

Nesta quarta parte sobre desempenho do servidor SQL Server, vamos abordar as atividades de disco, estatísticas de entrada e saída de dados e execução de consultas. Confira o artigo anterior aqui.
Analisar a atividade do disco: estatísticas de IO
O SQL Server precisa ler e escrever para o disco. Todas as gravações (inserções, atualizações, exclusões) devem ser gravadas em disco. Consultas sempre retornam dados do cache na memória (na área de buffer), mas o cache não pode conter os dados desejados. Essaes dados precisam ser lidos a partir do disco. Entender se o IO é um problema de desempenho para o seu servidor é uma etapa necessária em qualquer investigação relacionada a lentidões de um sistema de bancos de dados. O SQL Server coleta, agrega e exibe informações sobre todos os dados e logs de solicitações de IO feitas ao servidor. A primeira coisa que eu particularmente gosto de fazer é olhar para o arquivo sys.dm_io_virtual_file_stats. Essa DMV expõe o número de gravações e leituras em cada arquivo para cada banco de dados no sistema, juntamente com a leitura agregada e escreve seu desempenho e tempos de IO no log. Isso muitas vezes mostra o tempo total das funções que foram bloqueadas durante a espera para transferência de dados para e a partir do disco.
select db_name(io.database_id) as database_name, mf.physical_name as file_name, io.* from sys.dm_io_virtual_file_stats(NULL, NULL) io join sys.master_files mf on mf.database_id = io.database_id and mf.file_id = io.file_id order by (io.num_of_bytes_read + io.num_of_bytes_written) desc;

