

Olá, pessoal! Tudo certo?
No artigo de hoje eu quero compartilhar com vocês algumas dicas para quem quer iniciar um tuning em alguma rotina, seja stored procedure, function ou query adhoc.
Quando vamos iniciar um trabalho de tuning, uma das primeiras informações que precisamos é visualizar o plano de execução da query e as informações de estatísticas.
Mas antes vamos entender um pouco os passos que o Otimizador de Consultas segue para executar uma query.
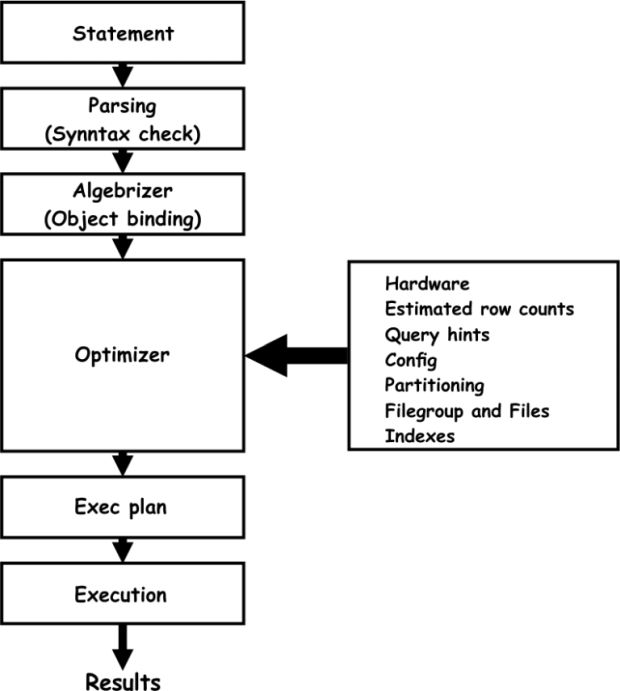
Primeiro o Otimizador de Consultas faz o “Parsing“ do comando para validar se a sintaxe do comando está correta.
O código estando correto, é gerado o que chamamos de parser tree, que contém os passos lógicos para a execução da consulta SQL.
O segundo passo é o que chamamos de Algebrizer. Essa é a etapa que faz a normalização do comando que recebe do parser tree, verifica a existência dos objetos utilizados na consulta (tabelas, colunas, etc), além de outras tarefas, como validar se o usuário que está executando tem permissão de acesso, valida as constraints e etc. A saída desse passo é um metadado com as informações.
O terceiro passo é o que chamamos de Optimizer, que vai fazer a leitura do metadado recebido da fase anterior e vai começar a analisar os operadores físicos e lógicos que ele vai utilizar. Também vai analisar os hints que estão na query e os operadores de JOIN.
Após isso, ele vai começar a gerar vários planos de execução. Dentre os planos gerados, ele vai escolher o que for classificado como bom o suficiente “good enough“.
Para ele escolher esse plano ele leva em consideração o custo de cada operação, além do custo de recursos como IO e CPU.
Uma vez que o otimizador de consultas gera o plano de execução, ele é então armazenado em uma área de memória denominada plan cache, que é uma área onde ficam armazenados todos os planos de execução do SQL Server.
Concluído o terceiro passo, agora que o nosso plano de execução está gerado, o SQL Server sabe exatamente como chegar nos dados, então ele é colocado na fila de execução que é o passo Execution ou Exec Plan.
1. Plano de Execução
- Tiago, o que seria o plano de execução?
Apesar de quase 100% das pessoas que trabalham com SQL Server saberem o que é o plano de execução e pra quê ele serve, se você está começando a trabalhar com banco de dados agora, vou dar uma resumida.
O primeiro ponto é que o Plano de Execução não é exclusivo do SQL Server – todos os SGBDs que eu conheço têm planos de execução (Oracle, MySQL, Postgree, etc), que nada mais é do que uma representação gráfica, textual ou em XML que mostra quais operadores e operações que o otimizador de consultas fez para retornar os dados da sua query e também o custo de cada operação realizada.
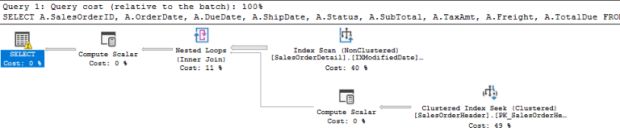
Com esse recurso você consegue ver as etapas de execução da sua query e assim verificar o que pode ser melhorado.
Para gerar um plano de execução de uma instrução, você pode simplesmente utilizar o atalho “Ctrl + M” ou então clicar no ícone destacado na imagem abaixo:

O plano de execução também pode nos dar informação de sugestão de índices do SQL Server.
- Mas o que seriam essas sugestões de criação de índices?
Por exemplo, quando executamos uma consulta, o otimizador de consultas utiliza as estatísticas e identifica que a query que você está executando teria um desempenho melhor se a tabela X tivesse um índice na coluna Y.

Como podemos observar na imagem acima, o otimizador de consultas está nos sugerindo um índice na tabela “Sales.Customer“, que vai gerar um impacto de “97%” na execução da consulta.
Para fazer a leitura do plano de execução, as literaturas recomendam que devemos começar da esquerda para a direita e de cima para baixo, uma vez que isso facilita a nossa interpretação.
Porém, o Otimizador de Consultas constrói os planos de execução da direita para a esquerda e de cima para baixo. Também precisamos aprender o que significa cada operador ou pelo menos os principais deles.
Para consultar os operadores podemos consultar o Books Online (BOL).
Entenderemos melhor com um plano de execução um pouco mais complexo. Vamos exibir o plano de execução da query abaixo:
WITH
LastDayOrderIDs AS
(
SELECT SalesOrderID FROM Sales.SalesOrderHeader
WHERE OrderDate = (SELECT MAX(OrderDate) FROM Sales.SalesOrderHeader)
),
LastDayProductQuantities AS
(
SELECT ProductID, SUM(OrderQty) AS LastDayQuantity
FROM Sales.SalesOrderDetail
JOIN LastDayOrderIDs
ON Sales.SalesOrderDetail.SalesOrderID = LastDayOrderIDs.SalesOrderID
GROUP BY ProductID
),
LastDayProductDetails AS
(
SELECT
Product.ProductID,
Product.Name,
LastDayQuantity
FROM Production.Product
JOIN LastDayProductQuantities
ON Product.ProductID = LastDayProductQuantities.ProductID
)
SELECT * FROM LastDayProductDetails
ORDER BY LastDayQuantity DESC;Para entender o plano vamos utilizar a recomendação literária que fica mais fácil o entendimento.
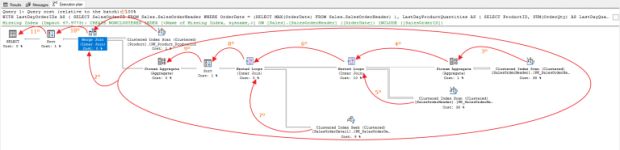
1 – Otimizador de consulta executou uma operação de “Cluster Index Scan”

3 – Realizou outra operação de “Cluster Index Scan”

4 – Fez uma agregação dos dados utilizando o operador “Stream Aggregate”. Essa primeira agregação é referente à função MAX (SELECT MAX(OrderDate) FROM Sales.SalesOrderHeader)

Dica: quando clicamos com o botão direito em propriedades do operador, temos as informações sobre o que o operador está fazendo.
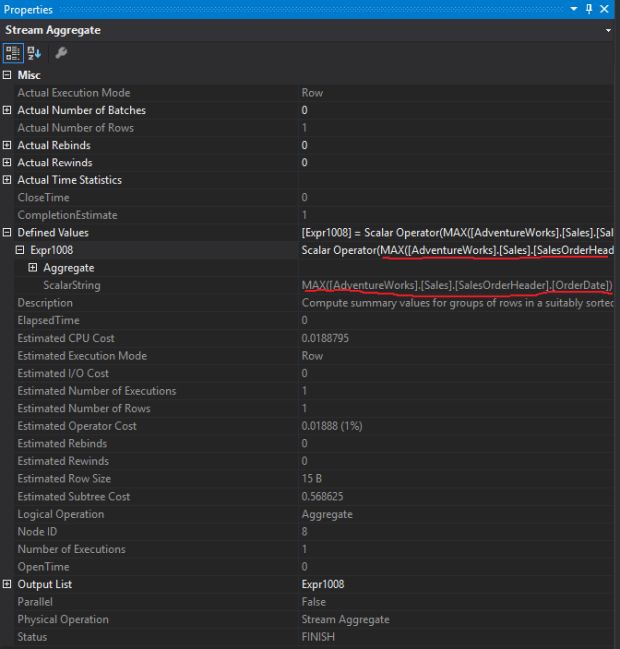
5 – Realizou outra operação de “Cluster Index Scan”

