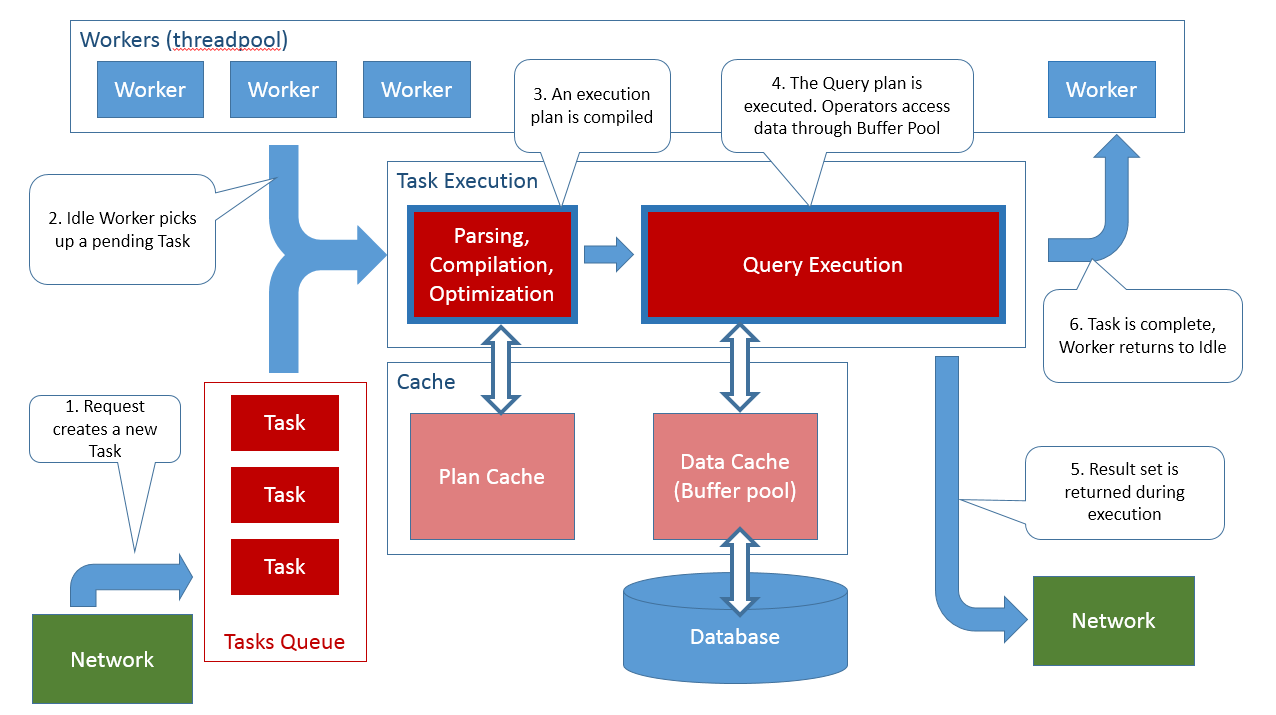
Muitos dos componentes ilustrados na imagem acima podem ser investigados como recursos no método USE. A aplicação dessa metodologia requer pensar amplamente nas estratégias que podem ser utilizadas, uma vez que não existirão muitas referências na Internet sobre como aplicar o método USE para SQL Server em um ambiente específico, quais recursos procurar e como medir utilização, saturação e erros para cada um deles. Eu mesmo não tenho uma imagem clara ainda do que cada recurso envolvido em meu servidor pode apresentar no que tange a problemas de desempenho e ainda estou recolhendo dados e conhecimentos sobre o assunto. Mas gosto da abordagem USE, porque nos dá um método e uma estratégia e um rumo a seguir na solução de problemas de desempenho.
***
Artigo traduzido pela Redação iMasters com autorização do autor. Publicado originalmente em http://rusanu.com/2014/02/24/how-to-analyse-sql-server-performance/
É um desenvolvedor especializado em SQL Server e trabalha na Microsoft há seis anos, integrando a equipe de SQL Server da empresa. Também possui experiência com desenvolvimento em C++ e em C#.