As estatísticas por arquivo de IO são agregados desde a inicialização do servidor, mas esteja ciente de que elas são redefinidas para cada arquivo se ele nunca fica offline. O número total de bytes transferidos (lidos e escritos) é um bom indicador de quão ocupado é um banco de dados do ponto de vista da entrada e saída de dados. As bases indicam que o sub-sistema de IO (que está no disco) está ocupado e pode até estar saturado.
Analisando a execução individual da consulta
Ao analisar uma consulta individual ou uma consulta específica para medição do desempenho, isso nos permite compreender o que a consulta está fazendo, quanto está em execução contra o que está esperando para ser concluída. A análise mais simples é usar as estatísticas de execução. Isso funciona ao rodar primeiro SET STATISTICS … ON em sua sessão e, em seguida, executar a instrução ou consulta que você deseja analisar. Além do resultado de costume, a consulta relata estatísticas de execução, como veremos a seguir:
SET STATISTICS TIME ON
O tempo de análise de consulta, o tempo de compilação e o tempo de execução são relatados. Se forem executadas consultas em lote ou um procedimento armazenado com várias instruções em sequência, o retorno será o tempo de cada declaração, o que ajuda a determinar qual instrução em um procedimento é o responsável pelo problema de desempenho. Mas será necessário analisar o plano de execução para ter revelada a mesma informação.
SET STATISTICS IO ON
As estatísticas de IO mostram, para cada declaração, o número de operações de IO. O resultado mostra várias métricas para cada tabela atingida pela declaração:
verificação de contagem
Número de vezes em que os exames ou a busca foram iniciados em uma tabela. Idealmente, cada tabela deve ser verificada no máximo uma vez.
leituras lógicas
Número de páginas de dados a partir do qual as linhas foram lidas a partir do cache de memória (pool de buffer).
leituras físicas
Número de páginas de dados a partir do qual os dados foram ou tiveram de ser transferidos do cache na memória (área de buffer) e a tarefa teve que bloquear para esperar que a transferência terminasse.
read-ahead
Número de páginas de dados que foram transferidas de forma assíncrona do disco para o pool do buffer e cuja tarefa não esperou nenhum dado para a transferência.
LOB lógico/físico
O mesmo que suas contrapartes não-LOB, mas referindo-se à leitura de grandes colunas de dados (LOBs).
Há também a regra SET STATISTICS PROFILE ON, que fornece uma informação detalhada para a execução de uma determinada instrução, mas grande parte das informações se sobrepõe com a informação do plano de execução, e analisar o plano de execução é mais fácil e produz melhores informações.
A leitura lógica lê um determinado valor para uma declaração e indica se será ou não muito custoso para o servidor. Para ambientes OLTP, o número de leituras lógicas deve estar em apenas um dígito. Grandes leituras lógicas traduzem longo prazos de execução e alto consumo de CPU, mesmo sob condições ideais. Em condições menos ideais, algumas ou todas essas leituras lógicas se transformam em leituras físicas, o que significa longos tempos à espera de transferência do disco de dados no buffer. Grande leituras lógicas são indicativos de grandes varreduras de dados, geralmente de uma tabela inteira. Elas são, na maioria das vezes, causadas por índices perdidos. Em OLAP, a decisão e os ambientes de DW, escaneamentos e grandes leituras lógicas podem ser inevitáveis, já que a indexação de uma carga de trabalho OLAP é complicada, e a indexação para uma carga de trabalho de análise ad-hoc é basicamente impossível. Para esses últimos casos, a resposta geralmente se baseia no uso de tecnologias DW específicas como columnstores.
Informações sobre estatísticas de execução de consulta também podem ser obtidas usando o SQL Profiler. As ferramentas SQL: StmtCompleted, SQL: BatchCompleted, SP: StmtCompleted e RCP: Completed capturam o número de páginas lidas, o número da páginas escritas e o tempo de execução de uma chamada individual, um procedimento armazenado ou um lote de instruções SQL. O número de leituras é lido de forma lógica. Note que o monitoramento com o SQL Profiler para eventos individuais de instrução executada terá efeito no desempenho, e em um grande servidor (muito ocupado) pode causar degradação significativa no desempenho.
Você também pode ver o número de leituras lógicas, leituras e escritas em tempo real, olhando para os sys.dm_exec_requests, mas essa informação só é visível enquanto um pedido está em execução. Além disso, o número agregado de todas as declarações em uma solicitação impede que seja determinado o custo de uma declaração individual.
Analisando o tempo de espera e a execução de consultas individuais
Se for necessário aprofundar-se ainda mais em detalhes relacionados ao tempo de execução e às estatísticas de IO para uma consulta ou um procedimento armazenado, a melhor informação são os tipos de espera e tempos de espera que ocorreram durante a execução. A obtenção dessa informação já não é simples, mas envolve o uso estendido de eventos de monitoramento. O método que estou apresentando neste artigo é baseado nos tempos de resposta lentos de debug do SQL Server 2008. Ele envolve a criação de uma sessão de evento estendido que captura a informação sqlos.wait_info e filtra a sessão de eventos estendida para uma sessão de execução específica (SPID):
create event session session_waits on server
add event sqlos.wait_info
(WHERE sqlserver.session_id=<execution_spid_here> and duration>0)
, add event sqlos.wait_info_external
(WHERE sqlserver.session_id=<execution_spid_here> and duration>0)
add target package0.asynchronous_file_target
(SET filename=N'c:\temp\wait_stats.xel', metadatafile=N'c:\temp\wait_stats.xem');
go
alter event session session_waits on server state= start;
go
Com a sessão de eventos estendidos criada e iniciada, agora será possível executar a consulta ou O procedimento que deseja analisar. Depois disso, pare a sessão de eventos estendida e verifique os dados capturados:
alter event session session_waits on server state= stop;
go
with x as (
select cast(event_data as xml) as xevent
from sys.fn_xe_file_target_read_file
('c:\temp\wait_stats*.xel', 'c:\temp\wait_stats*.xem', null, null))
select * from x;
go
Como é possível ver, a sessão de Eventos Estendidos captura cada espera individual e cada incidente quando a sessão foi suspensa. Ao clicar em um evento capturado vemos o XML de dados de eventos:
<event name="wait_info" package="sqlos" timestamp="2014-01-14T12:08:14.388Z">
<data name="wait_type">
<value>8</value>
<text>LCK_M_IX</text>
</data>
<data name="opcode">
<value>1</value>
<text>End</text>
</data>
<data name="duration">
<value>4</value>
</data>
<data name="signal_duration">
<value>2</value>
</data>
</event>
Esta é uma espera de 4 milissegundos para um bloqueio do modo IX. Outros 2 milissegundos se passaram até que que a tarefa tenha sido retomada, após o bloqueio que foi concedido. Você pode analisar o XML em colunas para uma melhor visualização:
with x as (
select cast(event_data as xml) as xevent
from sys.fn_xe_file_target_read_file
('c:\temp\wait_stats*.xel', 'c:\temp\wait_stats*.xem', null, null))
select xevent.value(N'(/event/data[@name="wait_type"]/text)[1]', 'sysname') as wait_type,
xevent.value(N'(/event/data[@name="duration"]/value)[1]', 'int') as duration,
xevent.value(N'(/event/data[@name="signal_duration"]/value)[1]', 'int') as signal_duration
from x;
Finalmente, podemos agregar todos os dados capturados na sessão de eventos estendidos:
with x as (
select cast(event_data as xml) as xevent
from sys.fn_xe_file_target_read_file
('c:\temp\wait_stats*.xel', 'c:\temp\wait_stats*.xem', null, null)),
s as (select xevent.value(N'(/event/data[@name="wait_type"]/text)[1]', 'sysname') as wait_type,
xevent.value(N'(/event/data[@name="duration"]/value)[1]', 'int') as duration,
xevent.value(N'(/event/data[@name="signal_duration"]/value)[1]', 'int') as signal_duration
from x)
select wait_type,
count(*) as count_waits,
sum(duration) as total__duration,
sum(signal_duration) as total_signal_duration,
max(duration) as max_duration,
max(signal_duration) as max_signal_duration
from s
group by wait_type
order by sum(duration) desc;
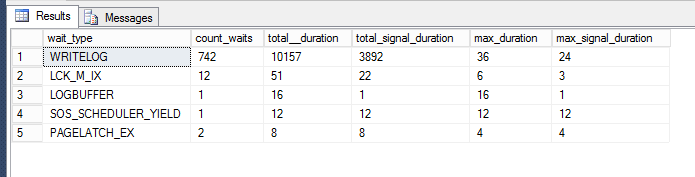
Será exibida uma excepcional riqueza de informações sobre o que aconteceu durante a execução de um determinado pedido. 742 vezes, o log comprometeu-se a gravar em disco as informações para um total de ~14 segundos de tempo de espera, 12 vezes houve a espera por um bloqueio, duas vezes houve alguma página com uma trava etc.
No próximo artigo desta série, vamos analisar como funcionam os planos de execução, seu funcionamento interno e como se comportam as consultas problemáticas.
***
Artigo traduzido pela Redação iMasters com autorização do autor. Publicado originalmente em http://rusanu.com/2014/02/24/how-to-analyse-sql-server-performance/

De 0 a 10, o quanto você recomendaria este artigo para um amigo?