

Se você é um desenvolvedor de aplicativos de gravação que usa SQL Server e está se perguntando o que acontece exatamente quando você “Executa” uma consulta a partir de seu aplicativo, espero que este artigo o auxilie a escrever um código melhor para o banco de dados e que o ajude a começar quando tiver que que investigar problemas de desempenho.
Pedidos
O SQL Server é uma plataforma cliente-servidor. A única maneira de interagir com o banco de dados back-end é enviando pedidos que contêm comandos para o banco de dados. O protocolo utilizado para a comunicação entre o aplicativo e o banco de dados é chamado de TDS (Tabular Data Sream) e é descrito no MSDN, no Documento Técnico [MS-TDS]:Tabular Data Stream Protocol. O aplicativo pode usar uma das várias implementações do lado cliente do protocolo: a CLR gerencia SqlClient, OleDB, ODBC, JDBC, drivers PHP para SQL Server ou a implementação aberta FreeTDS. A essência principal, é que, quando o aplicativo pede ao banco de dados para fazer qualquer coisa, este envie um pedido através do protocolo TDS. O pedido em si pode assumir várias formas:
Este tipo de solicitação contém apenas texto T-SQL para um lote de instruções que serão executadas. Este tipo de pedido não tem parâmetros, mas, obviamente, o próprio lote T-SQL pode conter declarações de variáveis locais. Este é o tipo de solicitação que o SqlClient envia se você chamar qualquer um dos comandos SqlCommand.ExecuteReader(), ExecuteNonQuery(), ExecuteScalar(), ExecuteXmlReader() (ou seus respectivos equivalentes assíncronos) em um objeto SqlCommand com uma lista vazia de parâmetros. Se você monitorar o banco de dados com SQL Profiler, verá uma Classe de evento BatchStarting SQL.
Procedure remota de chamada de requisições
Este tipo de solicitação contém um identificador de processo para ser executado em conjunto com qualquer número de parâmetros. De especial interesse é quando o id do procedimento será 12, como por exemplo, sp_execute. Nesse caso, o primeiro parâmetro é o texto T-SQL a ser executado, e esse é o pedido que seu aplicativo irá enviar se for executado um objeto SqlCommand com uma lista contendo parâmetros. Se for monitorado o uso do SQL Profiler, você verá um evento RPC: Iniciando Classes de evento.
O Bulk Load é um tipo de pedido especial usado por operações de inserção em massa, como o utilitário bcp.exe, a interface OleDB IRowsetFastLoad ou pela classe SQLBulkCopy de gerenciamento. O Bulk Load é diferente dos outros pedidos, porque é o único pedido que inicia a execução antes que esteja completo no protocolo TDS. Isso permite iniciar a execução e, em seguida, começa a consumir o fluxo de dados para a inserção.
