

Há muita empolgação com relação ao Big Data e muita confusão também. Este artigo fornecerá uma definição funcional de Big Data e dará uma série de exemplos para que você tenha uma compreensão em primeira mão de alguns dos recursos do Hadoop, a tecnologia líder de software livre no domínio de Big Data. Especificamente, vamos nos concentrar nas seguintes questões.
- O que é Big Data, Hadoop, Sqoop, Hive e Pig, e por que há tanta empolgação nesse espaço?
- Como o Hadoop se relaciona ao IBM DB2 e ao Informix? Essas tecnologias podem ser usadas juntas?
- Como posso começar a usar Big Data? Há exemplos simples que funcionam em um único PC?
- Para os superimpacientes, se já for possível definir Hadoop e quiser trabalhar direto com as amostras de código, faça o seguinte.
- Dispare sua instância do Informix ou DB2.
- Faça o download da imagem VMWare do website da Cloudera e aumente a configuração de RAM da máquina virtual para 1,5 GB.
- Vá até a seção que contém as amostras de código.
- Há uma instância MySQL integrada à imagem VMWare. Se você estiver fazendo os exercícios sem conectividade com a rede, use os exemplos de MySQL.
Para todos os outros, continuem a leitura…
O que é Big Data?
Big Data é grande em quantidade, é capturado a uma taxa rápida e pode ser estruturado ou não estruturado, ou alguma combinação das opções acima. Esses fatores tornam o Big Data difícil de capturar, minar e gerenciar usando métodos tradicionais. Há tanta empolgação nesse espaço que poderia haver um debate extra apenas sobre a definição de big data.
O uso da tecnologia Big Data não é restrita a volumes grandes. Os exemplos neste artigo usam pequenas amostras para ilustrar os recursos da tecnologia. Desde o ano 2012, clusters grandes estão na faixa de 100 petabytes.
Big Data pode ser estruturado e não estruturado. Bancos de dados relacionais tradicionais, como Informix e DB2, fornecem soluções comprovadas para dados estruturados. Por meio da extensibilidade, eles também gerenciam dados não estruturados. A tecnologia Hadoop traz técnicas de programação novas e mais acessíveis para trabalhar em armazenamento de dados massivos com dados estruturados e não estruturados.
Por que toda essa empolgação?
Há muitos fatores que colaboram para a empolgação em torno do Big Data, incluindo o seguinte.
- Unindo computação e armazenamento em um hardware acessível: o resultado é uma velocidade impressionante por um custo baixo.
- Preço e desempenho: a tecnologia Hadoop big data fornece economias consideráveis (pense em um fator de aproximadamente 10) com aprimoramentos significativos de desempenho (novamente, pense em um fator de 10). Sua experiência poderá variar. Se a tecnologia existente pode ser ultrapassada de forma tão contundente, vale a pena examinar se o Hadoop pode complementar ou substituir os aspectos de sua arquitetura atual.
- Escalabilidade linear: toda tecnologia paralela fala sobre incrementações. O Hadoop apresenta escalabilidade genuína e desde o último release está expandindo o limite no número de nós para mais de 4.000.
- Acesso total a dados não estruturados: um armazenamento de dados altamente escalável com um bom modelo de programação paralelo, MapReduce, foi um desafio para o setor durante algum tempo. O modelo de programação do Hadoop não soluciona todos os problemas, mas é uma solução sólida para muitas tarefas
O termo tecnologia disruptiva é usado excessivamente, mas nesse caso pode ser apropriado.
O que é Hadoop?
Veja a seguir várias definições de Hadoop, cada uma visando um público diferente dentro da empresa:
- Para os executivos: Hadoop é um projeto de software livre da Apache que tem como objetivo obter valor do volume/velocidade/variedade incrível de dados sobre sua organização. Use os dados em vez de jogar a maioria fora.
- Para os gerentes técnicos: um conjunto de softwares livres que mina o BigData estruturado e não estruturado de sua empresa. Ele integra com seu ecossistema existente de Business Intelligence.
- Jurídico: um conjunto de software livre empacotado e suportado por diversos fornecedores. Consulte a seção Recursos relacionada à indenização de IP.
- Engenharia: um ambiente de execução Mapear/Reduzir massivamente paralelo, sem compartilhamento e baseado em Java. Pense em centenas a milhares de computadores trabalhando no mesmo problema, com resiliência integrada contra falhas. Projetos no ecossistema Hadoop fornecem carregamento de dados, linguagens de nível superior, implementação automatizada na nuvem e outros recursos.
- Segurança: um suite de software protegido por Kerberos.
Quais são os componentes do Hadoop?
O projeto Apache Hadoop tem dois componentes principais, o armazenamento de arquivo chamado Hadoop Distributed File System (HDFS) e a estrutura de programação chamada MapReduce. Há diversos projetos de suporte que aproveitam HDFS e MapReduce. Esse artigo fornecerá um resumo e o incentivará a obter o livro de OReily “Hadoop The Definitive Guide”, terceira edição, para obter mais detalhes.
As definições abaixo servem para fornecer uma base suficiente para você usar os exemplos de código a seguir. Este artigo tem a intenção de ajudá-lo a experimentar a tecnologia. Este é um artigo de instruções mais do que um artigo de definição ou discussão.
- HDFS: se você quiser que 4000+ computadores funcionem em seus dados, é melhor espalhar seus dados em 4000+ computadores. HDFS faz isso para você. HDFS tem algumas partes móveis. O Datanodes armazena seus dados e o Namenode controla onde suas coisas são armazenadas. Há outras partes, mas você tem o suficiente para começar.
- MapReduce: esse é o modelo programático para Hadoop. Há duas fases, chamados sem surpresa de Map e Reduce. Para impressionar seus amigos, avise-os de que há uma classificação aleatória entre a fase Map e Reduce. O JobTracker gerenciar os 4000+ componentes de seu trabalho MapReduce. O TaskTrackers recebe ordens do JobTracker. Se você gostar de Java, codifique em Java. Se você gostar de SQL ou de outras linguagens diferentes de Java você ainda estará com sorte, é possível usar um utilitário chamado Hadoop Streaming.
- Hadoop Streaming: um utilitário que permite ao MapReduce codificar em qualquer linguagem: C, Perl, Python, C++, Bash etc. Os exemplos incluem um mapeador Python e um redutor AWK.
- Hive e Hue: se você gosta de SQL, ficará feliz em saber que é possível escrever em SQL e fazer com que o Hive o converta para um trabalho do MapReduce. Não, você não vai ter um ambiente completo ANSI-SQL, mas obterá 4000 notas e escalabilidade de diversos petabytes. Hue proporciona uma interface gráfica baseada no navegador para executar seu trabalho de Hive.
- Pig: um ambiente de programação de nível superior para realização da codificação de MapReduce. A linguagem Pig é chamada Pig Latin. Talvez você considere as convenções de nomeação não convencionais, mas você obtém uma relação desempenho-preço incrível e alta disponibilidade.
- Sqoop: fornece transferência de dados bidirecional entre o Hadoop e seu banco de dados relacional favorito.
- Oozie: gerencia o fluxo de trabalho do Hadoop. Isso não substitui seu planejador e suas ferramentas de BPM, mas fornece a ramificação se-então-senão e controle dentro de seus trabalhos do Hadoop.
- HBase: Um armazenamento superescalável e de valor chave. Funcione muito como um hashmap persistente (para fãs de python pense em dicionário). Não é um banco de dados relacional, apesar do nome HBase.
- FlumeNG: um loader em tempo real para transmissão de seus dados para o Hadoop. Ele armazena dados no HDFS e HBase. Convém usar o FlumeNG, que passou por aprimoramentos com relação ao flume original.
- Whirr: fornecimento na nuvem para Hadoop. É possível iniciar um cluster em apenas alguns minutos com um arquivo de configuração muito pequeno.
- Mahout: aprendizado automático para Hadoop. Usado para análise preditiva e outras análises avançadas.
- Fuse: faz o sistema HDFS parecer com um sistema de arquivos regular, de modo que você possa usar ls, rm, cd e outros em dados do HDFS
- Zookeeper: usado para gerenciar a sincronização para o cluster. Você não trabalhará muito com o Zookeeper, mas ele está trabalhando muito por você. Se você acha que é necessário escrever um programa que usa o Zookeeper talvez você seja muito, muito inteligente e poderia ser um comitê para um projeto Apache, ou você está preste a ter um péssimo dia.
A Figura 1 mostra as principais partes do Hadoop.

HDFS, as camadas inferiores, ficam sob um cluster de hardware acessível. Servidores simples montados em rack, cada um com duas CPUs Hex core, 6 a 12 discos e 32 gb de ram. Para uma tarefa de map-reduce, a camada do mapeador lê nos discos com uma velocidade muito alta. O mapeador emite pacres de valores de chave que são armazenados e apresentados ao redutor, e a camada de redução resume os pares de valores de chave. Não, não é necessário resumir. É possível ter uma tarefa de map-reduce que possua somente mapeadores. Isso deve ficar mais fácil de entender quando você chega ao exemplo de python-awk.
Como ocorre a integração do Hadoop com minha infraestrutura Informix ou DB2?
O Hadoop realiza a integração muito bem com seus bancos de dados Informix e DB2 com Sqoop. Sqoop é a implementação de software livre líder para movimentação de dados entre o Hadoop os bancos de dados relacionais. Ele usa JDBC para ler e escrever Informix, DB2, MySQL, Oracle de outras fontes. Há adaptadores otimizados para diversos bancos de dados, incluindo Netezza e DB2. Consulte a seção Recursos sobre como baixar esses adaptadores. Os exemplos são todos específicos ao Sqoop.
Introdução: como executar exemplos simples de Hadoop, Hive, Pig, Oozie e Sqoop
Acabamos com introduções e definições, agora é hora da parte boa. Para continuar, será necessário baixar o VMWare, caixa virtual ou outras imagens do website da Cloudera e começar a realizar o MapReduce! A imagem virtual supõe que você tem um computador com 64 bits e um dos ambientes de virtualização populares. A maioria dos ambientes de virtualização tem download gratuito. Quando você tenta iniciar uma imagem virtual de 64 bits talvez receba reclamações sobre as configurações de BIOS. A Figura 2 mostra a alteração necessária no BIOS, nesse caso em um Thinkpad™. Tenha cuidado ao fazer alterações. Alguns pacotes de segurança corporativos exigirão uma senha após uma alteração do BIOS, antes do sistema reiniciar.

O big data usado aqui é na verdade pequeno. O objetivo não é fazer seu laptop pegar fogo por tentar trabalhar com um arquivo gigante, mas mostrar a você as fontes de dados interessantes e as tarefas de map-reduce que respondem a questões significativas.
Faça o download da imagem virtual do Hadoop
É recomendado que você use a imagem da Cloudera para execução desses exemplos. Hadoop é uma tecnologia que resolve problemas. O empacotamento da imagem da Cloudera permite que você se concentre nas questões de big-data. Porém, se você decidir montar todas as partes por conta própria, Hadoop será um problema, não a solução.
Faça o download de uma imagem. A imagem CDH4, a oferta mais recente está disponível aqui: Imagem CDH4. A versão anterior, CDH3, está disponível aqui: Imagem CDH3.
Você tem sua opção de tecnologias de virtualização. É possível baixar um ambiente de virtualização gratuito da VMWare e de outros. Por exemplo, acesse vmware.com e baixe o vmware-player. Provavelmente, seu laptop está executando o Windows, portanto, você baixaria o vmware-player para windows. Os exemplos neste artigo usarão o VMWare e a execução do Ubuntu Linux usando “tar” em vez de “winzip” ou equivalente.
