

Olá! Hoje vamos conhecer algumas ferramentas e bibliotecas essenciais para trabalhar com Mineração de Dados e Big Data.
Esse assunto geralmente é bem polêmico, visto que cada profissional tem uma opinião e até mesmo paixão por algumas ferramentas.
Uma pesquisa do site KDnuggets, de maio de 2015 revelou as ferramentas mais usadas pela comunidade de mineração de dados.
Como a lista é bastante extensa, dividi o artigo em duas partes.
Nessa primeira parte, veremos:
- Python: Agora ninguém poderá te deter!
- Bibliotecas Python: Faça muito com pouco
- Anaconda – Swiss Army Knife!
- Python: Grinding Tools!
- R: Simplicidade e eficiência!
Na segunda parte, veremos:
- RapidMiner: Acelere suas análises através de Workflows.
- Weka: O Poder da GUI.
- Machine Learning na prática com Weka
Se você já gostou do assunto desse artigo, não deixe de compartilhar com seus amigos para que cada vez mais pessoas aprendam sobre as melhores ferramentas de Mineração de Dados e Big Data.
Vamos lá!
Python: agora ninguém poderá te deter!

Segundo a pesquisa, Python foi considerada a linguagem de programação mais usada pela comunidade de profissionais de Mineração de dados e Big data.
Python tem inúmeras razões para ser escolhida e podemos citar algumas como simplicidade, clareza e reusabilidade.
A linguagem oferece uma sintaxe simples e objetiva permitindo o programador se focar no problema a ser resolvido sem se preocupar tanto com detalhes de implementações.
Por exigir que o código fonte seja corretamente endentado, sua leitura e compreensão se torna extremamente clara e organizada, contribuindo para o aumento de produtividade entre programadores.
Além da grande comunidade no mundo inteiro, Python possui um vasto e variado conjunto de bibliotecas para se trabalhar com diversas áreas, desde computação científica, redes, segurança e claro análise de dados.
Vamos citar algumas principais bibliotecas e ferramentas indispensáveis para trabalhar com mineração de dados.
Bibliotecas Python: faça muito com pouco!
Jupyter: Aplicação cliente-servidor que permite a edição e execução de notebooks via browser. Notebooks são documentos que contém código e elementos visuais como imagens, links, equações. A principal vantagema utilização de notebooks é para a descrição de análises e seus resultados de forma dinâmica e interativa.
NumPy: Biblioteca Python para computação científica. Implementa arrays multidimensionais e permite a fácil execução de operações matemáticas e lógicas como ordenação, seleção, transformações, operações estatísticas básicas etc.
Matplotlib: Biblioteca Python 2D para a visualização e plotagem de gráficos. Pode ser utilizada para gerar diversos tipos de gráficos como histogramas, gráficos de barras, gráficos de pizza tudo de forma fácil e rápida.
Pandas: Esta biblioteca talvez seja a mais utilizada para análise de dados. Ela fornece ferramentas para manipulação de estruturas de dados de forma extremamente simples. Operações complexas que trabalham com matrizes e vetores podem ser facilmente realizadas com uma ótima performance.
Scikit-Learn: Biblioteca Python para trabalhar com Machine Learn (Aprendizado de Máquina). Contém diversos algoritmos implementados, métodos de análise e processamento de dados, métricas de avaliação etc. Essa é uma biblioteca extremamente útil para o cientista de dados.
NLTK: é uma plataforma líder para a construção de programas Python para trabalhar com dados de linguagem humana. Ele fornece interfaces fáceis de usar para mais de 50 corpora e recursos lexicais como o WordNet, juntamente com um conjunto de bibliotecas de processamento de texto para classificação, tokenização, stemming, tagging, análise e raciocínio semântico
Scrapy: Biblioteca Python para a raspagem ou coleta de dados a partir da Web. É possível coletar dados de sites, redes sociais, fóruns e diversos outros canais utilizando uma linguagem simples e objetiva. Extremamente útil para a geração de bases de dados.
Anaconda – Swiss Army Knife!

O Anaconda é uma plataforma open source para Data Science.
Esta plataforma contém centenas de pacotes embutidos, é só instalar e pronto.
As principais bibliotecas Python e R para Data Science já estão disponíveis nessa plataforma. Além disso, caso precise instalar alguma biblioteca, use o conda, o gerenciador de pacotes da Anaconda.
Anaconda tem versões para Windows, Linux e OSX, e já vem com o Python instalado, apenas escolha qual a versão você quer trabalhar.