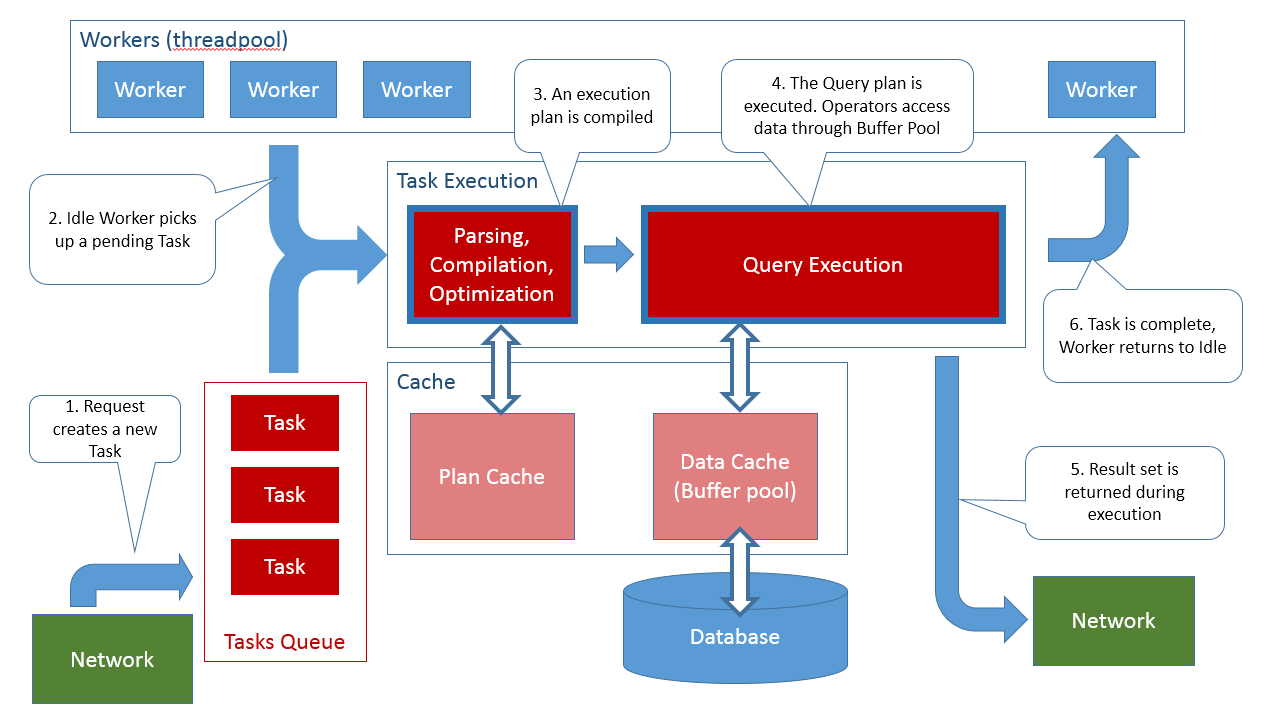
Após um pedido TDS completo atingir o motor de banco de dados SQL Server, este criará uma tarefa para manipular a solicitação recebida. A lista de solicitações do servidor pode ser consultada a partir de sys.dm_exec_requests.
Tarefas
A tarefa acima mencionada será criada para lidar com o pedido do início até sua conclusão. Por exemplo, se o pedido for feito em um lote SQL, a tarefa irá representar todo o lote, e não apenas as declarações individuais. Declarações individuais dentro do lote SQL não criarão novas tarefas. Certas declarações individuais dentro do lote podem ser executadas em paralelo (muitas vezes referido como DOP, um alto grau de paralelismo) e, no caso, a tarefa vai gerar novas sub-tarefas para executar em paralelo. Se a solicitação retorna um resultado, o lote está completo quando o resultado é completamente consumido pelo cliente (por exemplo, quando descartado o SqlDataReader). Você pode ver a lista de tarefas do servidor, consultando a ferramenta sys.dm_os_tasks.
Quando uma nova solicitação chega ao servidor e a tarefa é criada para lidar com esse pedido, em estado pendente, o servidor ainda não tem ideia do que o pedido realmente trata. A tarefa tem de iniciar a execução em primeiro lugar, e para isso o motor deve atribuir um trabalhador (worker) a ele.
Agentes de trabalho (workers)
Os trabalhadores ou workers são o pool de threads do SQL Server. Um número de trabalhadores é criado inicialmente pelo servidor para que este possa iniciar sem demora e outros mais podem ser criados sob demanda até o limite da configuração do parâmetro max worker threads. Apenas os workers executam código, pois estão à espera de tarefas pendentes para se tornarem disponíveis (a partir de solicitações que chegam ao servidor) e, em seguida, cada worker leva exatamente uma tarefa para si, para que seja executada. O worker permanecerá ocupado até que a tarefa termine completamente. As tarefas que estão pendentes, quando não há mais workers disponíveis, terão que esperar até que uma das tarefas em execução seja concluída e o worker que executa essa tarefa torne-se disponível para executar outra tarefa pendente. Para um lote SQL solicitar ao worker que pegue essa tarefa, será necessário executar todo o lote de instruções SQL (cada declaração). Isso deve resolver a questão.
Muitas vezes perguntou-se se as declarações em um lote SQL (=> pedido => tarefa => worker) podem executar tarefas em paralelo: a resposta é não; como eles são executados em um único segmento (=> worker), cada declaração deve ser concluída antes de começar a próxima.