6 – Fez o join dos dados através do operador “Nested Loops”

7 – Agora fez uma operação de “Cluster Index Seek”

8 – Realizou o join entre os resultados dos passos (4, 5, 6 e 7) com o operador “Nested Loops”

9 – Realizou a ordenação dos dados utilizando o operador de “Sort”

10 – Fez uma nova agregação dos dados por causa do “Group By” – (GROUP BY ProductID)

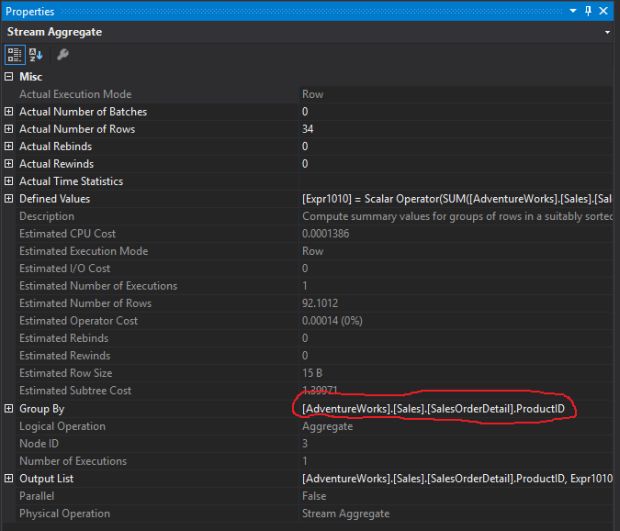
2 – Agora, com a segunda parte dos dados da query já retornados, o otimizador de consultas vai realizar o join utilizando o operador “Merge Join“

11 – Vai realizar mais uma ordenação utilizando o operador “Sort” ordenando os dados da CTE (ORDER BY LastDayQuantity DESC;)

12 – Finalmente vai retornar os dados do Select

Agora vamos ver como o Otimizador de Consulta monta o plano de execução. Como dito anteriormente, ele monta o plano da direita para a esquerda.
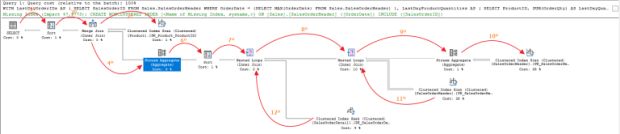
Como explicado anteriormente, quando executamos uma query, ela passa por algumas fases e na fase do Optimizer que será gerado o plano de execução.
Com isso, a engine sabe exatamente o caminho, a ordem, e quais operadores ela vai utilizar para alcançar o objetivo. Por esse motivo, ele gera os planos sempre da direita para esquerda.
1 – Select