Para fazer download do Anaconda, clique aqui
Siga os passos para instalação conforme o seu ambiente. A instalação é bem simples.Veja:
Executando o instalador
bash Anaconda3-4.3.0-Linux-x86_64.sh
Após a instalação confira se a instalação foi bem sucedida
#imprimindo a versão do python.. ~/anaconda3/bin$ ./python --version Python 3.6.0 :: Anaconda 4.3.0 (64-bit)
As principais bibliotecas que abordamos já estão instaladas, veja:
~/anaconda3/bin$ ./python import pandas as pd import numpy as np import matplotlib as plt from sklearn import datasets
Falta apenas instalar o Scrapy e o Pymongo. Isso é bem fácil, veja:
#instalando o Scrapy ~/anaconda3/bin$./conda install -c conda-forge Scrapy=1.3.2
#instalando o Pymongo ~/anaconda3/bin$./conda install pymongo
Pronto!
Temos as bibliotecas Python instaladas em poucos minutos.
Mas, caso você não queira usar o Anaconda, continue lendo artigo para aprender como instalar cada biblioteca individualmente.
Python – Grinding Tools!

Caso você queira instalar as bibliotecas em seu ambiente de forma individual, abaixo estão os passos para instalação de cada uma.
Se você estiver usando um linux é bem provável que o Python já virá instalado na sua distribuição.
No nosso exemplo, usamos o Ubuntu. Neste, o Python já vem instalado na versão 2.7.12. Veja:
python --version Python 2.7.12
Caso não tenha instalado, use o gerenciador de pacotes da sua distribuição, como no exemplo abaixo:
sudo apt-get install python
No momento em que escrevo esse artigo, o Python se encontra na versão 3.6.0
É nessa versão que vamos trabalhar aqui, mas fique a vontade para usar a versão que melhor atenda você.
Para instalar o Python3 faça:
sudo apt-get install python3-all
Após isso é chamar o python3 no terminal como:
python3
Caso tenha alguma dúvida, consulte a documentação oficial aqui
Agora que temos o Python instalado, vamos começar instalando a ferramenta Jupyter Notebooks.
Esta é sem dúvida uma das melhores ferramentas para se trabalhar com Mineração de dados e Big data.
É uma verdadeira mão na roda, pois, através de um browser podemos emitir instruções python, plotar gráficos ou manipular dados de uma forma intuitiva e simples.
Tudo isso de forma rápida e sem ter que escrever tantos programas. Com os Notebooks seus scripts ficam documentados e é fácil de compartilhar com outros programadores.
Para instalar o Jupyter Notebooks faça:
sudo apt install python-pip
Instale a ferramenta pip, se esta já não estiver instalada:
sudo pip install jupyter
Em seguida instale o jupyter..
Pronto, com o jupyter instalado, inicie a aplicação para ter certeza que não houve erro na instalação
jupyter notebook
Deve ser exibido o browser com a interface do jupyter notebooks.
Numpy
O Numpy, como já dito anteriormente, é uma biblioteca muito usada, pois, facilita bastante operações matemáticas e lógicas como ordenação, seleção, transformações, operações estatísticas básicas.
Para instalar faça:
sudo pip install numpy
O processo é bem simples e rápido. Em poucos segundos a biblioteca já está instalada e pronta para uso.
Para testar se tudo ocorreu bem, faça um teste simples, veja:
Conecte no console python
python
Importe a biblioteca e execute o bloco de código como no exemplo abaixo:
import numpy as np a = np.arange(6) print (a) [0 1 2 3 4 5]
Caso você tenha recebido a saída mostrada acima, a instalação foi bem sucedida.
Matplotlib
O Matplotlib é uma biblioteca python usada para plotagem de gráficos 2D. O objetivo dela é descomplicar a plotagem de gráficos e tornar fácil a visualização de dados.
Para instalar faça:
sudo pip install matplotlib
Aguarde um pouco até a conclusão da instalação.
Para testar se tudo ocorreu bem, faça um teste simples, veja:
– conecte no console python:
python
– importe a biblioteca e execute o bloco de código como no exemplo abaixo:
import matplotlib.pyplot as plt
plt.plot([1,2,3,4])
plt.ylabel('Numeros')
plt.show()
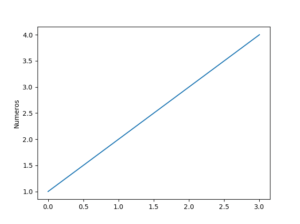
O código acima deverá plotar um gráfico simples na tela conforme a imagem acima. Se deu tudo certo, sua instalação está Ok.
Pandas
A pandas é uma biblioteca open source bastante poderosa. Ela implementa uma forma fácil e de alto desempenho para trabalhar com estruturas de dados. Particularmente é a biblioteca que eu mais gosto.
Para instalar faça:
sudo apt-get install python-pandas
Aguarde a instalação da biblioteca. Esta deve demorar mais um pouco, pois, possui diversas dependências.
