
No post anterior expliquei um pouco como funciona uma arquitetura orientada a eventos e como implementamos essa arquitetura na Convenia. Comentei um pouco sobre o nosso tratamento de erros e hoje pretendo me aprofundar mais nesse assunto.
Assim como no post anterior gostaria de enfatizar que as escolhas de arquitetura e stack fazem sentido para o nosso tamanho e previsão de crescimento. Possivelmente para você não faça sentido fazer tudo da mesma forma como fazemos uma vez que cada projeto é único com as suas particularidades, mesmo assim é provável que você consiga tirar algo de bom desse post.
Nesse post as palavras “mensagem” e “evento” representam a mesma coisa mas em contextos diferentes, a grosso modo “mensagem” é o nome dado a informação em transito através de um message broker e evento é o nome dado para a mensagem em um contexto “orientado a eventos”, “listener” é o nome dado ao processo responsável por “ouvir” eventos.
Como os serviços se comunicam?
A seguir vamos analisar um exemplo simples utilizando o Pigeon bem parecido com o do post anterior:
Pigeon::dispatch('employee.created', [
'name' => 'Scooby Doo'
]);No exemplo acima estamos emitindo o evento employee.created que tem como body o nome do colaborador, para ouvir esse evento em outro serviço com o Pigeon temos esse código:
Pigeon::events('employee.created')
->callback(function ($event, ResolverContract $resolver) {
//doing nice things
$resolver->ack();
})->fallback(Throwable $exception, $message, $resolver) {
//send to sentry
$resolver->reject(false);
})->consume(0, true);O código acima faz algumas coisas
- Configura o Pigeon para ouvir o evento
employee.createdem outro serviço, com a chamadaPigeon::events('employee.created'). - Define um callback para “lidar” com o evento passando uma Closure através do método
->callback(), essa Closure será executada cada vez que o eventoemployee.createdfor “ouvido”. - Define um fallback através do método
->fallback(), essa closure será executada sempre que acontecer uma exception dentro do callback. - O método
->consume()começa a consumir a fila de fato.
O Pigeon utiliza RabbitMQ para intermediar a comunicação entre os dois serviços, se tentarmos mostrar isso em um diagrama teremos o seguinte:
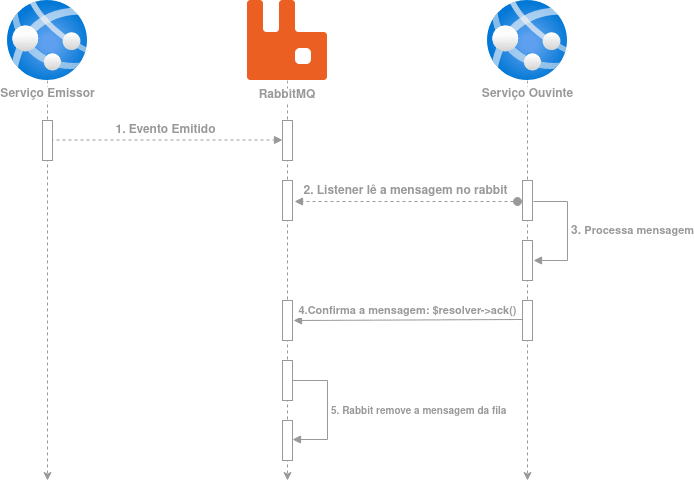
No momento em que o serviço lê a mensagem do RabbitMQ a mensagem fica em um estado “unacked”, isso significa que o Rabbit está esperando a confirmação dessa mensagem por parte de quem a leu. O RabbitMQ não entregará essa mensagem a mais ninguem até receber a confirmação de que algo deu certo ou a confirmação de que algo deu errado(rejeição) com a mensagem. No passo 4 retratado no diagrama acima fazemos uma confirmação na mensagem para o RabbitMQ saber que ela foi processada corretamente, apenas depois de receber essa confirmação o RabbitMQ remove a mensagem da fila.