Após o download, descompacte com untar/unzip da seguinte maneira: tar -zxvf cloudera-demo-vm-cdh4.0.0-vmware.tar.gz.
Ou, se você estiver usando CDH3, use o seguinte: tar -zxvf cloudera-demo-vm-cdh3u4-vmware.tar.gz
Unzip normalmente funciona em arquivos tar. Após a descompactação, é possível disparar a imagem da seguinte maneira:
vmplayer cloudera-demo-vm.vmx.
Agora você verá uma tela que parece com o que é exibido na Figura 3.
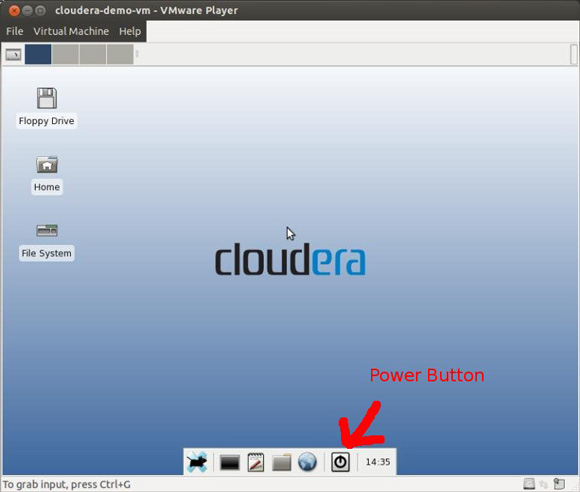
O comando vmplayer funciona corretamente e inicia a máquina virtual. Se você estiver usando CDH3, será necessário desligar a máquina e alterar as configurações de memória. Use o ícone do botão de energia ao lado do relógio na parte inferior central da tela para desligar a máquina virtual. Dessa forma, você tem acesso de edição às configurações da máquina virtual.
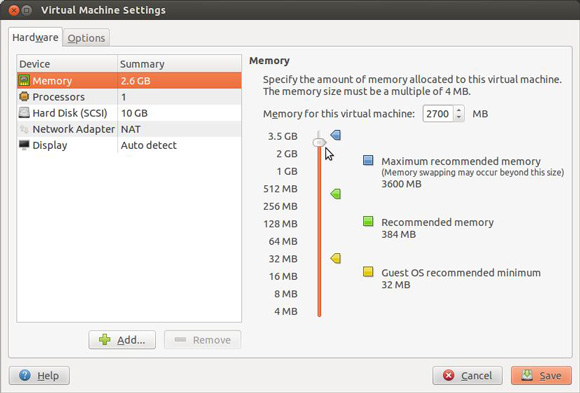
Para CDH3 a próxima etapa é turbinar a imagem virtual com mais RAM. A maioria das configurações pode ser alterada somente com a máquina virtual desligada. A Figura 4 mostra como acessar a configuração e aumentar a RAM alocada para mais de 2 GB.
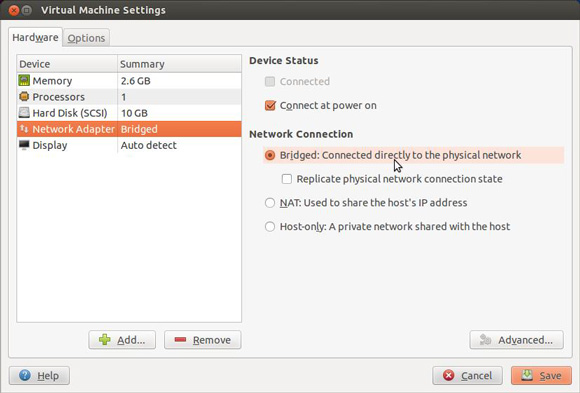
Como mostra a Figura 5, é possível alterar a configuração de rede para bridged. Com essa configuração, a máquina virtual obterá seu próprio endereço IP. Se isso criar problemas em sua rede, será possível usar, como opção, Network Address Translation (NAT). Você usará a rede para se conectar ao banco de dados.
Você é limitado pela RAM no sistema host, portanto, não tente alocar mais RAM do que existe em seu computador. Se você o fizer, o computador executará muito lentamente.
Agora, o momento que você estava aguardando, vá em frente e ligue a máquina virtual. O usuário cloudera é conectado automaticamente na inicialização. Se for necessária, a senha da Cloudera é: cloudera.
Instale o Informix e DB2
É necessário um banco de dados com o qual trabalhar. Se você ainda não tiver um banco de dados, baixe o Informix Developer edition aqui ou o DB2 Express-C Edition gratuito.
Uma alternativa para a instalação do DB2 é fazer o download da imagem da VMWare que já possui o DB2 instalado em um sistema operacional SuSE Linux. Faça login como raiz, com a senha: password.
Troque para o ID do usuário db2inst1. Trabalhar como raiz é como dirigir um carro sem o cinto de segurança. Converse com seu DBA local sobre como executar o banco de dados. Este artigo não cobrirá isso aqui. Não tente instalar o banco de dados dentro da imagem virtual da Cloudera, pois não há espaço livre em disco suficiente.
A máquina virtual será conectada ao banco de dados usando o Sqoop, que exige um driver JDBC. Será necessário o driver JDBC para seu banco de dados na imagem virtual. É possível instalar o driver Informix aqui.
O driver DB2 está localizado aqui: http://www.ibm.com/services/forms/preLogin.do?source=swg-idsdjs ou http://www-01.ibm.com/support/docview.wss?rs=4020&uid=swg21385217.
A instalação do driver Informix JDBC (lembre-se, somente o driver dentro da imagem virtual, não do banco de dados) é exibida na Listagem 1.
tar -xvf ../JDBC.3.70.JC5DE.tar followed by java -jar setup.jar
Observação: selecione um subdiretório relativo a /home/cloudera para não precisar da permissão raiz para a instalação.
O driver DB2 JDBC está no formato compactado. Basta descompactá-lo no diretório de destino, como mostra a Listagem 2.
mkdir db2jdbc cd db2jdbc unzip ../ibm_data_server_driver_for_jdbc_sqlj_v10.1.zip
Uma rápida introdução ao HDFS e ao MapReduce
Antes de começar a mover os dados entre seu banco de dados relacional e o Hadoop, é necessária uma rápida introdução ao HDFS e ao MapReduce. Há muitos tutoriais no estilo “hello world” para Hadoop, portanto, os exemplos aqui servem apenas para fornecer uma base suficiente para os exercícios de banco de dados, para que eles façam sentido para você.
O HDFS fornece armazenamento nos nós de seu cluster. A primeira etapa no uso do Hadoop é colocar os dados no HDFS. O código exibido na Listagem 3 obtém uma cópia de um livro por Mark Twain e um livro por James Fenimore Cooper e copia esses textos no HDFS.
# install wget utility into the virtual image sudo yum install wget # use wget to download the Twain and Cooper's works $ wget -U firefox http://www.gutenberg.org/cache/epub/76/pg76.txt $ wget -U firefox http://www.gutenberg.org/cache/epub/3285/pg3285.txt # load both into the HDFS file system # first give the files better names # DS for Deerslayer # HF for Huckleberry Finn $ mv pg3285.txt DS.txt $ mv pg76.txt HF.txt # this next command will fail if the directory already exists $ hadoop fs -mkdir /user/cloudera # now put the text into the directory $ hadoop fs -put HF.txt /user/cloudera # way too much typing, create aliases for hadoop commands $ alias hput="hadoop fs -put" $ alias hcat="hadoop fs -cat" $ alias hls="hadoop fs -ls" # for CDH4 $ alias hrmr="hadoop fs -rm -r" # for CDH3 $ alias hrmr="hadoop fs -rmr" # load the other article # but add some compression because we can $ gzip DS.txt # the . in the next command references the cloudera home directory # in hdfs, /user/cloudera $ hput DS.txt.gz . # now take a look at the files we have in place $ hls Found 2 items -rw-r--r-- 1 cloudera supergroup 459386 2012-08-08 19:34 /user/cloudera/DS.txt.gz -rw-r--r-- 1 cloudera supergroup 597587 2012-08-08 19:35 /user/cloudera/HF.txt
Agora, você possui dois arquivos em um diretório no HDFS. Calma, contenha sua empolgação. Sério, em um único nó e com apenas um megabyte, isso é tão empolgante quanto assistir a uma tinta secar na parede. Mas se fosse um cluster com 400 nós, e você tivesse 5 petabytes ativos, realmente seria difícil conter o entusiasmo.
Muitos dos tutoriais de Hadoop usam o exemplo de contagem de palavras incluído no arquivo jar de exemplo. Parece que muitas análises envolvem contagem e agregação. O exemplo na Listagem 4 mostra como invocar o contador de palavras.
# hadoop comes with some examples # this next line uses the provided java implementation of a # word count program # for CDH4: hadoop jar /usr/lib/hadoop-0.20-mapreduce/hadoop-examples.jar wordcount HF.txt HF.out # for CDH3: hadoop jar /usr/lib/hadoop/hadoop-examples.jar wordcount HF.txt HF.out # for CDH4: hadoop jar /usr/lib/hadoop-0.20-mapreduce/hadoop-examples.jar wordcount DS.txt.gz DS.out # for CDH3: hadoop jar /usr/lib/hadoop/hadoop-examples.jar wordcount DS.txt.gz DS.out
O sufixo .gz no DS.txt.gz informa ao Hadoop para lidar com a descompactação como parte do processamento de Map-Reduce. Cooper é um pouco detalhista, por isso merece a compactação.
Há muitos fluxos de mensagens na execução de seu trabalho de contagem de palavras. Hadoop gosta fornecer muitos detalhes sobre os programas de Mapeamento e Redução em execução em seu nome. As linhas críticas que você deseja procurar são exibidas na Listagem 5, incluindo uma segunda listagem de tarefas sem êxito e como corrigir um dos erros mais comuns que você encontrará na execução do MapReduce.