Para testar se tudo ocorreu bem, faça um teste simples, veja:
Conecte no console python
python
Importe a biblioteca e execute o bloco de código como no exemplo abaixo:
import pandas as pd num = pd.Series([1,3,5,6,'',8]) print (num) 0 1 1 3 2 5 3 6 4 5 8 dtype: object
Se a saída acima foi impressa na tela, sua instalação está ok.
Scikit-learn
A Scikit-learn é uma biblioteca simples e eficiente para mineração de dados. Ela contém diversos algoritmos de Machine Learning implementados em Python que podem ser executados facilmente.
Para instalar faça:
sudo pip install scikit-learn
Aguarde alguns instantes e pronto já está instalada e pronta para trabalhar. Para testar se tudo ocorreu bem, faça um teste simples, veja:
Conecte no console python
python
Importe a biblioteca e execute o bloco de código como no exemplo abaixo:
Este deve imprimir a estrutura do dataset Iris. Se foi impresso sem qualquer erro, a biblioteca foi instalada com sucesso.
NLTK
O NLTK é um kit de ferramentas para processamento da linguagem natural.
Com este é possível trabalhar com técnicas de NLP de forma fácil e intuitiva, pela sua vasta quantidade de métodos existentes, o NLTK é um kit obrigatório quando o assunto é mineração de textos ou linguística.
Para instalar faça:
sudo pip install nltk
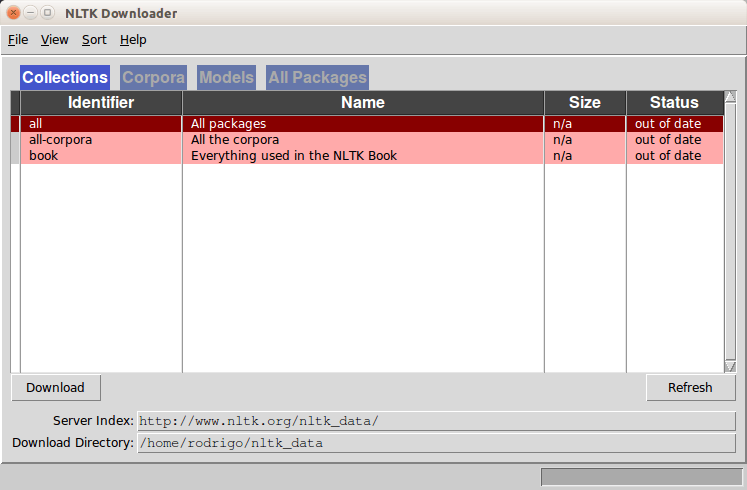
Após instalar, conecte no console e faça o download do corpus da NLTK. Este contém diversos datasets para testes, textos e é bem útil. Eu normalmente faço download de tudo.
import nltk nltk.download()
Será exibida a imagem abaixo. Clique em “all” e em OK e aguarde o download.
Scrapy
O Scrapy é um framework incrível usado para fazer crawler de páginas na web. Com o scrapy é possível construir crawlers para extração de dados de páginas na web de forma fácil, e simples.
Para instalar faça:
sudo pip install scrapy
Caso receba o seguinte erro:
scrapy : Depends: python-support (>= 0.90.0) but it is not installable
E: Unable to correct problems, you have held broken packages
Instale o pacote python-support, pois, na versão do Ubuntu 16.04 esse pacote foi removido. Esse pacote contém as bibliotecas que são dependências para o Scrapy. Faça:
wget http://launchpadlibrarian.net/109052632/python-support_1.0.15_all.deb sudo dpkg -i python-support_1.0.15_all.deb
Após instalar o pacote, repita o comando pip para instalar o Scrapy:
sudo pip install scrapy
Para testar se tudo ocorreu bem, faça um teste simples, veja:
Execute a ferramenta Scrapy passando o parâmetro ‘version’
md@server01:~$ scrapy version Scrapy 1.3.2
Se não foi emitido nenhum erro, a instalação está ok.
Pymongo
PyMongo é uma biblioteca de acesso ao banco de dados MongoDB.
Sua implementação facilita a interação com o SGBD, permitindo emitir instruções ao banco de dados através de código python.
Para instalar faça:
sudo pip install pymongo
A instalação é bem rápida.
Para testar se tudo ocorreu bem, faça um teste simples, veja:
Conecte no console python
python
Importe a biblioteca e execute o bloco de código como no exemplo abaixo:
from pymongo import MongoClient client = MongoClient() print (client)
O bloco acima, cria uma instância para uma conexão cliente. Se não houve nenhum erro, a biblioteca está ok.
R – simplicidade e eficiência!
![]()
R é uma linguagem de programação extremamente poderosa e que tem um espaço em destaque quando o assunto é Data Science. É famosa pela sua facilidade para fazer análise de dados, processar instruções estatísticas e modelos gráficos.