Para instruções que usam internamente paralelismo (DOP> 1) e criação de sub-tarefas, cada sub-tarefa passa por exatamente o mesmo ciclo: ela é criada como pendente e um worker deve buscá-la e executá-la (um worker diferente do lote do worker SQL). As listas e o estado dos workers no interior do SQL Server podem ser vistos por meio de uma consulta ao sys.dm_os_workers.
Análise e compilação
Uma vez que uma tarefa inicia a execução de um pedido, a primeira coisa que precisamos fazer é entender o conteúdo do pedido. Nesta fase, o SQL Server irá se comportar como uma linguagem interpretada VM: o texto T-SQL dentro do pedido será analisado e uma árvore de sintaxe abstrata será criada para representar o pedido. O pedido inteiro (lote) é analisado e compilado. Se ocorrer um erro nesta fase, os pedidos terminam com um erro de compilação (o pedido então é completado, a tarefa é concluída e o worker fica livre para pegar outra tarefa pendente). O SQL e o T-SQL são linguagens declarativas e que possuem consultas extremamente complexas (como as consultas SELECT e suas várias associações).
A compilação de lotes T-SQL não resulta em um código executável semelhante a instruções nativas da CPU e nem mesmo semelhantes a instruções em linha de comando ou bytecode JVM, mas, em vez disso, resulta principalmente em planos de acesso de dados (ou planos de consulta). Esses planos descrevem a maneira como consultamos tabelas e índices, pesquisamos e localizamos linhas de interesse, além de como fazemos quaisquer manipulações de dados, conforme solicitado no lote de instruções SQL. Por exemplo, um plano de consulta irá descrever um caminho de acesso como “open index idx1 on table t, locate the row with the key ‘k’ and return the columns a and b’.
Observação importante: um erro comum gerado pelos desenvolvedores é obtido quando estão tentando chegar a uma única consulta T-SQL que cobre muitas alternativas de consulta, geralmente usando expressões inteligentes na cláusula WHERE, muitas vezes tendo como resultados muitos dados ou alternativas (por exemplo, (COLUMN = @parâmetro ou parâmetro IS NULL). Para os desenvolvedores tentarem manter as coisas mais limpas e evitarem a repetição de consultas, boas práticas para consultas SQL são bem-vindas. A compilação das consultas deve chegar a um ponto em que funciona com qualquer valor de parâmetros de entrada e o resultado é ótimo. Também os incentivo a ler a Pesquisa de Condições Dinâmicas em T-SQL, caso queiram saber mais sobre esse assunto.
Otimização
Falando em escolher um caminho de acesso de dados ideal, esta é a próxima etapa do ciclo de vida do pedido: a otimização. Em SQL e em T-SQL, otimização significa escolher o melhor caminho de acesso aos dados de todas as formas possíveis. Considere que, se você tem uma consulta simples com junção entre duas tabelas e cada tabela tem um índice adicional onde existem quatro possíveis maneiras de acessar os dados, o número de possibilidades cresce exponencialmente com o aumento da complexidade da consulta, e mais caminhos de acesso alternativos estão disponíveis (basicamente, mais índices). Acrescente a isso o fato de que o JOIN (a junção entre duas ou mais tabelas) pode ser feito de várias formas (consulta aninhada, misturada, fusão de consultas etc.), e aí você poderá notar por que a otimização é um conceito tão importante em SQL.
O SQL Server utiliza um otimizador de consultas, o que significa que ele irá considerar todas (ou pelo menos muitas) das alternativas possíveis, tentar dar um palpite sobre o custo (em termos de desempenho) de cada alternativa encontrada e, em seguida, escolher aquela com o menor custo e a mais rápida. O custo é calculado considerando principalmente o tamanho dos dados que teriam de ser lidos em cada alternativa de consulta. Com a finalidade de chegar a esse custo, o SQL Server precisa saber o tamanho de cada tabela e a distribuição dos valores da coluna e quais recursos estão disponíveis a partir das estatísticas associadas com os dados. Outros fatores considerados são o consumo de CPU e memória necessária para cada plano alternativo. Usando fórmulas ajustadas ao longo de muitos anos de aprimoramento, esses fatores são sintetizados em um valor de custo único para cada alternativa e, em seguida, a alternativa com o menor custo é escolhida como plano de consulta a ser utilizado.