$ hadoop jar /usr/lib/hadoop/hadoop-examples.jar wordcount HF.txt HF.out 12/08/08 19:23:46 INFO input.FileInputFormat: Total input paths to process : 1 12/08/08 19:23:47 WARN snappy.LoadSnappy: Snappy native library is available 12/08/08 19:23:47 INFO util.NativeCodeLoader: Loaded the native-hadoop library 12/08/08 19:23:47 INFO snappy.LoadSnappy: Snappy native library loaded 12/08/08 19:23:47 INFO mapred.JobClient: Running job: job_201208081900_0002 12/08/08 19:23:48 INFO mapred.JobClient: map 0% reduce 0% 12/08/08 19:23:54 INFO mapred.JobClient: map 100% reduce 0% 12/08/08 19:24:01 INFO mapred.JobClient: map 100% reduce 33% 12/08/08 19:24:03 INFO mapred.JobClient: map 100% reduce 100% 12/08/08 19:24:04 INFO mapred.JobClient: Job complete: job_201208081900_0002 12/08/08 19:24:04 INFO mapred.JobClient: Counters: 26 12/08/08 19:24:04 INFO mapred.JobClient: Job Counters 12/08/08 19:24:04 INFO mapred.JobClient: Launched reduce tasks=1 12/08/08 19:24:04 INFO mapred.JobClient: SLOTS_MILLIS_MAPS=5959 12/08/08 19:24:04 INFO mapred.JobClient: Total time spent by all reduces... 12/08/08 19:24:04 INFO mapred.JobClient: Total time spent by all maps waiting... 12/08/08 19:24:04 INFO mapred.JobClient: Launched map tasks=1 12/08/08 19:24:04 INFO mapred.JobClient: Data-local map tasks=1 12/08/08 19:24:04 INFO mapred.JobClient: SLOTS_MILLIS_REDUCES=9433 12/08/08 19:24:04 INFO mapred.JobClient: FileSystemCounters 12/08/08 19:24:04 INFO mapred.JobClient: FILE_BYTES_READ=192298 12/08/08 19:24:04 INFO mapred.JobClient: HDFS_BYTES_READ=597700 12/08/08 19:24:04 INFO mapred.JobClient: FILE_BYTES_WRITTEN=498740 12/08/08 19:24:04 INFO mapred.JobClient: HDFS_BYTES_WRITTEN=138218 12/08/08 19:24:04 INFO mapred.JobClient: Map-Reduce Framework 12/08/08 19:24:04 INFO mapred.JobClient: Map input records=11733 12/08/08 19:24:04 INFO mapred.JobClient: Reduce shuffle bytes=192298 12/08/08 19:24:04 INFO mapred.JobClient: Spilled Records=27676 12/08/08 19:24:04 INFO mapred.JobClient: Map output bytes=1033012 12/08/08 19:24:04 INFO mapred.JobClient: CPU time spent (ms)=2430 12/08/08 19:24:04 INFO mapred.JobClient: Total committed heap usage (bytes)=183701504 12/08/08 19:24:04 INFO mapred.JobClient: Combine input records=113365 12/08/08 19:24:04 INFO mapred.JobClient: SPLIT_RAW_BYTES=113 12/08/08 19:24:04 INFO mapred.JobClient: Reduce input records=13838 12/08/08 19:24:04 INFO mapred.JobClient: Reduce input groups=13838 12/08/08 19:24:04 INFO mapred.JobClient: Combine output records=13838 12/08/08 19:24:04 INFO mapred.JobClient: Physical memory (bytes) snapshot=256479232 12/08/08 19:24:04 INFO mapred.JobClient: Reduce output records=13838 12/08/08 19:24:04 INFO mapred.JobClient: Virtual memory (bytes) snapshot=1027047424 12/08/08 19:24:04 INFO mapred.JobClient: Map output records=113365
O que significam todas as mensagens? Hadoop realizou muito trabalho e está tentando falar com você sobre isso, incluindo o seguinte.
- Verificou se o arquivo de entrada existe.
- Verificou se o diretório de saída existe e, se existisse, seria necessário abortar a tarefa. Nada pior do que sobrescrever horas de computação devido a um simples erro de teclado.
- Distribuiu o arquivo jar de Java a todos os nós responsáveis pela realização do trabalho. Nesse caso, esse é apenas um nó.
- Executou a fase de mapeador da tarefa. Normalmente, isso analisa o arquivo de entrada e emite um par de valores de chave. Observe que a chave e os valores podem ser objetos.
- Executou a fase de classificação, que classifica o resultado do mapeador com base na chave.
- Executou a fase de redução, isso normalmente resume o fluxo de valor de chave e grava o resultado no HDFS.
- Criou muitas métricas durante o progresso.
A Figura 6 mostra uma página da web de amostra de métricas da tarefa do Hadoop após a execução do exercício Hive.
![]()
# way too much typing, create aliases for hadoop commands $ alias hput="hadoop fs -put" $ alias hcat="hadoop fs -cat" $ alias hls="hadoop fs -ls" $ alias hrmr="hadoop fs -rmr" # first list the output directory $ hls /user/cloudera/HF.out Found 3 items -rw-r--r-- 1 cloudera supergroup 0 2012-08-08 19:38 /user/cloudera/HF.out/_SUCCESS drwxr-xr-x - cloudera supergroup 0 2012-08-08 19:38 /user/cloudera/HF.out/_logs -rw-r--r-- 1 cl... sup... 138218 2012-08-08 19:38 /user/cloudera/HF.out/part-r-00000 # now cat the file and pipe it to the less command $ hcat /user/cloudera/HF.out/part-r-00000 | less # here are a few lines from the file, the word elephants only got used twice elder, 1 eldest 1 elect 1 elected 1 electronic 27 electronically 1 electronically, 1 elegant 1 elegant!--'deed 1 elegant, 1 elephants 2
Caso você execute a mesma tarefa duas vezes e se esqueça de excluir o diretório de saída, você receberá as mensagens de erro exibidas na Listagem 7. Corrigir esse erro é tão simples quanto excluir o diretório.
# way too much typing, create aliases for hadoop commands $ alias hput="hadoop fs -put" $ alias hcat="hadoop fs -cat" $ alias hls="hadoop fs -ls" $ alias hrmr="hadoop fs -rmr" $ hadoop jar /usr/lib/hadoop/hadoop-examples.jar wordcount HF.txt HF.out 12/08/08 19:26:23 INFO mapred.JobClient: Cleaning up the staging area hdfs://0.0.0.0/var/l... 12/08/08 19:26:23 ERROR security.UserGroupInformation: PriviledgedActionException as:cloudera (auth:SIMPLE) cause:org.apache.hadoop.mapred.FileAlreadyExistsException: Output directory HF.out already exists org.apache.hadoop.mapred.FileAlreadyExistsException: Output directory HF.out already exists at org.apache.hadoop.mapreduce.lib.output.FileOutputFormat. checkOutputSpecs(FileOutputFormat.java:132) at org.apache.hadoop.mapred.JobClient$2.run(JobClient.java:872) at org.apache.hadoop.mapred.JobClient$2.run(JobClient.java:833) .... lines deleted # the simple fix is to remove the existing output directory $ hrmr HF.out # now you can re-run the job successfully # if you run short of space and the namenode enters safemode # clean up some file space and then $ hadoop dfsadmin -safemode leave
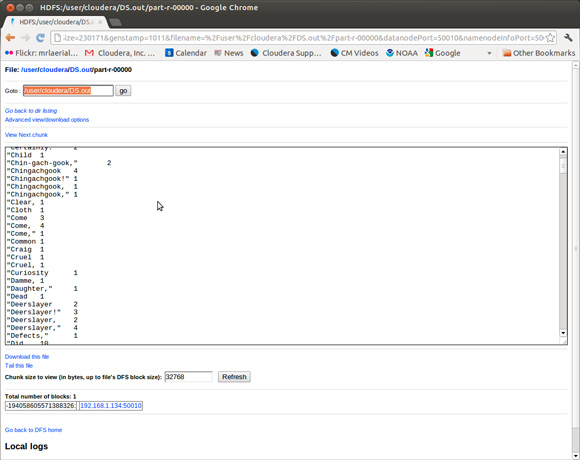
O Hadoop inclui uma interface de navegador para inspecionar o status do HDFS. A Figura 7 mostra a saída da tarefa de contagem de palavras.
 Um console mais sofisticado está disponível gratuitamente no website da Cloudera. Ele fornece vários recursos além das interfaces web padrão do Hadoop. Perceba que o status de funcionamento do HDFS na Figura 8 é exibido como Bad.
Um console mais sofisticado está disponível gratuitamente no website da Cloudera. Ele fornece vários recursos além das interfaces web padrão do Hadoop. Perceba que o status de funcionamento do HDFS na Figura 8 é exibido como Bad.
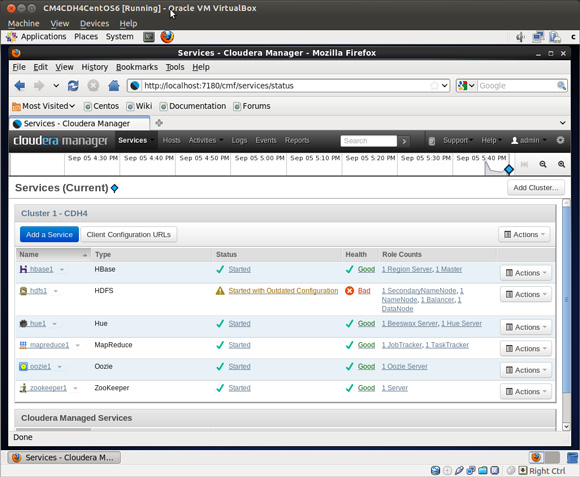
Por que é Bad? Pois em uma única máquina virtual, o HDFS não pode fazer três cópias dos blocos de dados. Quando os blocos são replicados em menor número, há um risco de perda de dados, portanto o funcionamento do sistema é ruim. Que bom que você não está tentando executar tarefas de produção do Hadoop em um único nó.
Você não está limitado a Java para suas tarefas de MapReduce. Esse último exemplo de MapReduce usa Hadoop Streaming para suportar um mapeador escrito em Python e um redutor usando AWK. Não, não é necessário ser um guru de Java para escrever Map-Reduce!
Mark Twain não era um grande fã de Cooper. Nesse caso de uso, Hadoop fornecerá algumas críticas literárias simples comparando Twain e Cooper. O teste Flesch–Kincaid calcula o nível de legibilidade de um texto específico. Um dos fatores nessa análise é o tamanho médio das sentenças. A análise de sentenças acaba se tornando mais complicada do que apenas procurar pelo caractere de ponto. Os pacotes openNLP e Python NLTK têm excelentes analisadores de sentença. Para manter a simplicidade, o exemplo exibido na Listagem 8 usará o tamanho da palavra como um substituto para o número de sílabas em uma palavra. Se você quiser levar isso para o próximo nível, implemente o teste Flesch–Kincaid no MapReduce, rastreie a web e calcule os níveis de leitura para seus sites de notícias favoritos.
# here is the mapper we'll connect to the streaming hadoop interface # the mapper is reading the text in the file - not really appreciating Twain's humor # # modified from # http://www.michael-noll.com/tutorials/writing-an-hadoop-mapreduce-program-in-python/ $ cat mapper.py #!/usr/bin/env python import sys # read stdin for linein in sys.stdin: # strip blanks linein = linein.strip() # split into words mywords = linein.split() # loop on mywords, output the length of each word for word in mywords: # the reducer just cares about the first column, # normally there is a key - value pair print '%s %s' % (len(word), 0)
A saída do mapeador, para a palavra “Twain”, seria: 5 0. Os tamanhos da palavra numérica são classificados em ordem e apresentados ao redutor em ordem classificada. Nos exemplos exibidos nas Listagens 9 e 10, a classificação dos dados não é exigida para obter a saída correta, mas a classificação é integrada à infraestrutura de MapReduce e ocorrerá de qualquer forma.