2 – Sort

3 – Merge Join

4 – Cluster Index Scan

5 – Stream Aggregate

6 – Sort

7 – Nested Loops

8 – Nested Loops

9 – Stream Aggregate

10 – Cluster Index Scan

11 – Cluster Index Scan

12 – Cluster Index Seek

Pra você identificar qual é a ordem em que o plano está sendo executado, você consegue essa informação nas propriedades de cada operador na propriedade Node ID, lembrando que a contagem começa no Node ID: 0.
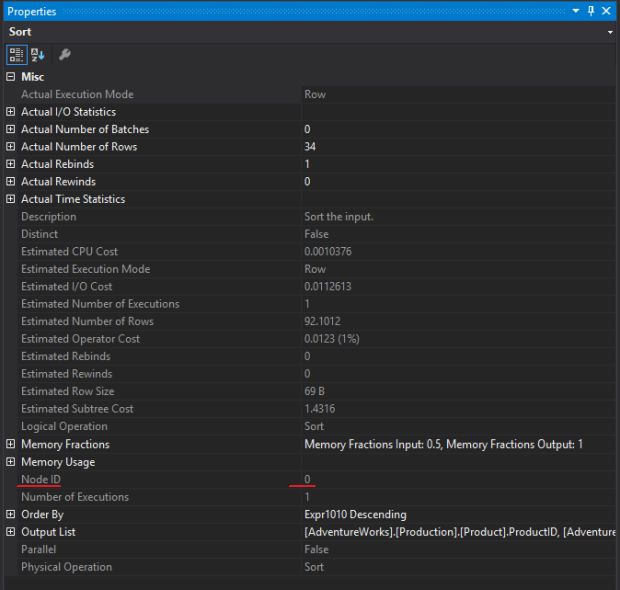
Outra opção que nos ajuda a entender a ordem em que o SQL Server está executando a nossa query é habilitando a opção “set statistics profile on”.
<strong>SET STATISTICS PROFILE ON</strong>
WITH LastDayOrderIDs
AS (SELECT SalesOrderID
FROM Sales.SalesOrderHeader
WHERE OrderDate =
(
SELECT MAX(OrderDate) FROM Sales.SalesOrderHeader
)),
LastDayProductQuantities
AS (SELECT ProductID,
SUM(OrderQty) AS LastDayQuantity
FROM Sales.SalesOrderDetail
JOIN LastDayOrderIDs
ON Sales.SalesOrderDetail.SalesOrderID = LastDayOrderIDs.SalesOrderID
GROUP BY ProductID),
LastDayProductDetails
AS (SELECT Product.ProductID,
Product.Name,
LastDayQuantity
FROM Production.Product
JOIN LastDayProductQuantities
ON Product.ProductID = LastDayProductQuantities.ProductID)
SELECT *
FROM LastDayProductDetails
ORDER BY LastDayQuantity DESCO retorno dessas informações nos ajuda a identificar a ordem dos operadores e também quais são os operadores físicos e quais são os operadores lógicos, além de outras informações.

