

Olá! Daremos prosseguimento à primeira parte deste artigo e veremos mais ferramentas e bibliotecas essenciais para trabalhar com Mineração de Dados e Big Data.
Na parte 01, falamos de ferramentas de Python e de R. Hoje vamos falar de RapidMiner e de Weka, além de machine learning na prática com Weka.
Se você já gostou do assunto desse artigo, não deixe de compartilhar com seus amigos para que cada vez mais pessoas aprendam sobre as melhores ferramentas de Mineração de Dados e Big Data.
Vamos lá!
RapidMiner – acelere suas análises através de workflows
![]()
RapidMiner é uma plataforma para trabalhar com Data Science de forma rápida, simples e visual. As ferramentas oferecidas fornecem uma interface gráfica rica com objetos e processos que simplificam as diversas tarefas necessárias para trabalhar mineração de dados.
Através do RapidMiner Studio é possível criar workflows extremamente intuitivos com objetos que executam todas as tarefas do processo de mineração de dados, como, leitura e carregamento dos dados, limpeza e transformação, filtragem, modelagem, aplicação de algoritmos de Machine Learning e visualização dos resultados.
O diferencial do RapidMiner é a facilidade e velocidade para criar modelos preditivos já que não é necessário o trabalho de codificação e transformação dos dados. Dessa forma o processo de validação e ajuste do modelo se torna simples.
Os três produtos oferecidos são o RapidMiner Studio, RapidMiner Server e RapidMiner Radoop.
- RapidMiner Studio: Utilizado para desenhar os Workflows que mapeiam todo o processo de mineração de dados desde o carregamento dos dados até a visualização dos resultados.
- RapidMiner Server: Utilizado para gerenciar seus modelos, compartilhar com outros usuários.
- RapidMiner Radoop: Utilizado para compilar e executar workflows armazenados no Hadoop.
A plataforma oferece um tipo de licenciamento gratuito que permite a utilização do Rapidminer Studio com uma base de dados de até 10 mil registros.
Veja na imagem abaixo um exemplo de Workflow criado no RapidMiner.
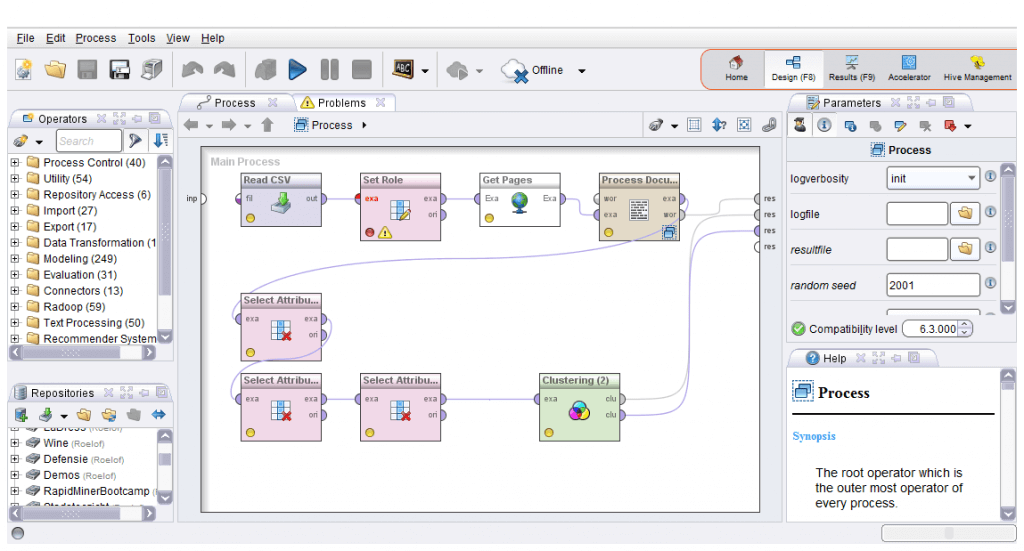
Como você pode ver é bem simples usar o Rapiminer.
Como o Rapidminer simplifica vários passos, o desenvolvedor não precisa instalar diversas ferramentas para realizar seu trabalho.
Já ta tudo pronto, em um só lugar
Weka – O Poder da GUI!