# the awk code is modified from http://www.commandlinefu.com
# awk is calculating
# NR - the number of words in total
# sum/NR - the average word length
# sqrt(mean2/NR) - the standard deviation
$ cat statsreducer.awk
awk '{delta = $1 - avg; avg += delta / NR; \
mean2 += delta * ($1 - avg); sum=$1+sum } \
END { print NR, sum/NR, sqrt(mean2 / NR); }'
# test locally # because we're using Hadoop Streaming, we can test the # mapper and reducer with simple pipes # the "sort" phase is a reminder the keys are sorted # before presentation to the reducer #in this example it doesn't matter what order the # word length values are presented for calculating the std deviation $ zcat ../DS.txt.gz | ./mapper.py | sort | ./statsreducer.awk 215107 4.56068 2.50734 # now run in hadoop with streaming # CDH4 hadoop jar /usr/lib/hadoop-mapreduce/hadoop-streaming.jar \ -input HF.txt -output HFstats -file ./mapper.py -file \ ./statsreducer.awk -mapper ./mapper.py -reducer ./statsreducer.awk # CDH3 $ hadoop jar /usr/lib/hadoop-0.20/contrib/streaming/hadoop-streaming-0.20.2-cdh3u4.jar \ -input HF.txt -output HFstats -file ./mapper.py -file ./statsreducer.awk \ -mapper ./mapper.py -reducer ./statsreducer.awk $ hls HFstats Found 3 items -rw-r--r-- 1 cloudera supergroup 0 2012-08-12 15:38 /user/cloudera/HFstats/_SUCCESS drwxr-xr-x - cloudera supergroup 0 2012-08-12 15:37 /user/cloudera/HFstats/_logs -rw-r--r-- 1 cloudera ... 24 2012-08-12 15:37 /user/cloudera/HFstats/part-00000 $ hcat /user/cloudera/HFstats/part-00000 113365 4.11227 2.17086 # now for cooper $ hadoop jar /usr/lib/hadoop-0.20/contrib/streaming/hadoop-streaming-0.20.2-cdh3u4.jar \ -input DS.txt.gz -output DSstats -file ./mapper.py -file ./statsreducer.awk \ -mapper ./mapper.py -reducer ./statsreducer.awk $ hcat /user/cloudera/DSstats/part-00000 215107 4.56068 2.50734
Os fãs de Mark Twain podem relaxar sabendo que o Hadoop considera que Cooper usa palavras mais longas e com um desvio padrão chocante (com intenção de humor). Com isso, supõe-se que palavras mais curtas são melhores. Vamos continuar, e escrever os dados no HDFS para o Informix e o DB2.
Usando Sqoop para escrever dados do HDFS no Informix, DB2 ou MySQL via JDBC
O Sqoop Apache Project é um utilitário de software livre de movimentação de dados de Hadoop para banco de dados baseado em JDBC. Sqoop foi originalmente criado em um hackathon na Cloudera e disponibilizado como software livre.
A movimentação de dados do HDFS para um banco de dados relacional é um caso de uso comum. HDFS e Map-Reduce são ótimos para realizar o trabalho pesado. Para consultas mais simples ou um armazenamento backend para um website, o armazenamento em cache da saída do Map-Reduce em um armazenamento relacional é um bom padrão de design. É possível evitar a nova execução da contagem de palavra de Map-Reduce aplicando Sqoop nos resultados para o Informix e DB2. Você gerou dados sobre Twain e Cooper. Agora, vamos movê-los para um banco de dados, como mostra a Listagem 11.
#Sqoop needs access to the JDBC driver for every # database that it will access # please copy the driver for each database you plan to use for these exercises # the MySQL database and driver are already installed in the virtual image # but you still need to copy the driver to the sqoop/lib directory #one time copy of jdbc driver to sqoop lib directory $ sudo cp Informix_JDBC_Driver/lib/ifxjdbc*.jar /usr/lib/sqoop/lib/ $ sudo cp db2jdbc/db2jcc*.jar /usr/lib/sqoop/lib/ $ sudo cp /usr/lib/hive/lib/mysql-connector-java-5.1.15-bin.jar /usr/lib/sqoop/lib/
Os exemplos exibidos nas Listagens 12 a 15 são apresentados para cada banco de dados. Vá até o exemplo que o interessa, incluindo Informix, DB2 ou MySQL. Para os poliglotas em banco de dados, divirtam-se com os exemplos. Se o banco de dados de sua escolha não estiver incluído aqui, não será um grande desafio fazer essas amostras funcionarem em outro lugar.
# create a target table to put the data # fire up dbaccess and use this sql # create table wordcount ( word char(36) primary key, n int); # now run the sqoop command # this is best put in a shell script to help avoid typos... $ sqoop export -D sqoop.export.records.per.statement=1 \ --fields-terminated-by '\t' --driver com.informix.jdbc.IfxDriver \ --connect \ "jdbc:informix-sqli://myhost:54321/stores_demo:informixserver=i7;user=me;password=mypw" \ --table wordcount --export-dir /user/cloudera/HF.out
12/08/08 21:39:42 INFO manager.SqlManager: Using default fetchSize of 1000 12/08/08 21:39:42 INFO tool.CodeGenTool: Beginning code generation 12/08/08 21:39:43 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM wordcount AS t WHERE 1=0 12/08/08 21:39:43 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM wordcount AS t WHERE 1=0 12/08/08 21:39:43 INFO orm.CompilationManager: HADOOP_HOME is /usr/lib/hadoop 12/08/08 21:39:43 INFO orm.CompilationManager: Found hadoop core jar at: /usr/lib/hadoop/hadoop-0.20.2-cdh3u4-core.jar 12/08/08 21:39:45 INFO orm.CompilationManager: Writing jar file: /tmp/sqoop-cloudera/compile/248b77c05740f863a15e0136accf32cf/wordcount.jar 12/08/08 21:39:45 INFO mapreduce.ExportJobBase: Beginning export of wordcount 12/08/08 21:39:45 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM wordcount AS t WHERE 1=0 12/08/08 21:39:46 INFO input.FileInputFormat: Total input paths to process : 1 12/08/08 21:39:46 INFO input.FileInputFormat: Total input paths to process : 1 12/08/08 21:39:46 INFO mapred.JobClient: Running job: job_201208081900_0012 12/08/08 21:39:47 INFO mapred.JobClient: map 0% reduce 0% 12/08/08 21:39:58 INFO mapred.JobClient: map 38% reduce 0% 12/08/08 21:40:00 INFO mapred.JobClient: map 64% reduce 0% 12/08/08 21:40:04 INFO mapred.JobClient: map 82% reduce 0% 12/08/08 21:40:07 INFO mapred.JobClient: map 98% reduce 0% 12/08/08 21:40:09 INFO mapred.JobClient: Task Id : attempt_201208081900_0012_m_000000_0, Status : FAILED java.io.IOException: java.sql.SQLException: Encoding or code set not supported. at ...SqlRecordWriter.close(AsyncSqlRecordWriter.java:187) at ...$NewDirectOutputCollector.close(MapTask.java:540) at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:649) at org.apache.hadoop.mapred.MapTask.run(MapTask.java:323) at org.apache.hadoop.mapred.Child$4.run(Child.java:270) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:396) at ....doAs(UserGroupInformation.java:1177) at org.apache.hadoop.mapred.Child.main(Child.java:264) Caused by: java.sql.SQLException: Encoding or code set not supported. at com.informix.util.IfxErrMsg.getSQLException(IfxErrMsg.java:413) at com.informix.jdbc.IfxChar.toIfx(IfxChar.java:135) at com.informix.jdbc.IfxSqli.a(IfxSqli.java:1304) at com.informix.jdbc.IfxSqli.d(IfxSqli.java:1605) at com.informix.jdbc.IfxS 12/08/08 21:40:11 INFO mapred.JobClient: map 0% reduce 0% 12/08/08 21:40:15 INFO mapred.JobClient: Task Id : attempt_201208081900_0012_m_000000_1, Status : FAILED java.io.IOException: java.sql.SQLException: Unique constraint (informix.u169_821) violated. at .mapreduce.AsyncSqlRecordWriter.write(AsyncSqlRecordWriter.java:223) at .mapreduce.AsyncSqlRecordWriter.write(AsyncSqlRecordWriter.java:49) at .mapred.MapTask$NewDirectOutputCollector.write(MapTask.java:531) at .mapreduce.TaskInputOutputContext.write(TaskInputOutputContext.java:80) at com.cloudera.sqoop.mapreduce.TextExportMapper.map(TextExportMapper.java:82) at com.cloudera.sqoop.mapreduce.TextExportMapper.map(TextExportMapper.java:40) at org.apache.hadoop.mapreduce.Mapper.run(Mapper.java:144) at .mapreduce.AutoProgressMapper.run(AutoProgressMapper.java:189) at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:647) at org.apache.hadoop.mapred.MapTask.run(MapTask.java:323) at org.apache.hadoop.mapred.Child$4.run(Child.java:270) at java.security.AccessController.doPrivileged(Native Method) at javax.security.a 12/08/08 21:40:20 INFO mapred.JobClient: Task Id : attempt_201208081900_0012_m_000000_2, Status : FAILED java.sql.SQLException: Unique constraint (informix.u169_821) violated. at .mapreduce.AsyncSqlRecordWriter.write(AsyncSqlRecordWriter.java:223) at .mapreduce.AsyncSqlRecordWriter.write(AsyncSqlRecordWriter.java:49) at .mapred.MapTask$NewDirectOutputCollector.write(MapTask.java:531) at .mapreduce.TaskInputOutputContext.write(TaskInputOutputContext.java:80) at com.cloudera.sqoop.mapreduce.TextExportMapper.map(TextExportMapper.java:82) at com.cloudera.sqoop.mapreduce.TextExportMapper.map(TextExportMapper.java:40) at org.apache.hadoop.mapreduce.Mapper.run(Mapper.java:144) at .mapreduce.AutoProgressMapper.run(AutoProgressMapper.java:189) at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:647) at org.apache.hadoop.mapred.MapTask.run(MapTask.java:323) at org.apache.hadoop.mapred.Child$4.run(Child.java:270) at java.security.AccessController.doPrivileged(Native Method) at javax.security.a 12/08/08 21:40:27 INFO mapred.JobClient: Job complete: job_201208081900_0012 12/08/08 21:40:27 INFO mapred.JobClient: Counters: 7 12/08/08 21:40:27 INFO mapred.JobClient: Job Counters 12/08/08 21:40:27 INFO mapred.JobClient: SLOTS_MILLIS_MAPS=38479 12/08/08 21:40:27 INFO mapred.JobClient: Total time spent by all reduces waiting after reserving slots (ms)=0 12/08/08 21:40:27 INFO mapred.JobClient: Total time spent by all maps waiting after reserving slots (ms)=0 12/08/08 21:40:27 INFO mapred.JobClient: Launched map tasks=4 12/08/08 21:40:27 INFO mapred.JobClient: Data-local map tasks=4 12/08/08 21:40:27 INFO mapred.JobClient: SLOTS_MILLIS_REDUCES=0 12/08/08 21:40:27 INFO mapred.JobClient: Failed map tasks=1 12/08/08 21:40:27 INFO mapreduce.ExportJobBase: Transferred 0 bytes in 41.5758 seconds (0 bytes/sec) 12/08/08 21:40:27 INFO mapreduce.ExportJobBase: Exported 0 records. 12/08/08 21:40:27 ERROR tool.ExportTool: Error during export: Export job failed! # despite the errors above, rows are inserted into the wordcount table # one row is missing # the retry and duplicate key exception are most likely related, but # troubleshooting will be saved for a later article # check how we did # nothing like a "here document" shell script $ dbaccess stores_demo - <<eoj > select count(*) from wordcount; > eoj Database selected. (count(*)) 13837 1 row(s) retrieved. Database closed.
