

Nesta série de artigos, vamos entender o que são as famosas estatísticas no banco de dados e também, quando, por que e quem as utiliza, para posteriormente analisarmos a influência que elas exercem no desempenho do SQL Server, avaliando até que ponto uma estatística desatualizada pode degradar a performance da query.
O assunto foi dividido em dois artigos – no primeiro artigo, foram abordados os principais conceitos, passando por detalhes da estrutura interna e como e quando as estatísticas são criadas e atualizadas. Para esta segunda e última parte da série, vamos analisar o impacto que as estatísticas desatualizadas podem exercer negativamente na performance das querys e também em diferentes estratégias de atualização, provendo o menor impacto possível.
Ambiente para teste
Na tentativa de simular situações mais próximas da realidade, vamos criar o banco de dados DB_Statistics com algumas tabelas. Mas a tabela que realmente importa pra nós é a Teste_Estatisticas que será populada com 3 milhões de registros.
USE MASTER GO CREATE DATABASE DB_Statistics GO -- O Padrão já em ON... somente para confirmar e demonstrar o comando ALTER DATABASE DB_Statistics SET AUTO_CREATE_STATISTICS ON GO ALTER DATABASE DB_Statistics SET AUTO_UPDATE_STATISTICS ON GO
Criando a tabela Teste_Estatisticas e iniciando o processo para inserir os 3 milhões de registros.
USE DB_Statistics
GO
CREATE TABLE dbo.Carga_Teste1
(
First_Name VARCHAR(20) NULL,
Last_Name VARCHAR(20) NULL,
First_Name_Mother VARCHAR(20) NULL,
Last_Name_Mother VARCHAR(20) NULL
)
GO
INSERT INTO dbo.Carga_Teste1 VALUES ('John','Anderson','Mary','Jones');
INSERT INTO dbo.Carga_Teste1 VALUES ('Kate','Walker','Julia','Taylor');
INSERT INTO dbo.Carga_Teste1 VALUES ('Ray','Kennedy','Juliette','Rock');
INSERT INTO dbo.Carga_Teste1 VALUES ('Tom','Jackson','Mary','Johnson');
INSERT INTO dbo.Carga_Teste1 VALUES ('Homer','Simpson','Martha','Smith');
INSERT INTO dbo.Carga_Teste1 VALUES ('John','White','Olivia','Miller');
INSERT INTO dbo.Carga_Teste1 VALUES ('Bill','Elliott','Emma','Moore');
INSERT INTO dbo.Carga_Teste1 VALUES ('James','Morgan','Emily','Davis');
INSERT INTO dbo.Carga_Teste1 VALUES ('Robert','Garcia','Mary','Robinson');
INSERT INTO dbo.Carga_Teste1 VALUES ('Kevin','Bauer','Rachel','Green');
INSERT INTO dbo.Carga_Teste1 VALUES ('Matt','Lewis','Kate','Brown');
INSERT INTO dbo.Carga_Teste1 VALUES ('Bobby','Ewans','Samantha','Ewing');
GO
SELECT TOP 10 * INTO dbo.Carga_Teste2
FROM dbo.Carga_Teste1
ORDER BY 1
GO
SELECT
BS(CHECKSUM(NEWID()))%2 AS RandNum1,
CONVERT(INTEGER, ABS(CHECKSUM(NEWID()))/100.0) AS RandNum2,
Carga_Teste1.First_Name,
Carga_Teste1.Last_Name,
Carga_Teste2.First_Name_Mother,
Carga_Teste2.Last_Name_Mother
INTO dbo.Teste_Estatisticas FROM dbo.Carga_Teste1 CROSS JOIN dbo.Carga_Teste2
GO
CREATE CLUSTERED INDEX idx_Teste_Estatisticas
ON dbo.Teste_Estatisticas (RandNum2)
GO
INSERT INTO dbo.Teste_Estatisticas
SELECT
ABS(CHECKSUM(NEWID()))%2 as RandNum1,