Como falamos no começo do artigo, outro ponto muito importante a ser observado são as estatísticas da query, quantas operações de leituras físicas, lógicas e consumo de CPU o SQL Server efetuou para executar a sua consulta.
Para obter essas informações, basta habilitar as estatísticas antes de executar o comando “set statistics io,time on” .
<strong>SET STATISTICS IO,time ON</strong>
WITH LastDayOrderIDs
AS (SELECT SalesOrderID
FROM Sales.SalesOrderHeader
WHERE OrderDate =
(
SELECT MAX(OrderDate) FROM Sales.SalesOrderHeader
)),
LastDayProductQuantities
AS (SELECT ProductID,
SUM(OrderQty) AS LastDayQuantity
FROM Sales.SalesOrderDetail
JOIN LastDayOrderIDs
ON Sales.SalesOrderDetail.SalesOrderID = LastDayOrderIDs.SalesOrderID
GROUP BY ProductID),
LastDayProductDetails
AS (SELECT Product.ProductID,
Product.Name,
LastDayQuantity
FROM Production.Product
JOIN LastDayProductQuantities
ON Product.ProductID = LastDayProductQuantities.ProductID)
SELECT *
FROM LastDayProductDetails
ORDER BY LastDayQuantity DESC
Como podemos ver nas informações estatísticas, a operação mais custosa para a execução da consulta foi a leitura na tabela “SalesOrderHeader” e a nossa consulta teve um custo de 9 ms.
Apenas uma observação para quem não conhece a operação de logical reads, pois não é uma leitura dos dados no disco, e sim na memória.
Quando existe leitura em disco, o valor que será mostrado é o physical reads. Em alguns casos onde os dados ainda não estão em memória, o SQL pode fazer leitura física, mas na próxima execução da consulta, os valores estariam zerados.
Isso vai depender de como está o seu PLE (Page Life Expectancy – Expectativa de vida em segundos de uma página na memória do SQL Server, bom para monitorar se você está mantendo dados em cache por muito tempo, evitando acessos a disco).
Existe uma ferramenta que utilizo bastante, que é a SentryOne Plan Explorer. Ela é FREE e nos ajuda bastante quando vamos realizar um tuning.
Quando executamos uma query nessa ferramenta, ela retorna os planos de execução, estatísticas e qual operação foi mais custosa para o SQL Server executar.
Costumo dizer que é uma ferramenta fantástica. Nas imagens a seguir podemos ver as informações que ela nos retorna.