# here is the db2 syntax # create a destination table for db2 # #db2 => connect to sample # # Database Connection Information # # Database server = DB2/LINUXX8664 10.1.0 # SQL authorization ID = DB2INST1 # Local database alias = SAMPLE # #db2 => create table wordcount ( word char(36) not null primary key , n int) #DB20000I The SQL command completed successfully. # sqoop export -D sqoop.export.records.per.statement=1 \ --fields-terminated-by '\t' \ --driver com.ibm.db2.jcc.DB2Driver \ --connect "jdbc:db2://192.168.1.131:50001/sample" \ --username db2inst1 --password db2inst1 \ --table wordcount --export-dir /user/cloudera/HF.out 12/08/09 12:32:59 WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead. 12/08/09 12:32:59 INFO manager.SqlManager: Using default fetchSize of 1000 12/08/09 12:32:59 INFO tool.CodeGenTool: Beginning code generation 12/08/09 12:32:59 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM wordcount AS t WHERE 1=0 12/08/09 12:32:59 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM wordcount AS t WHERE 1=0 12/08/09 12:32:59 INFO orm.CompilationManager: HADOOP_HOME is /usr/lib/hadoop 12/08/09 12:32:59 INFO orm.CompilationManager: Found hadoop core jar at: /usr/lib/hadoop/hadoop-0.20.2-cdh3u4-core.jar 12/08/09 12:33:00 INFO orm.CompilationManager: Writing jar file: /tmp/sqoop-cloudera/compile/5532984df6e28e5a45884a21bab245ba/wordcount.jar 12/08/09 12:33:00 INFO mapreduce.ExportJobBase: Beginning export of wordcount 12/08/09 12:33:01 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM wordcount AS t WHERE 1=0 12/08/09 12:33:02 INFO input.FileInputFormat: Total input paths to process : 1 12/08/09 12:33:02 INFO input.FileInputFormat: Total input paths to process : 1 12/08/09 12:33:02 INFO mapred.JobClient: Running job: job_201208091208_0002 12/08/09 12:33:03 INFO mapred.JobClient: map 0% reduce 0% 12/08/09 12:33:14 INFO mapred.JobClient: map 24% reduce 0% 12/08/09 12:33:17 INFO mapred.JobClient: map 44% reduce 0% 12/08/09 12:33:20 INFO mapred.JobClient: map 67% reduce 0% 12/08/09 12:33:23 INFO mapred.JobClient: map 86% reduce 0% 12/08/09 12:33:24 INFO mapred.JobClient: map 100% reduce 0% 12/08/09 12:33:25 INFO mapred.JobClient: Job complete: job_201208091208_0002 12/08/09 12:33:25 INFO mapred.JobClient: Counters: 16 12/08/09 12:33:25 INFO mapred.JobClient: Job Counters 12/08/09 12:33:25 INFO mapred.JobClient: SLOTS_MILLIS_MAPS=21648 12/08/09 12:33:25 INFO mapred.JobClient: Total time spent by all reduces waiting after reserving slots (ms)=0 12/08/09 12:33:25 INFO mapred.JobClient: Total time spent by all maps waiting after reserving slots (ms)=0 12/08/09 12:33:25 INFO mapred.JobClient: Launched map tasks=1 12/08/09 12:33:25 INFO mapred.JobClient: Data-local map tasks=1 12/08/09 12:33:25 INFO mapred.JobClient: SLOTS_MILLIS_REDUCES=0 12/08/09 12:33:25 INFO mapred.JobClient: FileSystemCounters 12/08/09 12:33:25 INFO mapred.JobClient: HDFS_BYTES_READ=138350 12/08/09 12:33:25 INFO mapred.JobClient: FILE_BYTES_WRITTEN=69425 12/08/09 12:33:25 INFO mapred.JobClient: Map-Reduce Framework 12/08/09 12:33:25 INFO mapred.JobClient: Map input records=13838 12/08/09 12:33:25 INFO mapred.JobClient: Physical memory (bytes) snapshot=105148416 12/08/09 12:33:25 INFO mapred.JobClient: Spilled Records=0 12/08/09 12:33:25 INFO mapred.JobClient: CPU time spent (ms)=9250 12/08/09 12:33:25 INFO mapred.JobClient: Total committed heap usage (bytes)=42008576 12/08/09 12:33:25 INFO mapred.JobClient: Virtual memory (bytes) snapshot=596447232 12/08/09 12:33:25 INFO mapred.JobClient: Map output records=13838 12/08/09 12:33:25 INFO mapred.JobClient: SPLIT_RAW_BYTES=126 12/08/09 12:33:25 INFO mapreduce.ExportJobBase: Transferred 135.1074 KB in 24.4977 seconds (5.5151 KB/sec) 12/08/09 12:33:25 INFO mapreduce.ExportJobBase: Exported 13838 records. # check on the results... # #db2 => select count(*) from wordcount # #1 #----------- # 13838 # # 1 record(s) selected. # #
# if you don't have Informix or DB2 you can still do this example # mysql - it is already installed in the VM, here is how to access # one time copy of the JDBC driver sudo cp /usr/lib/hive/lib/mysql-connector-java-5.1.15-bin.jar /usr/lib/sqoop/lib/ # now create the database and table $ mysql -u root Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 45 Server version: 5.0.95 Source distribution Copyright (c) 2000, 2011, Oracle and/or its affiliates. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql> create database mydemo; Query OK, 1 row affected (0.00 sec) mysql> use mydemo Database changed mysql> create table wordcount ( word char(36) not null primary key, n int); Query OK, 0 rows affected (0.00 sec) mysql> exit Bye # now export $ sqoop export --connect jdbc:mysql://localhost/mydemo \ --table wordcount --export-dir /user/cloudera/HF.out \ --fields-terminated-by '\t' --username root
Importando dados para o HDFS do Informix e DB2 com Sqoop
A inserção de dados no Hadoop HDFS também pode ser realizada com o Sqoop. A funcionalidade bidirecional é controlada por meio do parâmetro import.
As amostras de banco de dados que acompanham ambos os produtos têm alguns conjuntos de dados simples que podem ser usados para essa finalidade. A Listagem 16 mostra a sintaxe e os resultados do uso do Sqoop em cada servidor.
Para usuários de MySQL, adapte a sintaxe a partir dos exemplos de Informix ou DB2 a seguir.
$ sqoop import --driver com.informix.jdbc.IfxDriver \ --connect \ "jdbc:informix-sqli://192.168.1.143:54321/stores_demo:informixserver=ifx117" \ --table orders \ --username informix --password useyours 12/08/09 14:39:18 WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead. 12/08/09 14:39:18 INFO manager.SqlManager: Using default fetchSize of 1000 12/08/09 14:39:18 INFO tool.CodeGenTool: Beginning code generation 12/08/09 14:39:19 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM orders AS t WHERE 1=0 12/08/09 14:39:19 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM orders AS t WHERE 1=0 12/08/09 14:39:19 INFO orm.CompilationManager: HADOOP_HOME is /usr/lib/hadoop 12/08/09 14:39:19 INFO orm.CompilationManager: Found hadoop core jar at: /usr/lib/hadoop/hadoop-0.20.2-cdh3u4-core.jar 12/08/09 14:39:21 INFO orm.CompilationManager: Writing jar file: /tmp/sqoop-cloudera/compile/0b59eec7007d3cff1fc0ae446ced3637/orders.jar 12/08/09 14:39:21 INFO mapreduce.ImportJobBase: Beginning import of orders 12/08/09 14:39:21 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM orders AS t WHERE 1=0 12/08/09 14:39:22 INFO db.DataDrivenDBInputFormat: BoundingValsQuery: SELECT MIN(order_num), MAX(order_num) FROM orders 12/08/09 14:39:22 INFO mapred.JobClient: Running job: job_201208091208_0003 12/08/09 14:39:23 INFO mapred.JobClient: map 0% reduce 0% 12/08/09 14:39:31 INFO mapred.JobClient: map 25% reduce 0% 12/08/09 14:39:32 INFO mapred.JobClient: map 50% reduce 0% 12/08/09 14:39:36 INFO mapred.JobClient: map 100% reduce 0% 12/08/09 14:39:37 INFO mapred.JobClient: Job complete: job_201208091208_0003 12/08/09 14:39:37 INFO mapred.JobClient: Counters: 16 12/08/09 14:39:37 INFO mapred.JobClient: Job Counters 12/08/09 14:39:37 INFO mapred.JobClient: SLOTS_MILLIS_MAPS=22529 12/08/09 14:39:37 INFO mapred.JobClient: Total time spent by all reduces waiting after reserving slots (ms)=0 12/08/09 14:39:37 INFO mapred.JobClient: Total time spent by all maps waiting after reserving slots (ms)=0 12/08/09 14:39:37 INFO mapred.JobClient: Launched map tasks=4 12/08/09 14:39:37 INFO mapred.JobClient: SLOTS_MILLIS_REDUCES=0 12/08/09 14:39:37 INFO mapred.JobClient: FileSystemCounters 12/08/09 14:39:37 INFO mapred.JobClient: HDFS_BYTES_READ=457 12/08/09 14:39:37 INFO mapred.JobClient: FILE_BYTES_WRITTEN=278928 12/08/09 14:39:37 INFO mapred.JobClient: HDFS_BYTES_WRITTEN=2368 12/08/09 14:39:37 INFO mapred.JobClient: Map-Reduce Framework 12/08/09 14:39:37 INFO mapred.JobClient: Map input records=23 12/08/09 14:39:37 INFO mapred.JobClient: Physical memory (bytes) snapshot=291364864 12/08/09 14:39:37 INFO mapred.JobClient: Spilled Records=0 12/08/09 14:39:37 INFO mapred.JobClient: CPU time spent (ms)=1610 12/08/09 14:39:37 INFO mapred.JobClient: Total committed heap usage (bytes)=168034304 12/08/09 14:39:37 INFO mapred.JobClient: Virtual memory (bytes) snapshot=2074587136 12/08/09 14:39:37 INFO mapred.JobClient: Map output records=23 12/08/09 14:39:37 INFO mapred.JobClient: SPLIT_RAW_BYTES=457 12/08/09 14:39:37 INFO mapreduce.ImportJobBase: Transferred 2.3125 KB in 16.7045 seconds (141.7585 bytes/sec) 12/08/09 14:39:37 INFO mapreduce.ImportJobBase: Retrieved 23 records. # now look at the results $ hls Found 4 items -rw-r--r-- 1 cloudera supergroup 459386 2012-08-08 19:34 /user/cloudera/DS.txt.gz drwxr-xr-x - cloudera supergroup 0 2012-08-08 19:38 /user/cloudera/HF.out -rw-r--r-- 1 cloudera supergroup 597587 2012-08-08 19:35 /user/cloudera/HF.txt drwxr-xr-x - cloudera supergroup 0 2012-08-09 14:39 /user/cloudera/orders $ hls orders Found 6 items -rw-r--r-- 1 cloudera supergroup 0 2012-08-09 14:39 /user/cloudera/orders/_SUCCESS drwxr-xr-x - cloudera supergroup 0 2012-08-09 14:39 /user/cloudera/orders/_logs -rw-r--r-- 1 cloudera ...roup 630 2012-08-09 14:39 /user/cloudera/orders/part-m-00000 -rw-r--r-- 1 cloudera supergroup 564 2012-08-09 14:39 /user/cloudera/orders/part-m-00001 -rw-r--r-- 1 cloudera supergroup 527 2012-08-09 14:39 /user/cloudera/orders/part-m-00002 -rw-r--r-- 1 cloudera supergroup 647 2012-08-09 14:39 /user/cloudera/orders/part-m-00003 # wow there are four files part-m-0000x # look inside one # some of the lines are edited to fit on the screen $ hcat /user/cloudera/orders/part-m-00002 1013,2008-06-22,104,express ,n,B77930 ,2008-07-10,60.80,12.20,2008-07-31 1014,2008-06-25,106,ring bell, ,n,8052 ,2008-07-03,40.60,12.30,2008-07-10 1015,2008-06-27,110, ,n,MA003 ,2008-07-16,20.60,6.30,2008-08-31 1016,2008-06-29,119, St. ,n,PC6782 ,2008-07-12,35.00,11.80,null 1017,2008-07-09,120,use ,n,DM354331 ,2008-07-13,60.00,18.00,null
Por que há quatro arquivos diferentes contendo apenas parte dos dados? Sqoop é um utilitário altamente paralelizado. Se um cluster com 4000 nós executando Sqoop realizar uma importação total de um banco de dados, as 4000 conexões pareceriam muito com um ataque de negação de serviço contra o banco de dados. O limite de conexão padrão do Sqoop é de quatro conexões JDBC. Cada conexão gera um arquivo de dados em HDFS. Por isso os quatro arquivos. Não se preocupe, pois você verá como o Hadoop trabalha nesses arquivos sem qualquer dificuldade.