CONVERT(INTEGER,ABS(CHECKSUM(NEWID()))/100.0) as RandNum2,
Carga_Teste2.First_Name,
Carga_Teste2.Last_Name,
Carga_Teste1.First_Name_Mother,
Carga_Teste1.Last_Name_Mother
FROM dbo.Carga_Teste1 CROSS JOIN dbo.Carga_Teste2
GO
INSERT INTO dbo.Teste_Estatisticas
SELECT
ABS(CHECKSUM(NEWID()))%2,
CONVERT(INTEGER,ABS(CHECKSUM(NEWID()))/100.0),
TE1.[First_Name],
TE2.[Last_Name],
TE1.[First_Name_Mother],
TE2.[Last_Name_Mother]
FROM dbo.Teste_Estatisticas TE1 CROSS JOIN dbo.Teste_Estatisticas TE2
GO
INSERT INTO dbo.Teste_Estatisticas
SELECT TOP 2942160
ABS(CHECKSUM(NEWID()))%2,CONVERT(INTEGER,ABS(CHECKSUM(NEWID()))/100.0),
TE2.First_Name,
TE1.Last_Name,
TE2.First_Name_Mother,
TE1.Last_Name_Mother
FROM dbo.Teste_Estatisticas TE1 CROSS JOIN dbo.Teste_Estatisticas TE2
GO
Simplificando, o processo para popular a tabela com 3 milhões de registros utiliza duas tabelas auxiliares, Carga_Teste1 e Carga_Teste2. Com isso, populamos com algumas linhas iniciais e posteriormente utilizando o CROSS JOIN entre elas e inserindo na Teste_Estatisticas – isso mesmo CROSS JOIN. Assim, forçamos o produto cartesiano e assim alcançando as 3 milhões de linhas. Nesse caso, os valores internos não têm nenhuma relevância pra nós, o que realmente importa é quantidade de registros.
Prova real
Vamos alinhar os pensamentos. O intuito principal deste artigo é avaliar se realmente as estatísticas desatualizadas influenciam de forma negativa na performance do SQL Server, certo? Sim, isso mesmo, por isso criamos uma tabela com 3 milhões de registros. E como vamos testar isso? Bom a ideia é simples: simular o que ocorre no dia a dia em uma tabela, gerando grandes alterações na tabela, assim as estatísticas ficaram desatualizadas.
O primeiro passo é alterar o banco para NÃO atualizar mais as estatísticas automaticamente. Executando esse comando, o SQL Server passa para nós a responsabilidade de quando atualizar as estatísticas:
ALTER DATABASE DB_Statistics SET AUTO_CREATE_STATISTICS OFF GO ALTER DATABASE DB_Statistics SET AUTO_UPDATE_STATISTICS OFF GO
Simulando alterações na tabela, inserindo 500 mil e alterando 732110 mil registros. Como as estatísticas foram alteradas para “manual”, com essas operações de DML elas estão totalmente desatualizadas.
INSERT INTO dbo.Teste_Estatisticas SELECT TOP 500000 ABS(CHECKSUM(NEWID()))%2,CONVERT(INTEGER,ABS(CHECKSUM(NEWID()))/100.0), TE2.First_Name, TE1.Last_Name, TE2.First_Name_Mother, TE1.Last_Name_Mother FROM Teste_Estatisticas TE1 CROSS JOIN Teste_Estatisticas TE2 GO DELETE FROM Teste_Estatisticas WHERE RandNum2 < 4500000 GO
Vamos aos resultados. Primeiro, limpe o cache para garantir que o otimizador não utilize nada em memória.
CHECKPOINT GO DBCC DROPCLEANBUFFERS GO DBCC DROPCLEANBUFFERS GO
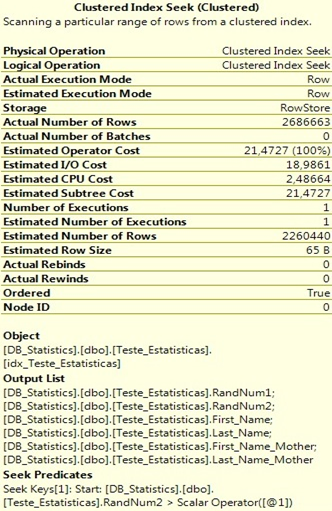
Execute o select e observe o plano de execução gerado para essa query. Lembre-se de que esse plano foi gerado com base nas estatísticas desatualizadas.