Weka é um projeto open source que significa Waikato Environment for Knowledge Analysis – Ambiente para Análise de Conhecimento Waikato. Foi criado como um projeto de Machine Learning pela universidade de Waikato na Nova Zelândia.
O projeto tem o objetivo de disseminar técnicas de Machine Learning através da disponibilização do software para utilização de pesquisadores, alunos e para resolver problemas reais da indústria além de contribuir com a ciência pela mundo.
O grande diferencial do Weka além de todo o seu arsenal de métodos e algoritmos é a sua interface gráfica (GUI – Graphical User Interface) que torna as tarefas de mineração de dados extremamente fáceis e rápidas.
Através da interface é possível consultar dados em sistemas de bancos de dados, executar métodos de processamento de dados, executar e configurar parâmetros dos algoritmos e visualizar os resultados através de gráficos. Tudo isso sem precisar escrever comandos ou programar.
O weka tem funcionalidades para manipulação de bases de dados (pre-processamento), interface para visualização de dados, e ainda disponível diversos algoritmos de machine learning e Data Mining. Isso facilita muito a vida dos seus usuários que não tem que dominar diversas ferramentas para fazer seu trabalho
Para quem gosta de escrever comandos ou programar scripts o Weka fornece também acesso a sua vasta coleção de técnicas e algoritmos via API.
Dessa forma podemos utilizar seus recursos em programas Java. Consulte a documentação aqui.
O Weka é uma ferramenta desenvolvida em Java e pode ser baixado e utilizado livremente em diferentes plataformas como Windows, Linux e Mac.
Instalando o Weka
Para instalar e executar o Weka é super simples.
O primeiro passo é fazer o download neste link conforme seu sistema operacional. Observe que para o Weka funcionar é necessário a instalação do ambiente de execução do Java (JRE).
No Ubuntu para instalar o JRE, basta instalar o pacote o default-jre conforme o comando abaixo:
sudo apt-get install default-jre
Após instalar o Java, descompacte o pacote do Weka, e em seguida, execute sua interface gráfica como no exemplo abaixo:
unzip weka-3-8-1 cd weka-3-8-1/ java -jar weka.jar
Será exibida a interface como na imagem abaixo:

Pronto, a instalação foi feita com sucesso!
Para o ambiente Windows é possível baixar o Weka juntamente com o Java, após isso é só seguir o assistente de instalação normalmente.
Machine Learning na prática com Weka
Agora que já conhecemos e instalamos as principais ferramentas e bibliotecas para trabalhar com Mineração de Dados, vamos utilizar de forma rápida e objetiva o Weka para carregar um dataset de testes e executar nosso primeiro algoritmo de Machine Learning.
Para isso siga os passos abaixo:
Inicie o Weka conforme instruções da sessão anterior e clique no menu Explorer.
Na tela Weka Explorer clique no botão Open File e selecione o diretório data dentro do diretório de instalação do Weka conforme imagens abaixo.

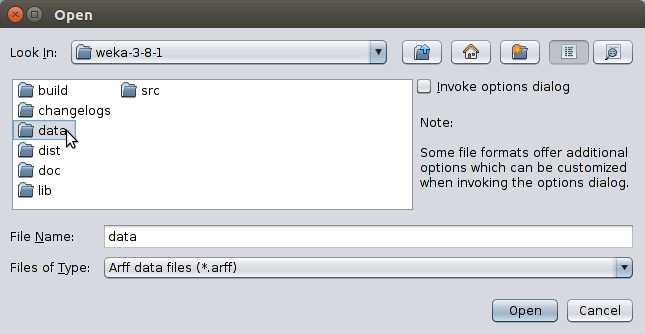
Selecione o dataset iris.arff que está dentro do diretório data e clique em Open.
Este é um dataset simples e bem pequeno que já vem com Weka para testes.
Após carregar o dataset nesta tela temos uma visão geral, veja que temos 5 atributos (colunas) e 150 instâncias (linhas) e contem 3 classes (setosa, versicolor e virginica).
As classes ou rótulos são os tipos reais das flores. Essa classificação foi feita por pessoas especialistas no assunto. Caso queira saber mais sobre esse dataset, leia aqui.
Podemos fazer um pré-processamento da base antes de rodar algum algoritmo. Como por exemplo, excluir uma coluna, ou modelar a base em um formato diferente.
Para este exemplo vamos deixar como está. O objetivo aqui é usar esse dataset para aplicar um algoritmo de Machine Learning que seja capaz de classificar corretamente a espécie de alguma flor baseado nos seus atributos.