A próxima etapa é importar uma tabela DB2. Como mostra a Listagem 17, especificando a opção -m 1 , é possível importar uma tabela sem uma chave primária, e o resultado será um arquivo único.
# very much the same as above, just a different jdbc connection # and different table name sqoop import --driver com.ibm.db2.jcc.DB2Driver \ --connect "jdbc:db2://192.168.1.131:50001/sample" \ --table staff --username db2inst1 \ --password db2inst1 -m 1 # Here is another example # in this case set the sqoop default schema to be different from # the user login schema sqoop import --driver com.ibm.db2.jcc.DB2Driver \ --connect "jdbc:db2://192.168.1.3:50001/sample:currentSchema=DB2INST1;" \ --table helloworld \ --target-dir "/user/cloudera/sqoopin2" \ --username marty \ -P -m 1 # the the schema name is CASE SENSITIVE # the -P option prompts for a password that will not be visible in # a "ps" listing
Usando Hive: unindo dados do Informix e do DB2
Há um caso de uso interessante para unir dados do Informix para DB2. Não é muito empolgante para duas tabelas comuns, mas uma enorme vitória para diversos terabytes ou petabytes de dados.
Há duas abordagens fundamentais para a união de fontes de dados diferentes. Não mexer com os dados e usar a tecnologia de federação versus mover os dados para um único armazenamento a fim de executar a união. A economia e o desempenho do Hadoop fazem com que a movimentação dos dados para HDFS e o desempenho do trabalho pesado com MapReduce sejam uma opção fácil. Os limites de largura de banda de rede criam uma barreira fundamental se você tentar unir os dados com uma tecnologia no estilo federação. Para obter mais informações sobre federação, consulte a seção Recursos .
O Hive fornece um subconjunto de SQL para operação em um cluster. Não fornece semânticas de transação. Não é uma substituição para Informix ou DB2. Se você tiver algum trabalho pesado na forma de uniões de tabela, mesmo se tiver tabelas menores, mas precisar de produtos cartesianos complicados, Hadoop será a ferramenta escolhida.
Para usar a linguagem de consulta Hive, um subconjunto de SQL chamado metadados de tabela Hiveql é necessário. É possível definir os metadados com base em arquivos existentes em HDFS. O Sqoop fornece um atalho conveniente com a opção create-hive-table.
Os usuários de MySQL devem se sentir livres para adaptar os exemplos exibidos na Listagem 18. Um exercício interessante seria unir MySQL, ou quaisquer outras tabelas de banco de dados relacional, a planilhas grandes.
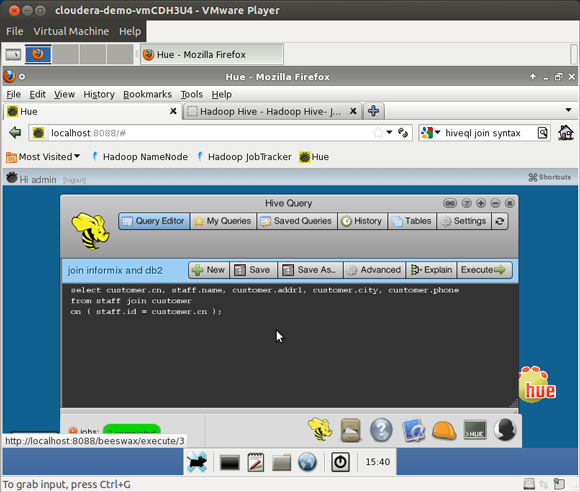
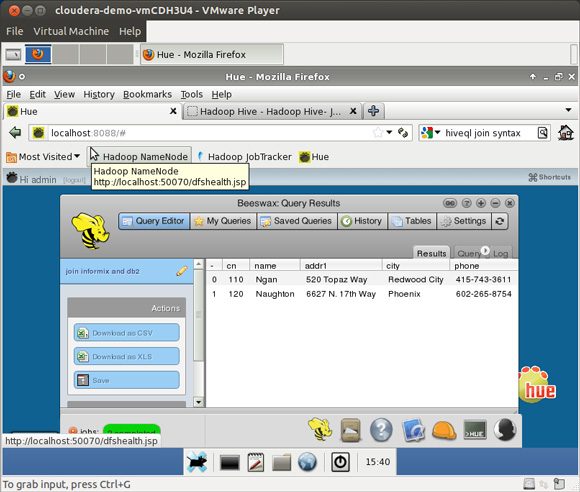
# import the customer table into Hive $ sqoop import --driver com.informix.jdbc.IfxDriver \ --connect \ "jdbc:informix-sqli://myhost:54321/stores_demo:informixserver=ifx;user=me;password=you" \ --table customer # now tell hive where to find the informix data # to get to the hive command prompt just type in hive $ hive Hive history file=/tmp/cloudera/yada_yada_log123.txt hive> # here is the hiveql you need to create the tables # using a file is easier than typing create external table customer ( cn int, fname string, lname string, company string, addr1 string, addr2 string, city string, state string, zip string, phone string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' LOCATION '/user/cloudera/customer' ; # we already imported the db2 staff table above # now tell hive where to find the db2 data create external table staff ( id int, name string, dept string, job string, years string, salary float, comm float) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' LOCATION '/user/cloudera/staff' ; # you can put the commands in a file # and execute them as follows: $ hive -f hivestaff Hive history file=/tmp/cloudera/hive_job_log_cloudera_201208101502_2140728119.txt OK Time taken: 3.247 seconds OK 10 Sanders 20 Mgr 7 98357.5 NULL 20 Pernal 20 Sales 8 78171.25 612.45 30 Marenghi 38 Mgr 5 77506.75 NULL 40 O'Brien 38 Sales 6 78006.0 846.55 50 Hanes 15 Mgr 10 80 ... lines deleted # now for the join we've all been waiting for :-) # this is a simple case, Hadoop can scale well into the petabyte range! $ hive Hive history file=/tmp/cloudera/hive_job_log_cloudera_201208101548_497937669.txt hive> select customer.cn, staff.name, > customer.addr1, customer.city, customer.phone > from staff join customer > on ( staff.id = customer.cn ); Total MapReduce jobs = 1 Launching Job 1 out of 1 Number of reduce tasks not specified. Estimated from input data size: 1 In order to change the average load for a reducer (in bytes): set hive.exec.reducers.bytes.per.reducer=number In order to limit the maximum number of reducers: set hive.exec.reducers.max=number In order to set a constant number of reducers: set mapred.reduce.tasks=number Starting Job = job_201208101425_0005, Tracking URL = http://0.0.0.0:50030/jobdetails.jsp?jobid=job_201208101425_0005 Kill Command = /usr/lib/hadoop/bin/hadoop job -Dmapred.job.tracker=0.0.0.0:8021 -kill job_201208101425_0005 2012-08-10 15:49:07,538 Stage-1 map = 0%, reduce = 0% 2012-08-10 15:49:11,569 Stage-1 map = 50%, reduce = 0% 2012-08-10 15:49:12,574 Stage-1 map = 100%, reduce = 0% 2012-08-10 15:49:19,686 Stage-1 map = 100%, reduce = 33% 2012-08-10 15:49:20,692 Stage-1 map = 100%, reduce = 100% Ended Job = job_201208101425_0005 OK 110 Ngan 520 Topaz Way Redwood City 415-743-3611 120 Naughton 6627 N. 17th Way Phoenix 602-265-8754 Time taken: 22.764 seconds
É muito melhor quando você usa o Hue para uma interface de navegador gráfica, como mostra as Figuras 9, 10 e 11.
Usando Pig: unindo dados do Informix e do DB2
Pig é uma linguagem processual. Assim como Hive, nos bastidores ele gera um código MapReduce. A facilidade de uso do Hadoop continuará a melhorar assim que mais projetos ficarem disponíveis. Por mais que muitos de nós realmente gostem da linha de comando, há diversas interfaces gráficas que funcionam muito bem com o Hadoop.
A Listagem 19 mostra o código de Pig usado para unir a tabela customer e a tabela staff do exemplo anterior.
$ pig
grunt> staffdb2 = load 'staff' using PigStorage(',')
>> as ( id, name, dept, job, years, salary, comm );
grunt> custifx2 = load 'customer' using PigStorage(',') as
>> (cn, fname, lname, company, addr1, addr2, city, state, zip, phone)
>> ;
grunt> joined = join custifx2 by cn, staffdb2 by id;
# to make pig generate a result set use the dump command
# no work has happened up till now
grunt> dump joined;
2012-08-11 21:24:51,848 [main] INFO org.apache.pig.tools.pigstats.ScriptState
- Pig features used in the script: HASH_JOIN
2012-08-11 21:24:51,848 [main] INFO org.apache.pig.backend.hadoop.executionengine
.HExecutionEngine - pig.usenewlogicalplan is set to true.
New logical plan will be used.
HadoopVersion PigVersion UserId StartedAt FinishedAt Features
0.20.2-cdh3u4 0.8.1-cdh3u4 cloudera 2012-08-11 21:24:51
2012-08-11 21:25:19 HASH_JOIN
Success!
Job Stats (time in seconds):
JobId Maps Reduces MaxMapTime MinMapTIme AvgMapTime
MaxReduceTime MinReduceTime AvgReduceTime Alias Feature Outputs
job_201208111415_0006 2 1 8 8 8 10 10 10
custifx,joined,staffdb2 HASH_JOIN hdfs://0.0.0.0/tmp/temp1785920264/tmp-388629360,
Input(s):
Successfully read 35 records from: "hdfs://0.0.0.0/user/cloudera/staff"
Successfully read 28 records from: "hdfs://0.0.0.0/user/cloudera/customer"
Output(s):
Successfully stored 2 records (377 bytes) in:
"hdfs://0.0.0.0/tmp/temp1785920264/tmp-388629360"
Counters:
Total records written : 2
Total bytes written : 377
Spillable Memory Manager spill count : 0
Total bags proactively spilled: 0
Total records proactively spilled: 0
Job DAG:
job_201208111415_0006
2012-08-11 21:25:19,145 [main] INFO
org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - Success!
2012-08-11 21:25:19,149 [main] INFO org.apache.hadoop.mapreduce.lib.
input.FileInputFormat - Total input paths to process : 1
2012-08-11 21:25:19,149 [main] INFO org.apache.pig.backend.hadoop.
executionengine.util.MapRedUtil - Total input paths to process : 1
(110,Roy ,Jaeger ,AA Athletics ,520 Topaz Way
,null,Redwood City ,CA,94062,415-743-3611 ,110,Ngan,15,Clerk,5,42508.20,206.60)
(120,Fred ,Jewell ,Century Pro Shop ,6627 N. 17th Way
,null,Phoenix ,AZ,85016,602-265-8754
,120,Naughton,38,Clerk,null,42954.75,180.00)
Como eu escolho Java, Hive ou Pig?
