



Data Analysis com Python Pandas – o início
Uma das coisas que mais gostei no livro Python for Data Analysis foi seu segundo capítulo (Introductory Examples), onde o autor faz algumas "demostrações" das ferramentas apresentando um pouco do poder que elas têm! E é isso que eu vou reproduzir agora.

E aí pessoal, tudo bem?
Faz bastante tempo que não publico nada novo, pois estive muito envolvido com questões menos técnicas nesse período, estudando coisas que literalmente mudaram minha forma de ver o mundo. Mas isso fica pra outra hora…
O que me motivou a voltar a escrever são meus recentes estudos sobre análise de dados com Python, em especial com a biblioteca Pandas!
Primeiro contato
Em 2012, estive na Python Brasil 8, no Rio de Janeiro, e no final do evento, fui sorteado para ganhar um presente, contrariando todas as probabilidades. O livro em questão é o ótimo Python for Data Analysis, de Wes McKinney.
Chegando do evento, comecei a ler o livro e a brincar com as ferramentas. O problema é que não consegui instalar a maioria das bibliotecas. Tentei de várias formas, dentro e fora do virtualenv, com pip e apt-get, compilando as libs em C etc, mas não consegui; de modo que a brincadeira terminou cedo. =/
O livro ficou na estante por todo este tempo e sempre me ressentia por não ter continuado os estudos, até que recentemente, motivado por vários projetos e notícias, resolvi tentar novamente!
Desta vez, todas as libs foram instaladas de primeira com o pip e dentro da virtualenv. Este fato, por si só, já merecia um artigo! O livro é ótimo e me empolguei bastante com os estudos, a ponto de pagar um curso online no Udemy sobre Data Analysis!
Ainda estou no começo, apanhando um pouco, mas hoje consegui trabalhar alguns dados e gerar algumas visualizações e, por isso, resolvi escrever este texto!
Primeira análise real
Uma das coisas que mais gostei no livro Python for Data Analysis foi seu segundo capítulo (Introductory Examples), onde o autor faz algumas “demostrações” das ferramentas apresentando um pouco do poder que elas têm! Não tenho dúvidas do quanto foi importante ver (e fazer!) estas demostrações. Todas elas usam dados reais, que são relevantes e fazem sentido para o leitor. Isso faz muita diferença.
Por conta disso, precisava de dados reais e que fizessem sentido para mim, caso contrário, a análise não seria tão interessante. Acabei escolhendo jogos da loteria, da Loto Fácil para ser exato. Os escolhi porque eu poderia descobrir algum padrão e ficar muito rico eles têm mais de 1400 jogos de histórico e nessa loteria são sorteados 15 dezenas, o que dá um bom volume de dados.
Sendo assim, mãos na massa!
Mão na massa
Para seguir os passos abaixo, você precisa apenas das libs Pandas e Matplotlib, que podem ser instaladas via pip!
Você pode baixar todo o histórico dos jogos da Loto Fácil na página deles, que está no link. Os dados estão no formato HTML, o que deixa mais interessante!
Abaixo estão as poucas linhas de código necessárias para carregar os dados, ajustá-los e começar as primeiras análises (não que eu tenha acertado tudo de primeira). Vou inserir alguns comentários explicando um pouco!
import pandas as pd
# necessário para gerar as visualizações
%matplotlib
# Carregamos os dados direto do arquivo html e pegamos o 1º dataset da página.
loto = pd.io.html.read_html('/home/rafael/Downloads/lotofacil/D_LOTFAC.HTM')[0]
# O dataset original inclui várias linhas em branco. Aqui nós
# excluímos as linhas que não nos interessam.
loto.dropna(thresh=15, inplace=True)
# O dataset inclui algumas colunas que não são do nosso interesse, vamos reduzir.
ltframe = loto[range(17)]
# Os nomes das colunas foram carregados como valores. Aqui renomeamos as colunas.
ltframe.columns = [
'Concurso', 'Data Sorteio', 'Bola1', 'Bola2', 'Bola3', 'Bola4', 'Bola5', 'Bola6', 'Bola7', 'Bola8', 'Bola9', 'Bola10', 'Bola11', 'Bola12', 'Bola13', 'Bola14','Bola15'
]
# Aqui apagamos a primeira linha, que na verdade são os nomes das colunas.
ltframe.drop(0, inplace=True)
# Uma lista com os nomes das colunas que guardam os jogos.
bolas = ['Bola%s' % i for i in range(1,16)]
# Os resultados precisam ser convertidos para inteiros.
ltframe[bolas] = ltframe[bolas].apply(pd.to_numeric)
# Criamos uma nova coluna, com a soma das dezenas sorteadas em cada jogo.
ltframe['Soma'] = ltframe[bolas].sum(axis=1)
Visualizações
Agora podemos gerar as primeiras visualizações que nos ajudam a tirar algumas conclusões!
ltframe.plot(x='Data Sorteio', y='Soma')
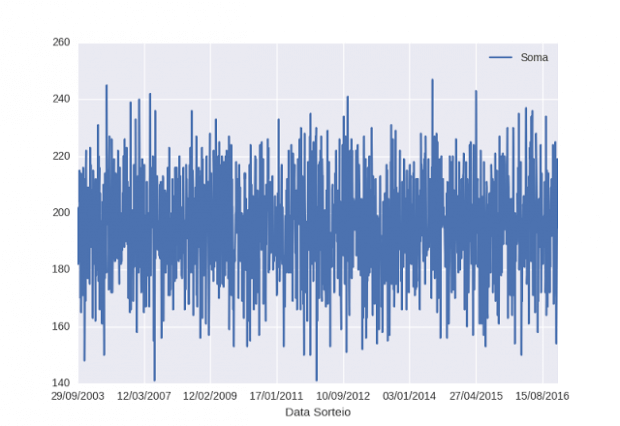
Nesse gráfico dá pra ver que a maior concentração de resultados fica entre 180 e 220, então, podemos dizer que jogos cuja soma esteja acima ou abaixo desse intervalo tem menor chance de acerto!
ltframe.reset_index().plot.scatter(x='index', y='Soma') ltframe.reset_index().plot.hexbin(x='index', y='Soma')
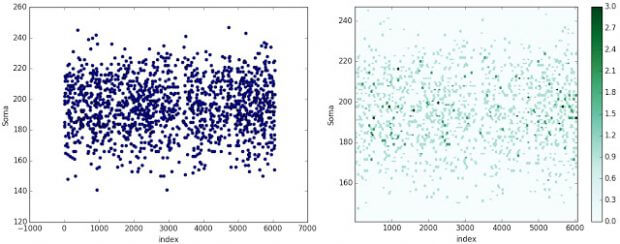
Nestas 2 outras imagens podemos confirmar a maior concentração da soma de resultados entre 180 e 220. Nestes casos, tive de usar o índice no lugar da data de sorteio.
Conclusão
Estas foram análises bem introdutórias, mas é possível fazer muito mais! Vou continuar estudando e pretendo postar mais coisas aqui no blog sobre estes assuntos!
Se você também tem interesse em análise e ciência de dados, este é o momento de começar a estudar! Está muito mais fácil fazer o setup necessário e a quantidade de material disponível só aumenta! Este é o futuro.
Se tiver alguma dúvida, critica ou sugestão, deixe nos comentários.
Um abraço!
é analista de sistemas/desenvolvedor formado pela FATEC-BS e pós-graduado em Engenharia de Software pela PUC-SP. Sócio e co-fundador da StormIdeas, empresa criadora do MailerWeb. Entusiasta de Linux e Python, interessado por tecnologia em geral e vários outros assuntos nerds.