SELECT * FROM Teste_Estatisticas WHERE RandNum2 > 5000000
Observe que o otimizador estimou 2260440 mil registros, mas foram retornadas 2686663 linhas (2260440–2686663=426223). O tempo de execução foi de 43 segundos com um esforço de CPU de 2,48664 e com um custo estimado de 21,4727.
Ok, feito isso, atualize as estatísticas, limpe o cache e execute novamente o select.
UPDATE STATISTICS dbo.Teste_Estatisticas GO CHECKPOINT GO DBCC DROPCLEANBUFFERS GO DBCC DROPCLEANBUFFERS GO SELECT * FROM Teste_Estatisticas WHERE RandNum2 > 5000000 GO
Observe o plano de execução:
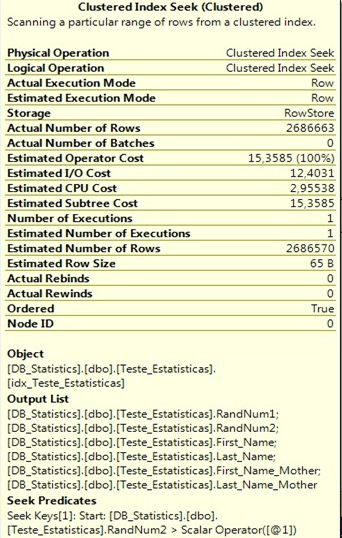
Podemos notar algumas melhorias, como o fato de que foram retornadas 2686663 linhas das 2686570 estimadas (2686663-2686570=96). O tempo de execução foi de 31 segundos (contra 43 segundos da execução anterior) com um esforço de CPU de 2,95538 e com um custo estimado de 15,3585.
Com esse teste, podemos concluir que sim, estatísticas desatualizadas influenciam negativamente no desempenho. Agora imagine se essa query fosse parte de um relatório utilizado por dezenas de usuários e executado centenas de vezes no dia. O impacto final poderia ser muito significante, e isso porque estamos falando de uma única query. Por isso, a manutenção das estatísticas, assim como dos índices, deve ser realizada com muita atenção.
Também deve ser observado que o processo para atualizar as estatistas é “custoso”, por isso deve ser programada e analisada a melhor forma de fazer, e não simplesmente sair atualizando tudo a toda a hora. Dessa forma, estaríamos criando outro problema.
O impacto sempre vai existir, cabe a nós analisar qual estratégia será melhor para nosso ambiente.
Em operações de manipulações de dados, como DELETE, UPDATE, MERGE, a grosso modo, internamente o primeiro processo é localizar os dados e em seguida realizar a operação. Por exemplo, ao executar um comando de DELETE, primeiro é feita a busca dos dados e depois a deleção. Essa busca nada mais é do que um select para localizar esses registros; com isso, em muitos casos, as estatísticas também podem impactar nesse tipo de operação.
Comparação
Em verde o resultado da consulta com as estatísticas atualizadas, e em vermelho o resultado da mesma consulta com as estatistas desatualizadas.
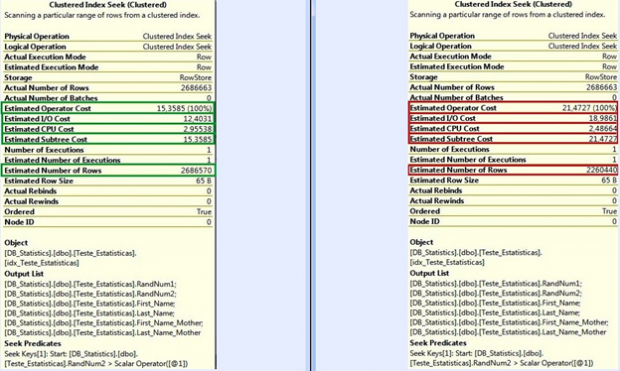
Com esse teste, podemos identificar um ganho aproximado de 20% somente por estar com as estatísticas atualizadas.
E, como disse anteriormente, se pensarmos no ambiente como um todo, onde milhares de consultas são executadas por centenas de usuários, ganhos de segundos em cada operação são muito importantes para manter o ambiente com um nível legal de desempenho.
Grande abraço e bons estudos.

De 0 a 10, o quanto você recomendaria este artigo para um amigo?