Classificação
Agora vamos executar o algoritmo de classificação, para isso clique na aba Classify, selecione choose, navegue até trees e selecione o algoritmo J48 conforme imagem abaixo.
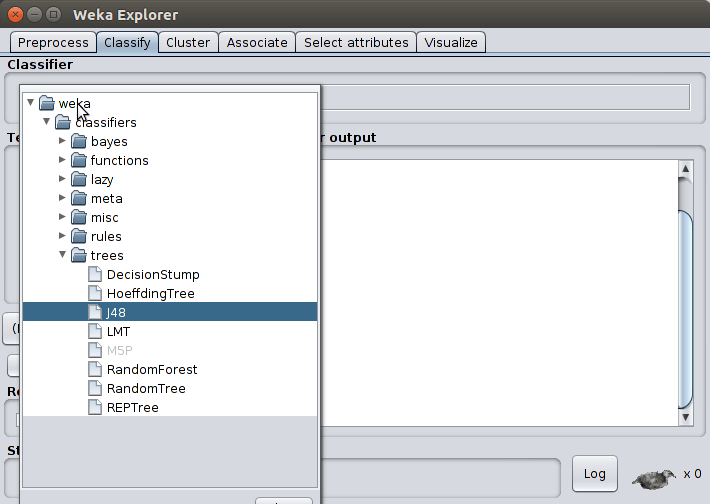
J48 é uma implementação do algoritmo C4.5 na linguagem Java.
O algoritmo usa uma arvore de decisão construída a partir dos dados de treino.
Essas árvores são hipóteses usadas para predizer uma probabilidade de uma instância ser de uma determinada classe. Para entender mais sobre esse algoritmo, leia aqui.
Observe que na aba Test Options está selecionado a opção Cross Validation com 10 folds. Isso significa que o dataset será treinado 9 vezes com partes distintas (folds) dos dados.Por exemplo, uma parte do dado será usada como teste para classificação enquanto outras 9 partes serão usadas para treinar o modelo.
Dessa forma o algoritmo é testado com todas as partes dos dados evitando erros de variância. Para saber mais detalhes sobre essa técnica, clique aqui. Clique em Start para executar o algoritmo.
Resultados
Após alguns segundos, o algoritmo conclui sua tarefa e é exibida a tela de resultados.
Na seção Summary , verifique que de 150 instâncias que foram testadas, o algoritmo acertou 144 (Correctly Classified Instances).
Isso significa que 96% das instâncias testadas foram corretamente classificadas.
Esta métrica é chamada de Acurácia, ou seja, nosso algoritmo teve 96% de acurácia. Caso queira saber mais sobre essa métrica, leia aqui.
Na seção Detailed Accuracy By Class temos a acurácia por classe. Na seção Confusion Matrix é possível investigar como se saiu a classificação de cada classe comparada aos valores reais.
Por exemplo, perceba que a classe a (Iris-setosa) foi classificada 1 vez como classe b (Iris-versicolor), além disso pode se observar que a classe b (Iris-versicolor) foi classificada 3 vezes como classe c (Iris-virginica) e ainda que a classe c (Iris-virginica) foi classificada 2 vezes como classe b (Iris-versicolor).
Com essa tabela fica fácil visualizar quais classes estão sendo classificadas erroneamente como sendo de outras classes.
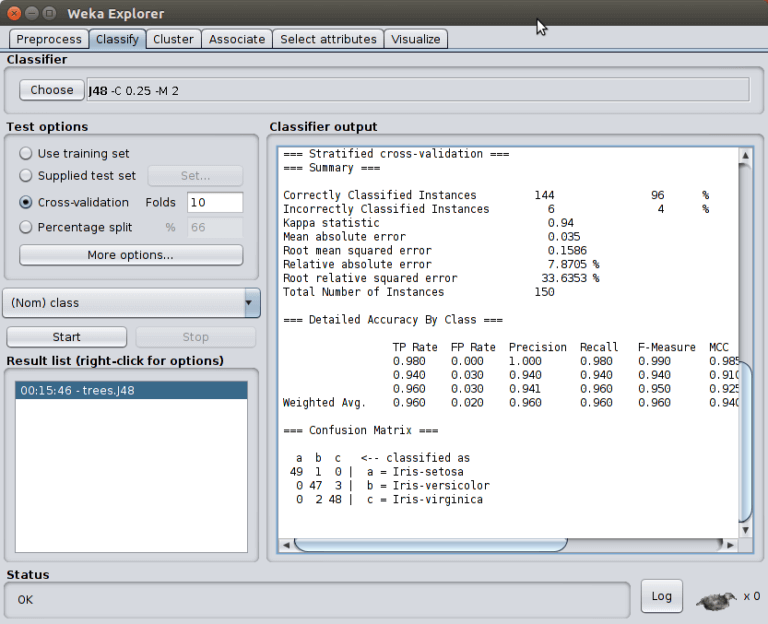
Várias outras métricas devem ser avaliadas para medir o desempenho do algoritmo em uma tarefa de classificação. Iremos aprofundar nestes detalhes em outros artigos.
Conclusão
Nesse artigo vimos as ferramentas e bibliotecas essenciais para se trabalhar com Mineração de Dados e Big data.
Começamos com a linguagem Python e todas as suas bibliotecas que facilitam o trabalho de Mineração de Dados além de oferecer um grande apoio da comunidade por ser uma tecnologia extremamente disseminada.
Vimos como instalar o pacote Anaconda e também as bibliotecas individualmente.
Logo após vimos como instalar o R e sua IDE de desenvolvimento RStudio para trabalhar com análise de dados.
Além disso conhecemos e instalamos os projetos Weka e RapidMiner e vimos como essas ferramentas são poderosas para realizar tarefas de Mineração de Dados de forma rápida e produtiva.
Com o Weka também fizemos uma tarefa de Machine Learning de forma bem intuitiva, a ferramenta funcionou muito bem.
Existem diversas ferramentas, bibliotecas e plataformas para trabalhar com Mineração de Dados e Big Data . Saber utilizá-las de forma correta, pode trazer diversos benefícios para o cientista de dados como produtividade, clareza e facilidade.
Se você gostou desse artigo, não deixe de compartilhar com seus amigos para que cada vez mais pessoas aprendam sobre as melhores ferramentas de Mineração de Dados e Big Data.
Vamos criar uma comunidade de mineradores!

De 0 a 10, o quanto você recomendaria este artigo para um amigo?