Quando vamos utilizar o plan explorer devemos clicar em “New Plan Explorer Session”.
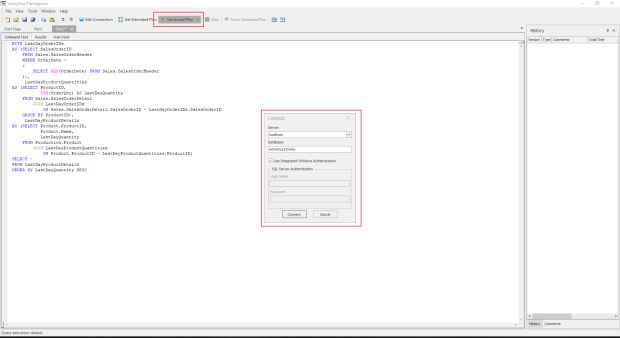
Depois de escrever sua query, você deverá clicar em “Get Actual Plan” e preencher as informações de acesso ao banco como instância, base de dados e login/senha.
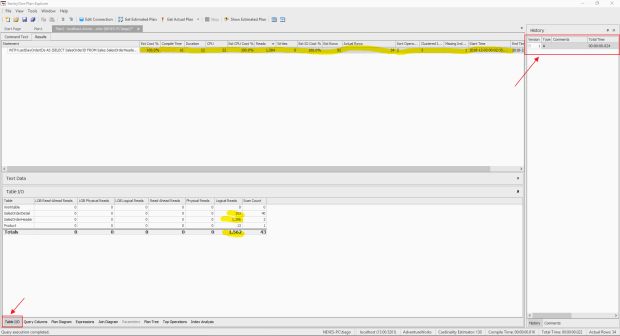
Como podemos observar, a nossa primeira execução da query foi com o tempo de 24 ms. Também podemos ver as informações de “Table I/O”, que são as informações de I/O que a nossa consulta executou. Essa informação é a mesma que temos quando executamos o “set statistics io”, no Management Studio.
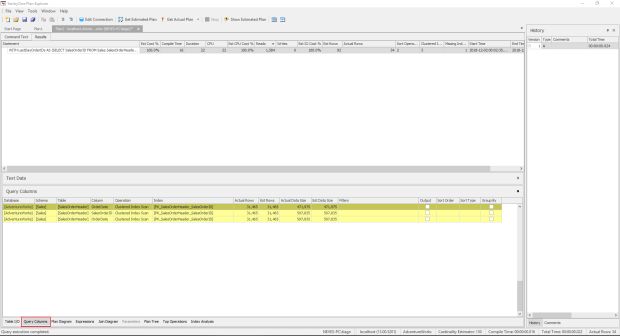
Na aba “Query Columns” podemos ter informações sobre quais colunas e tabelas a nossa query acessou e qual o custo de cada acesso.
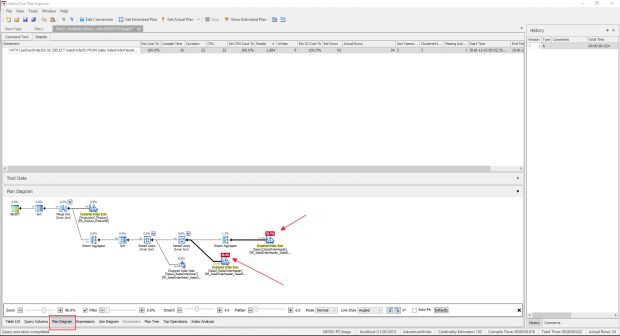
Na aba “Plan Diagram” temos o mesmo plano de execução que conseguimos quando executamos a consulta no Management Studio.
Porém, no Plan Explorer ele nos mostra quais foram as top operações.
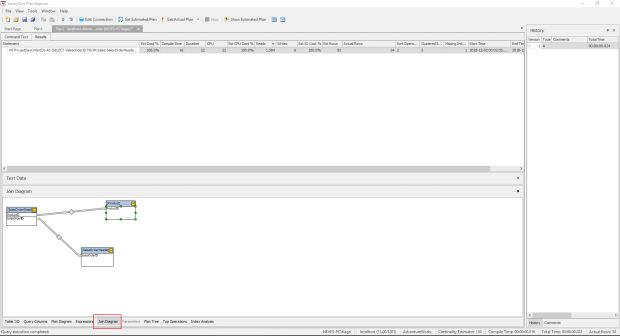
Na aba “Join Diagram”, nós temos um diagrama dos relacionamentos das tabelas da query.
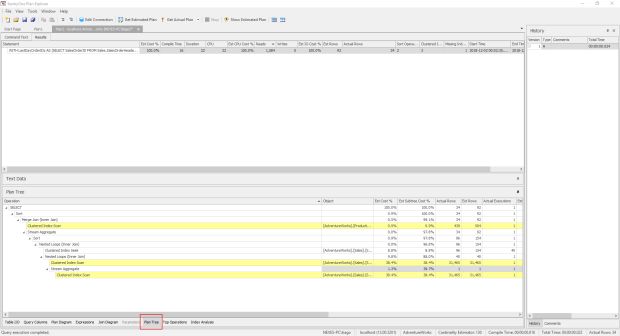
Semelhante ao “set statistics profile” no Management Studio, a aba “Plan Tree” nos informa a ordem do steps que o SQL Server fez para executar nossa query.
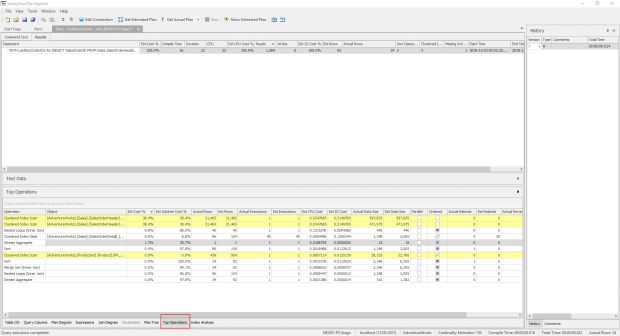
A aba “Top Operations” retorna uma tabela com os custos de cada operação do plano de execução, bem como as estimativas, se o operador utilizou paralelismo para executar, entre outras.
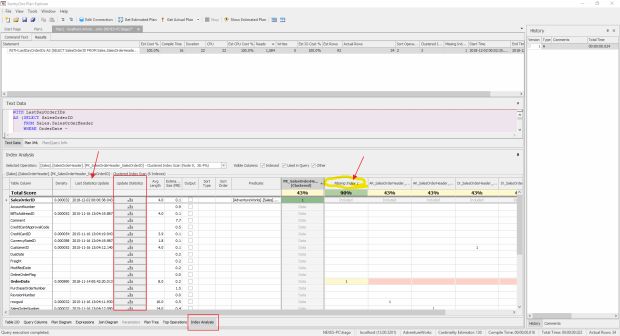
Por fim, a aba “Index Analysis“ faz uma análise de cada índice que foi utilizado na nossa consulta, inclusive mostrando o ganho que teríamos ao utilizar o índice sugerido pelo SQL Server. Também podemos ver que algumas estatísticas estão desatualizadas.
O legal da ferramenta é que podemos atualizar as estatísticas e criar o índice direto por ela sem precisar conectar no Management Studio.
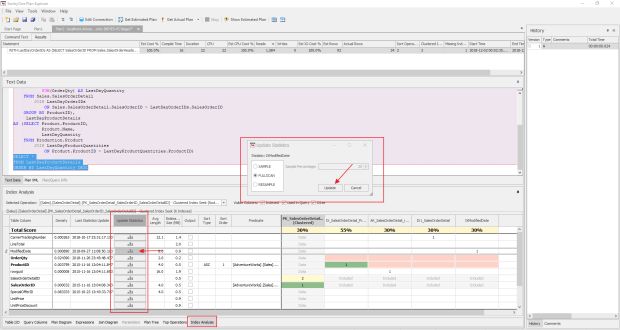
Para atualizar as estatísticas no próprio SentryOne, basta clicar no gráfico que vai abrir uma janela para você configurar as opções de atualização de estatísticas, lembrando que se você não tiver permissão para atualizar estatísticas, vai dar erro.