Explorar todas essas alternativas pode ser demorado e é por isso que, uma vez que um plano de consulta é criado, este também é armazenado em cache para reutilização futura em consultas com valores parecidos. Futuras consultas semelhantes podem pular a fase de otimização, se puderem encontrar um plano de consulta já compilado e otimizado no cache interno do SQL Server. Para uma discussão mais longa sobre o assunto, leia o documento Plano de Execução e reutilização do Cache.
Execução
Uma vez que um plano de consulta é escolhido pelo otimizador, o pedido pode ser executado. O plano de consulta é traduzido em uma árvore de execução real. Cada nó nessa árvore é um operador. Todos os operadores de implementação de uma interface abstrata contêm três métodos: open(), next(), close(). O loop de execução consiste em chamar o método open() do operador que está na raiz da árvore, em seguida, chamar next() repetidamente até que ele retorne falso (ou seja, nenhuma consulta será a próxima a ser executada) e, finalmente, chamar close(). O operador na raiz da árvore vai, por sua vez, executar a mesma operação em cada um dos seus operadores filhos, e estes, por sua vez, chamarão os mesmos métodos nos seus operadores filhos, e assim por diante. Nas folhas das árvores, geralmente há operadores de acesso físico que realmente recuperam dados de tabelas e índices. Nos níveis intermediários, existem operadores que implementam várias operações de dados, como filtragem de dados, realização de junções ou de ordenação das linhas. As consultas que utilizam paralelismo usam um operador especial chamado de operador de câmbio. O operador de câmbio lança múltiplas threads (tarefas => workers) em execução e pede a cada thread para executar uma sub-árvore do plano de consulta. Em seguida, ele agrega a saída desses operadores, usando um típico problema de consumidor-produtor padrão. Uma excelente descrição desse modelo de execução pode ser encontrada no documento Volcanoo – Um extensível sistema de paralelismo e evolução de querys.
Esse modelo de execução não se aplica apenas às consultas, mas também à modificação de dados (insert, delete, update). Existem operadores que lidam com a inserção de uma linha, operadores que lidam com a exclusão de uma linha e operadores que lidam com a atualização de uma linha.
Algumas solicitações criam de planos de execução triviais (como INSERT INTO … VALUES …), enquanto outras criam planos extremamente complexos, mas a execução continua sendo idêntica para todos os planos e ocorre apenas como eu descrevi: a árvore de execução é interativa e chama o método next() até sua conclusão.
Alguns operadores são muito simples. Considere, por exemplo, o operador TOP(N): quando next() é chamado sobre ele, só será necessário executar next() em seus operadores filhos e manter uma contagem. Depois de N vezes sendo chamado, ele simplesmente retorna false, terminando, assim, a iteração de sua sub-árvore particular.
Outros operadores têm um comportamento mais complexo. Considere o que um operador de loop aninhado tem que fazer: ele precisa manter o controle sobre a iteração do loop nos operadores filhos externos e internos, chamar next() sobre o operador filho externo, refazer a execução do plano do operador filho interior e chamar o método next() sobre ele até que a solicitação de junção esteja satisfeita (mais detalhes sobre o assunto podem ser encontrados no documento Junção de loops aninhados).
Alguns operadores têm um comportamento de stop-and-go (parar e continuar), o que significa que eles não podem produzir qualquer saída até que consumam toda a entrada de seus operadores filhos próprios. Esses operadores executam a primeira chamada do método next() até que este não retorne mais nada e até que todas as linhas criadas pelos operadores filhos sejam recuperadas e classificadas.
Um operador como hash será complexo e também irá possuir o comportamento stop-and-go: para construir a tabela de hash, terá que chamar o método next() sobre o operador filho até que este retorne false. Em seguida, chame next() sobre o operador filho até que uma correspondência seja encontrada na tabela de hash. As chamadas subsequentes continuam a chamar next() sobre o operador filho e retornam a tabela de hash, até que o operador filho execute next() e este retorne falso (veja o documento Hash para uma discussão mais aprofundada).
***
Na próxima parte, veremos resultados, consulta à memória em execução, organização de dados e data access.
***
Artigo traduzido pela Redação iMasters com autorização do autor. Publicado originalmente em http://rusanu.com/2013/08/01/understanding-how-sql-server-executes-a-query/

De 0 a 10, o quanto você recomendaria este artigo para um amigo?