Você tem diversas opções para programar Hadoop, e é melhor analisar o caso de uso para escolher a ferramenta certa para a tarefa. Você não fica limitado a trabalhar nos dados relacionais, mas este artigo se concentra na união estável do Informix, DB2, e Hadoop. Escrever centenas de linhas em Java para implementar uma junção de hash no estilo relacional é uma perda completa de tempo uma vez que esse algoritmo Hadoop MapReduce já está disponível. Como você escolhe? Isso é uma questão de preferência pessoal. Algumas pessoas gostam de codificar operações de configuração em SQL. Outros preferem o código processual. Escolha a linguagem com a qual você é mais produtivo. Se você tiver diversos sistemas relacionais e quiser combinar todos os dados com ótimo desempenho por um preço baixo, Hadoop, MapReduce, Hive e Pig estarão prontos para ajudar.
Não exclua seus dados: transferindo uma partição do Informix para o HDFS
A maioria dos bancos de dados relacionais modernos pode particionar dados. Um caso de uso comum é particionar por período de tempo. Uma janela fixa de dados é armazenada, por exemplo, um intervalo corrente de 18 meses, após o qual os dados são arquivados. O recurso detach-partition é muito eficiente. Mas após a partição ser desanexada o que a pessoa faz com os dados?
A compactação por tar de dados antigos é uma forma muito cara de descartar os bytes antigos. Depois de mover para um meio menos acessível, raramente os dados são acessados a menos que haja um requisito de auditoria legal. O Hadoop fornece uma alternativa muito melhor.
Mover os bytes em arquivo da partição antiga para o Hadoop fornece acesso de alto desempenho com custo muito inferior do que manter os dados no sistema transacional original ou conjunto/armazém de dados. Os dados são muito antigos para terem valor transacional, mas ainda são muito valiosos para a organização para análise de longo prazo. Os exemplos de Sqoop exibidos anteriormente fornecem as noções básicas para mover esses dados de uma partição relacional para HDFS.
Fuse – acessando seus arquivos do HDFS por meio de NFS
Os dados do Informix/DB2/arquivo simples no HDFS podem ser acessado por meio de NFS, como mostra a Listagem 20. Isso fornece operações de linha de comando sem o uso da interface “hadoop fs -yadayada”. A partir de uma perspectiva de caso de uso de tecnologia, NFS é muito limitado em um ambiente de Big Data, mas os exemplos são incluídos para desenvolvedores e outros nem tão big data.
# this is for CDH4, the CDH3 image doesn't have fuse installed... $ mkdir fusemnt $ sudo hadoop-fuse-dfs dfs://localhost:8020 fusemnt/ INFO fuse_options.c:162 Adding FUSE arg fusemnt/ $ ls fusemnt tmp user var $ ls fusemnt/user cloudera hive $ ls fusemnt/user/cloudera customer DS.txt.gz HF.out HF.txt orders staff $ cat fusemnt/user/cloudera/orders/part-m-00001 1007,2008-05-31,117,null,n,278693 ,2008-06-05,125.90,25.20,null 1008,2008-06-07,110,closed Monday ,y,LZ230 ,2008-07-06,45.60,13.80,2008-07-21 1009,2008-06-14,111,next door to grocery ,n,4745 ,2008-06-21,20.40,10.00,2008-08-21 1010,2008-06-17,115,deliver 776 King St. if no answer ,n,429Q ,2008-06-29,40.60,12.30,2008-08-22 1011,2008-06-18,104,express ,n,B77897 ,2008-07-03,10.40,5.00,2008-08-29 1012,2008-06-18,117,null,n,278701 ,2008-06-29,70.80,14.20,null
Flume – crie um arquivo com carregamento pronto
Flume next generation, ou flume-ng, é um carregador paralelo de alta velocidade. Os bancos de dados têm carregadores de alta velocidade, então como eles funcionam bem juntos? O caso de uso relacional para Flume-ng é a criação de um arquivo de carregamento pronto, local ou remotamente, portanto um servidor relacional pode usar seu carregador de alta velocidade. Sim, essa funcionalidade sobrepõe o Sqoop, mas o script exibido na Listagem 21 foi criado na solicitação de um cliente especificamente para esse estilo de carga de banco de dados.
$ sudo yum install flume-ng
$ cat flumeconf/hdfs2dbloadfile.conf
#
# started with example from flume-ng documentation
# modified to do hdfs source to file sink
#
# Define a memory channel called ch1 on agent1
agent1.channels.ch1.type = memory
# Define an exec source called exec-source1 on agent1 and tell it
# to bind to 0.0.0.0:31313. Connect it to channel ch1.
agent1.sources.exec-source1.channels = ch1
agent1.sources.exec-source1.type = exec
agent1.sources.exec-source1.command =hadoop fs -cat /user/cloudera/orders/part-m-00001
# this also works for all the files in the hdfs directory
# agent1.sources.exec-source1.command =hadoop fs
# -cat /user/cloudera/tsortin/*
agent1.sources.exec-source1.bind = 0.0.0.0
agent1.sources.exec-source1.port = 31313
# Define a logger sink that simply file rolls
# and connect it to the other end of the same channel.
agent1.sinks.fileroll-sink1.channel = ch1
agent1.sinks.fileroll-sink1.type = FILE_ROLL
agent1.sinks.fileroll-sink1.sink.directory =/tmp
# Finally, now that we've defined all of our components, tell
# agent1 which ones we want to activate.
agent1.channels = ch1
agent1.sources = exec-source1
agent1.sinks = fileroll-sink1
# now time to run the script
$ flume-ng agent --conf ./flumeconf/ -f ./flumeconf/hdfs2dbloadfile.conf -n
agent1
# here is the output file
# don't forget to stop flume - it will keep polling by default and generate
# more files
$ cat /tmp/1344780561160-1
1007,2008-05-31,117,null,n,278693 ,2008-06-05,125.90,25.20,null
1008,2008-06-07,110,closed Monday ,y,LZ230 ,2008-07-06,45.60,13.80,2008-07-21
1009,2008-06-14,111,next door to ,n,4745 ,2008-06-21,20.40,10.00,2008-08-21
1010,2008-06-17,115,deliver 776 King St. if no answer ,n,429Q
,2008-06-29,40.60,12.30,2008-08-22
1011,2008-06-18,104,express ,n,B77897 ,2008-07-03,10.40,5.00,2008-08-29
1012,2008-06-18,117,null,n,278701 ,2008-06-29,70.80,14.20,null
# jump over to dbaccess and use the greatest
# data loader in informix: the external table
# external tables were actually developed for
# informix XPS back in the 1996 timeframe
# and are now available in may servers
#
drop table eorders;
create external table eorders
(on char(10),
mydate char(18),
foo char(18),
bar char(18),
f4 char(18),
f5 char(18),
f6 char(18),
f7 char(18),
f8 char(18),
f9 char(18)
)
using (datafiles ("disk:/tmp/myfoo" ) , delimiter ",");
select * from eorders;
Oozie – adicionando o fluxo de trabalho para diversos trabalhos
O Oozie encadeará várias tarefas do Hadoop. Há um belo conjunto de exemplos incluídos com o oozie e usados no conjunto de códigos exibido na Listagem 22.
# This sample is for CDH3
# untar the examples
# CDH4
$ tar -zxvf /usr/share/doc/oozie-3.1.3+154/oozie-examples.tar.gz
# CDH3
$ tar -zxvf /usr/share/doc/oozie-2.3.2+27.19/oozie-examples.tar.gz
# cd to the directory where the examples live
# you MUST put these jobs into the hdfs store to run them
$ hadoop fs -put examples examples
# start up the oozie server - you need to be the oozie user
# since the oozie user is a non-login id use the following su trick
# CDH4
$ sudo su - oozie -s /usr/lib/oozie/bin/oozie-sys.sh start
# CDH3
$ sudo su - oozie -s /usr/lib/oozie/bin/oozie-start.sh
# checkthe status
oozie admin -oozie http://localhost:11000/oozie -status
System mode: NORMAL
# some jar housekeeping so oozie can find what it needs
$ cp /usr/lib/sqoop/sqoop-1.3.0-cdh3u4.jar examples/apps/sqoop/lib/
$ cp /home/cloudera/Informix_JDBC_Driver/lib/ifxjdbc.jar examples/apps/sqoop/lib/
$ cp /home/cloudera/Informix_JDBC_Driver/lib/ifxjdbcx.jar examples/apps/sqoop/lib/
# edit the workflow.xml file to use your relational database:
#################################
import
--driver com.informix.jdbc.IfxDriver
--connect jdbc:informix-sqli://192.168.1.143:54321/stores_demo:informixserver=ifx117
--table orders --username informix --password useyours
--target-dir /user/${wf:user()}/${examplesRoot}/output-data/sqoop --verbose
#################################
# from the directory where you un-tarred the examples file do the following:
$ hrmr examples;hput examples examples
# now you can run your sqoop job by submitting it to oozie
$ oozie job -oozie http://localhost:11000/oozie -config \
examples/apps/sqoop/job.properties -run
job: 0000000-120812115858174-oozie-oozi-W
# get the job status from the oozie server
$ oozie job -oozie http://localhost:11000/oozie -info 0000000-120812115858174-oozie-oozi-W
Job ID : 0000000-120812115858174-oozie-oozi-W
-----------------------------------------------------------------------
Workflow Name : sqoop-wf
App Path : hdfs://localhost:8020/user/cloudera/examples/apps/sqoop/workflow.xml
Status : SUCCEEDED
Run : 0
User : cloudera
Group : users
Created : 2012-08-12 16:05
Started : 2012-08-12 16:05
Last Modified : 2012-08-12 16:05
Ended : 2012-08-12 16:05
Actions
----------------------------------------------------------------------
ID Status Ext ID Ext Status Err Code
---------------------------------------------------------------------
0000000-120812115858174-oozie-oozi-W@sqoop-node OK
job_201208120930_0005 SUCCEEDED -
--------------------------------------------------------------------
# how to kill a job may come in useful at some point
oozie job -oozie http://localhost:11000/oozie -kill
0000013-120812115858174-oozie-oozi-W
# job output will be in the file tree
$ hcat /user/cloudera/examples/output-data/sqoop/part-m-00003
1018,2008-07-10,121,SW corner of Biltmore Mall ,n,S22942
,2008-07-13,70.50,20.00,2008-08-06
1019,2008-07-11,122,closed till noon Mondays ,n,Z55709
,2008-07-16,90.00,23.00,2008-08-06
1020,2008-07-11,123,express ,n,W2286
,2008-07-16,14.00,8.50,2008-09-20
1021,2008-07-23,124,ask for Elaine ,n,C3288
,2008-07-25,40.00,12.00,2008-08-22
1022,2008-07-24,126,express ,n,W9925
,2008-07-30,15.00,13.00,2008-09-02
1023,2008-07-24,127,no deliveries after 3 p.m. ,n,KF2961
,2008-07-30,60.00,18.00,2008-08-22
# if you run into this error there is a good chance that your
# database lock file is owned by root
$ oozie job -oozie http://localhost:11000/oozie -config \
examples/apps/sqoop/job.properties -run
Error: E0607 : E0607: Other error in operation [ org.apache.openjpa.persistence.RollbackException:
The transaction has been rolled back. See the nested exceptions for
details on the errors that occurred.], {1}
# fix this as follows
$ sudo chown oozie:oozie /var/lib/oozie/oozie-db/db.lck
# and restart the oozie server
$ sudo su - oozie -s /usr/lib/oozie/bin/oozie-stop.sh
$ sudo su - oozie -s /usr/lib/oozie/bin/oozie-start.sh
HBase, um armazenamento de valor de chave de alto desempenho
HBase é um armazenamento de valor de chave de alto desempenho. Se seu caso de uso exigir escalabilidade e exigir apenas o equivalente de banco de dados de transações de confirmação automática, o HBase poderá ser a tecnologia a ser usada. HBase não é um banco de dados. O nome é infeliz uma vez que para alguns o termo base implique banco de dados. Ele realiza um trabalho excelente para armazenamentos de valor de chave de alto desempenho. Há alguma sobreposição entre a funcionalidade do HBase, Informix, DB2 e outros bancos de dados relacionais. Para transações ACID, conformidade total com SQL e diversos índices, um banco de dados relacional tradicional é a escolha óbvia.