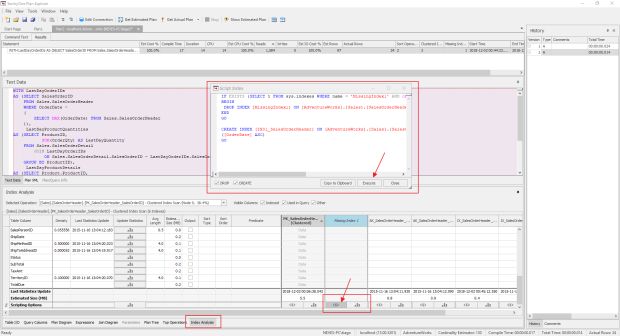
Dá mesma forma, podemos criar um índice sugerido pelo SQL Server. Para isso, basta clicar no “<s>” que o Plan Explorer vai mostrar o script de criação do índice, e caso você ache necessário acrescentar alguma coluna ou alguma opção de criação, basta editar o script.
Atenção:
- “Criar índices e atualizar estatísticas em ambiente de produção durante o horário comercial pode impactar a performance do servidor e gerar locks.”
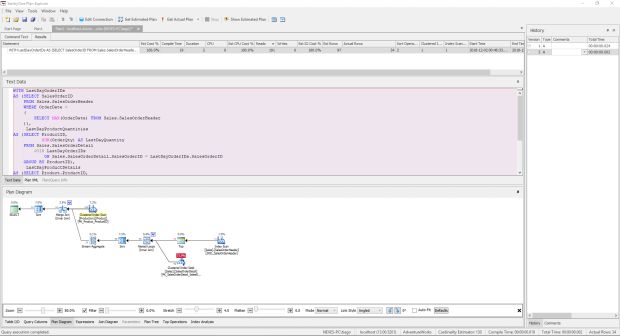
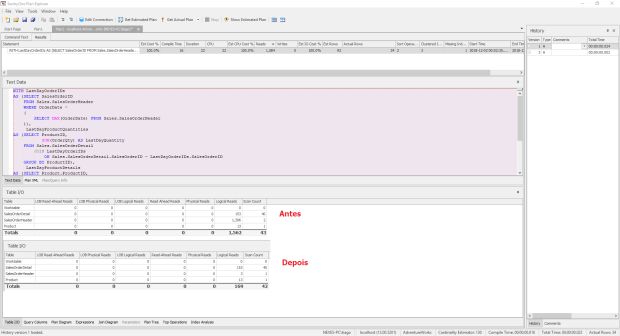
Por fim, no painel direito temos um histórico de execução da nossa query, onde podemos analisar e comparar as execuções e ver se tivemos algum ganho.
Como podemos verificar, após atualizar as estatísticas e criar o índice sugerido pelo SQL Server, a nossa query baixou a quantidade de I/O de 1.562 para 169 e, consequentemente, o tempo de 24 ms para 02 ms, além de gerar um novo plano de execução.
Como podemos ver, temos n formas de executar um tuning, e além de ferramentas como o SentryOne Plan Explorer, existem outras, mas não adianta você ter as ferramentas se você não tiver uma noção dos operadores, qual está sendo o seu gargalo e etc.
Deixo a seguir alguns links com os vídeos dos treinamentos On-demand do Fabiano Amorim e do Luti. Os treinamentos foram disponibilizados no YouTube em seus respectivos canais.
Treinamento Fabiano – PE Parte I – QO, lookup, sort e merge join:
Treinamento Luti – Indexação:
O #TeamFabricioLima lançou uma plataforma de curso e temos alguns treinamentos do Fabiano. Na data de criação deste artigo, tínhamos o 25 Dicas de Performance no SQL Server Parte 1 e + 25 Dicas de Performance no SQL Server Parte 2.
Para quem quiser adquirir alguns do cursos do Fabiano na plataforma do #TeamFabricioLima, recomendo esse cupom de desconto: BLOGTIAGONEVES10.
Bom, pessoal, por hoje é isso. Espero que tenham gostado e espero ter ajudado quem está começando a trabalhar com tuning.
Abraços!
Referencias
- SQL Server 2017 Query Performance Tuning – Troubleshoot and Optimize Query Performance – Fritchey, Gran
- High Performance SQL Server – Nevarez, Benjamin

De 0 a 10, o quanto você recomendaria este artigo para um amigo?