Para instalar o R:
O primeiro a ser feito é descobrir codinome do Ubuntu, para isso utilize o seguinte comando:
lsb_release -a Codename: trusty
No site do R tem a lista de repositórios que mantém o projeto.
Escolha o repositório de onde você quer fazer o download.
No meu caso escolhi o repositório da USP no Brasil
Importante: Deve haver um espaço entre o link e o nome da versão do seu ubuntu
Adicione o endereço do repositório e o codinome do seu Ubuntu no final do arquivo /etc/apt/source.list. No meu caso ficou:
vi /etc/apt/source.list deb http://vps.fmvz.usp.br/CRAN/bin/linux/ubuntu trusty/
Em seguida adicione as chaves
sudo gpg --keyserver keyserver.ubuntu.com --recv-key E084DAB9 sudo gpg -a --export E084DAB9 | sudo apt-key add -
Agora atualize a lista de repositórios da sua máquina e instale os pacotes do R
sudo apt-get update sudo apt-get install r-base r-base-dev
Após instalação abra o console do R com o comando “R” (maiúsculo):
R
R-Studio
Quem trabalha com R sabe que existem diversas ferramentas para ajudar o desenvolvedor a trabalhar com essa linguagem.
A ferramenta que mais se destaca é o R-studio.
Esta é uma IDE open source para R muito útil pois facilita bastante o desenvolvimento.
Nesse artigo vamos instalar a versão R-Studio Desktop dessa ferramenta.
Para instalar o R-Studio no Ubuntu faça download do pacote aqui
No meu caso precisei instalar a seguinte biblioteca, pois, essa é uma dependência para instalação do R-Studio.
sudo apt-get install libjpeg62
Em seguida instale o R-Studio
sudo dpkg -i rstudio-1.0.136-amd64.deb
Pronto!
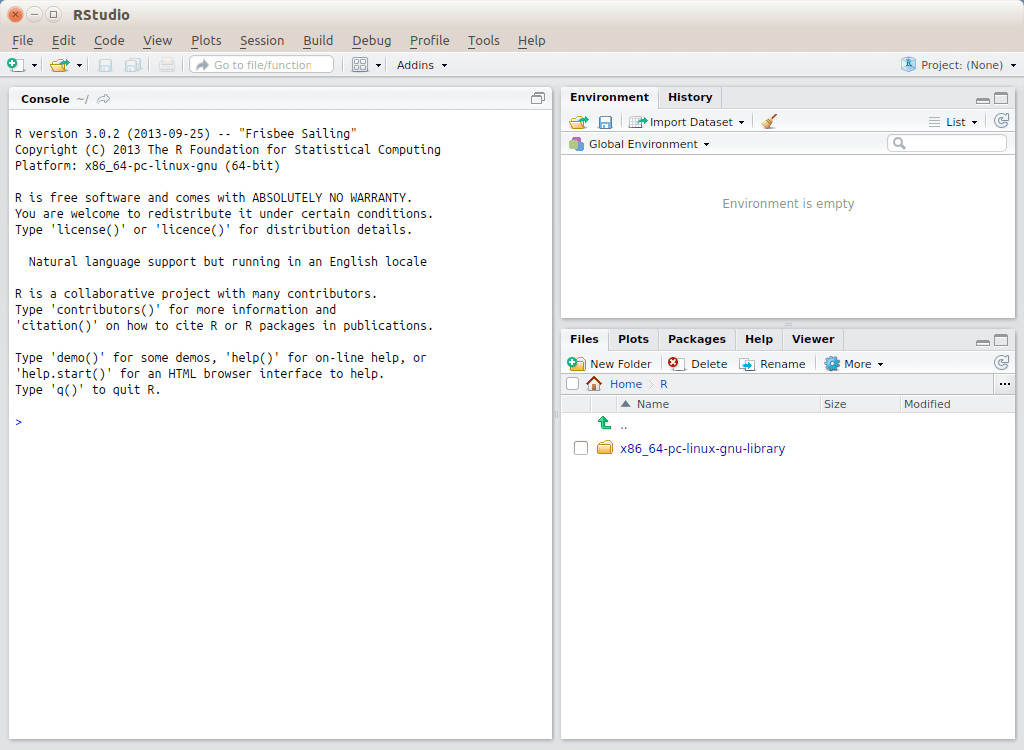
Chame o R-Studio no console com o comando
rstudio
Se estiver usando Windows, a instalação do R é bem fácil.
Basta fazer o download aqui e seguir o assistente de instalação.
No próximo artigo continuaremos com outras ferramentas. Falaremos do RapidMiner, do Weka e sobre machine learning na prática com Weka.
Se você já gostou do assunto desse artigo, não deixe de compartilhar com seus amigos para que cada vez mais pessoas aprendam sobre as melhores ferramentas de Mineração de Dados e Big Data.

De 0 a 10, o quanto você recomendaria este artigo para um amigo?