Este último exercício de codificação serve para fornecer uma familiaridade básica com HBASE. Ele é simples por padrão e de maneira alguma representa o escopo da funcionalidade do HBase. Use este exemplo para entender alguns dos recursos básicos no HBase. “HBase, The Definitive Guide”, por Lars George, é uma leitura obrigatória se você planeja implementar ou rejeitar HBase para seu caso de uso específico.
Este último exemplo, exibido nas Listagens 23 e 24, usa a interface REST fornecido com HBase para inserir valores de chave em uma tabela HBase. A rotina de teste tem base em curl.
# enter the command line shell for hbase
$ hbase shell
HBase Shell; enter 'help for list of supported commands.
Type "exit to leave the HBase Shell
Version 0.90.6-cdh3u4, r, Mon May 7 13:14:00 PDT 2012
# create a table with a single column family
hbase(main):001:0> create 'mytable', 'mycolfamily'
# if you get errors from hbase you need to fix the
# network config
# here is a sample of the error:
ERROR: org.apache.hadoop.hbase.ZooKeeperConnectionException: HBase
is able to connect to ZooKeeper but the connection closes immediately.
This could be a sign that the server has too many connections
(30 is the default). Consider inspecting your ZK server logs for
that error and then make sure you are reusing HBaseConfiguration
as often as you can. See HTable's javadoc for more information.
# fix networking:
# add the eth0 interface to /etc/hosts with a hostname
$ sudo su -
# ifconfig | grep addr
eth0 Link encap:Ethernet HWaddr 00:0C:29:8C:C7:70
inet addr:192.168.1.134 Bcast:192.168.1.255 Mask:255.255.255.0
Interrupt:177 Base address:0x1400
inet addr:127.0.0.1 Mask:255.0.0.0
[root@myhost ~]# hostname myhost
[root@myhost ~]# echo "192.168.1.134 myhost" >gt; /etc/hosts
[root@myhost ~]# cd /etc/init.d
# now that the host and address are defined restart Hadoop
[root@myhost init.d]# for i in hadoop*
> do
> ./$i restart
> done
# now try table create again:
$ hbase shell
HBase Shell; enter 'help for list of supported commands.
Type "exit to leave the HBase Shell
Version 0.90.6-cdh3u4, r, Mon May 7 13:14:00 PDT 2012
hbase(main):001:0> create 'mytable' , 'mycolfamily'
0 row(s) in 1.0920 seconds
hbase(main):002:0>
# insert a row into the table you created
# use some simple telephone call log data
# Notice that mycolfamily can have multiple cells
# this is very troubling for DBAs at first, but
# you do get used to it
hbase(main):001:0> put 'mytable', 'key123', 'mycolfamily:number','6175551212'
0 row(s) in 0.5180 seconds
hbase(main):002:0> put 'mytable', 'key123', 'mycolfamily:duration','25'
# now describe and then scan the table
hbase(main):005:0> describe 'mytable'
DESCRIPTION ENABLED
{NAME => 'mytable', FAMILIES => [{NAME => 'mycolfam true
ily', BLOOMFILTER => 'NONE', REPLICATION_SCOPE => '
0', COMPRESSION => 'NONE', VERSIONS => '3', TTL =>
'2147483647', BLOCKSIZE => '65536', IN_MEMORY => 'f
alse', BLOCKCACHE => 'true'}]}
1 row(s) in 0.2250 seconds
# notice that timestamps are included
hbase(main):007:0> scan 'mytable'
ROW COLUMN+CELL
key123 column=mycolfamily:duration,
timestamp=1346868499125, value=25
key123 column=mycolfamily:number,
timestamp=1346868540850, value=6175551212
1 row(s) in 0.0250 seconds
# HBase includes a REST server
$ hbase rest start -p 9393 &
# you get a bunch of messages....
# get the status of the HBase server
$ curl http://localhost:9393/status/cluster
# lots of output...
# many lines deleted...
mytable,,1346866763530.a00f443084f21c0eea4a075bbfdfc292.
stores=1
storefiless=0
storefileSizeMB=0
memstoreSizeMB=0
storefileIndexSizeMB=0
# now scan the contents of mytable
$ curl http://localhost:9393/mytable/*
# lines deleted
12/09/05 15:08:49 DEBUG client.HTable$ClientScanner:
Finished with scanning at REGION =>
# lines deleted
MjU=
NjE3NTU1MTIxMg==
NjE3NTU1MTIxMg==
# the values from the REST interface are base64 encoded
$ echo a2V5MTIz | base64 -d
key123
$ echo bXljb2xmYW1pbHk6bnVtYmVy | base64 -d
mycolfamily:number
# The table scan above gives the schema needed to insert into the HBase table
$ echo RESTinsertedKey | base64
UkVTVGluc2VydGVkS2V5Cg==
$ echo 7815551212 | base64
NzgxNTU1MTIxMgo=
# add a table entry with a key value of "RESTinsertedKey" and
# a phone number of "7815551212"
# note - curl is all on one line
$ curl -H "Content-Type: text/xml" -d '
NzgxNTU1MTIxMgo=
http://192.168.1.134:9393/mytable/dummykey
12/09/05 15:52:34 DEBUG rest.RowResource: POST http://192.168.1.134:9393/mytable/dummykey
12/09/05 15:52:34 DEBUG rest.RowResource: PUT row=RESTinsertedKey\x0A,
families={(family=mycolfamily,
keyvalues=(RESTinsertedKey\x0A/mycolfamily:number/9223372036854775807/Put/vlen=11)}
# trust, but verify
hbase(main):002:0> scan 'mytable'
ROW COLUMN+CELL
RESTinsertedKey\x0A column=mycolfamily:number,timestamp=1346874754883,value=7815551212\x0A
key123 column=mycolfamily:duration, timestamp=1346868499125, value=25
key123 column=mycolfamily:number, timestamp=1346868540850, value=6175551212
2 row(s) in 0.5610 seconds
# notice the \x0A at the end of the key and value
# this is the newline generated by the "echo" command
# lets fix that
$ printf 8885551212 | base64
ODg4NTU1MTIxMg==
$ printf mykey | base64
bXlrZXk=
# note - curl statement is all on one line!
curl -H "Content-Type: text/xml" -d '
ODg4NTU1MTIxMg==
http://192.168.1.134:9393/mytable/dummykey
# trust but verify
hbase(main):001:0> scan 'mytable'
ROW COLUMN+CELL
RESTinsertedKey\x0A column=mycolfamily:number,timestamp=1346875811168,value=7815551212\x0A
key123 column=mycolfamily:duration, timestamp=1346868499125, value=25
key123 column=mycolfamily:number, timestamp=1346868540850, value=6175551212
mykey column=mycolfamily:number, timestamp=1346877875638, value=8885551212
3 row(s) in 0.6100 seconds
Conclusão
Uau, você conseguiu chegar até o final, parabéns! Isso é apenas o começo para entender Hadoop e como ele interage com Informix e DB2. Veja algumas sugestões para suas próximas etapas.
- Use os exemplos exibidos anteriormente e os adapte aos seus servidores. Convém usar dados pequenos, uma vez que não há muito espaço na imagem virtual.
- Obtenha uma certificação como Administrador Hadoop. Visite o website da Cloudera para obter informações sobre cursos e testes.
- Seja certificado como um Desenvolvedor Hadoop.
- Inicie um cluster usando a edição gratuita do Cloudera Manager.
- Comece a usar o IBM Big Sheets sobre CDH4.
Recursos
Aprender
- Use um Alimentação RSS para solicitar notificação sobre os artigos futuros desta série. (Descubra mais sobre feeds RSS do conteúdo do developerWorks.)
- Saiba mais sobre o Hadoop, software livre e indenização com demos gratuitas do Cloudera Hadoop.
- Faça o download das demos do Cloudera Hadoop.
- Saiba mais sobre a parceria IBM e Cloudera lendo o artigo do developerWorks “Integration at the Hadoop level: IBM’s BigInsights now supports Cloudera” .
- Leia o livro “Hadoop the Definitive Guide” por Tom White, terceira edição.
- Leia o livro “Programming Hive” por Edward Capriolo, Dean Wampler e Jason Rutherglen.
- Leia o livro “HBase the Definitive Guide” por Lars George.
- Leia o livro “Programming Pig” por Alan Gates.
- Leia outros artigos do developerWorks por Marty Lurie.
- Visite a seção zona do Information Management do developerWorks para encontrar mais recursos para desenvolvedores e administradores do DB2.
- Fique atualizado com os eventos técnicos e webcasts do developerWorks com foco em uma variedade de produtos IBM e assuntos do segmento de mercado de TI.
- Participe de um resumo de instruções gratuito no briefing ao vivo e gratuito do developerWorks Live! para se atualizar rapidamente sobre produtos e ferramentas IBM e tendências do segmento de mercado de TI.
- Siga o developerWorks no Twitter.
- Acompanhe as demos on demand do developerWorks , que abrangem desde demos de instalação e configuração de produtos para iniciantes até funcionalidades avançadas para desenvolvedores experientes.
Obter produtos e tecnologias
- Baixe gratuitamente o Cloudera Hadoop.
- Faça o download do Informix Developer edition.
- Faça o download do DB2 Express-C edition.
- Instale o driver Informix.
- Instale o driver DB2 da página IBM Software .
- Instale o driver DB2 da página do IBM Support Portal.
- Crie seu próximo projeto de desenvolvimento com o o software de teste IBM, disponível para download diretamente do developerWorks.
- Avalie produtos IBM da maneira que for melhor para você: faça download da versão de teste de um produto, avalie um produto online, use-o em um ambiente de nuvem ou passe algumas horas na Sandbox da SOA aprendendo a implementar Arquitetura Orientada a Serviços de modo eficiente.
Discutir
Participe da comunidade do My developerWorks. Entre em contato com outros usuários do developerWorks e explore os blogs, fóruns, grupos e wikis voltados para desenvolvedores.
***
Sobre o autor: Marty Lurie começou a sua carreira na informática gerando fragmentos de papel perfurado enquanto tentava escrever códigos em Fortran em um IBM 1130. Ele trabalha durante o dia como Engenheiro de sistemas Hadoop na Cloudera, mas se for pressionado vai admitir que na maior parte do tempo ele brinca com computadores. Seu programa favorito é o que ele escreveu para conectar o aparelho de ginástica Nordic Track ao seu laptop (o laptop perdeu um quilo e baixou o colesterol em 20%). Marty é Administrador de Hadoop e Desenvolvedor de Hadoop certificado pela Cloudera, Administrador de WebSphere avançado certificado pela IBM, profissional certificado pela Informix, DB2 DBA certificado, Profissional de soluções de Business Intelligence certificado, certificado em Linux+ e treinou seu cachorro para jogar basquete. Entre em contato com Marty em marty@cloudera.com.
***
Artigo original disponível em: http://www.ibm.com/developerworks/br/data/library/techarticle/dm-1209hadoopbigdata/index.html

De 0 a 10, o quanto você recomendaria este artigo para um amigo?