O diagrama acima mostra um caminho muito feliz mas vamos imaginar que logo após ler a mensagem, o serviço ouvinte “morre” devido a algum problema de hardware antes de confirmar a mensagem:
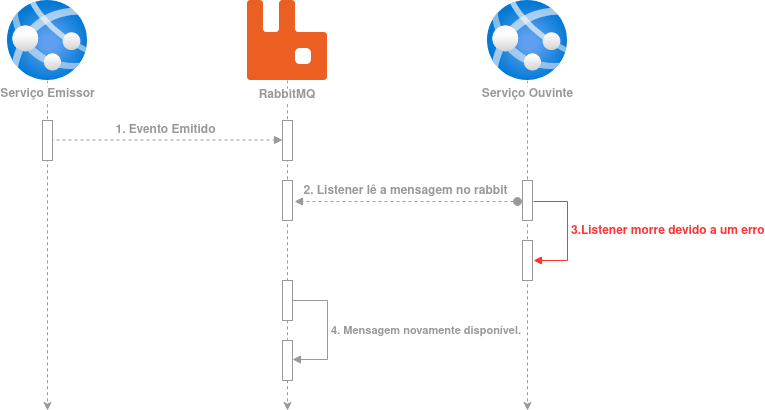
De forma similar ao exemplo anterior, após a leitura da mensagem o Rabbit coloca a mensagem no estado “unacked”, ao processar a mensagem um erro muito inesperado acontece e o Listener(processo) morre no passo 3, nesse momento o Rabbit sabe que deve voltar a mensagem para o estado de “ready”, assim outro listener pode tentar processar essa mesma mensagem, isso é possível porque os listeners mantém uma conexão aberta com o Rabbit e quando o processo do listener morre a conexão com o Rabbit é “cortada”, nesse momento ele sabe que deve “liberar” todas as mensagens que aquele listener leu mas não confirmou.
Até o momento mostramos fluxos saudáveis e falhas de terceiros que podem acontecer esporadicamente mas e quando nosso próprio código que consome a mensagem está quebrado? E quando a própria mensagem está quebrada?
Dead Letter Exchange para o Resgate
Vamos tentar imaginar a seguinte situação onde o código do nosso próprio listener está quebrado:
Pigeon::events('employee.created')->callback(function ($event, ResolverContract $resolver) {
doesNotExists();
$resolver->ack();
})->consume(0, true);No código acima repare a chamada para a função doesNotExists(), como o próprio nome já diz essa função não existe e quando esse listener tentar consumir uma mensagem ele vai entrar no fluxo retratado na imagem 2. O grande problema é que normalmente utilizamos algum recurso como o supervisord para “reviver” os processos que morrem e quando esse listener “voltar a vida” ele vai entrar no fluxo da imagem 2 novamente entrando em um looping.
Temos uma mensagem sendo consumida em looping, ela será consumida corretamente apenas se o código do listener for corrigido, isso causa vários problemas como mostrado no post anterior. O RabbitMQ, não por acaso, tem um recurso chamado dead letter exchange que serve para esse tipo de situação e com esse recurso a mensagem pode ser enviada em uma exchange separada para ser tratada posteriormente, como mostra o fluxo a seguir:
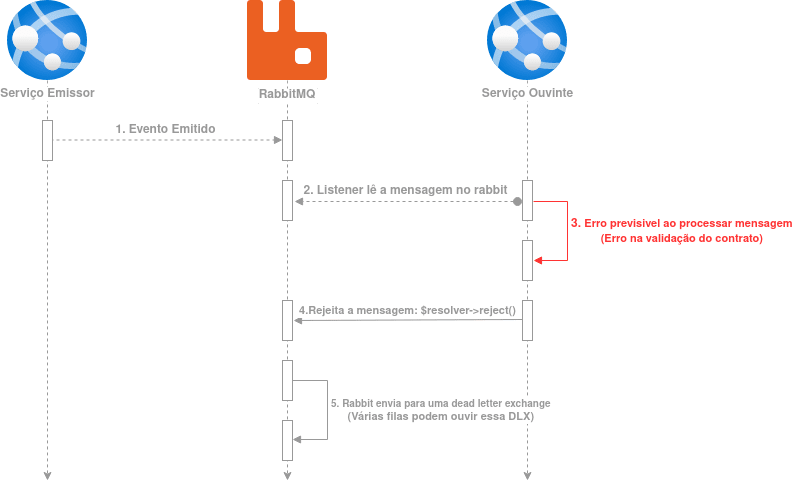
Para esse fluxo acontecer precisamos “rejeitar” explicitamente a mensagem através do método fallback mostrado no inicio do artigo e retratado novamente a seguir:
->fallback(Throwable $exception, $message, $resolver) {
//send to sentry
$resolver->reject(false);
})No código acima a chamada $resolver->reject(false); é a chamada que rejeita explicitamente a mensagem, caso você não defina um fallback, o Pigeon tem um fallback padrão que rejeitará a mensagem caso a env PIGEON_ON_FAILURE esteja presente com o valor reject.
LetterThief
Após rejeitar a mensagem, ela irá para uma dead letter exchange de onde podemos armazenar essa mensagem problemática em uma fila, avaliar mais tarde ou dar um tratamento digno para ela ali mesmo. No caso da Convenia desenvolvemos um serviço chamado “LetterThief” que é responsável por gerenciar as mensagens que foram rejeitadas e avisar o time quando ocorre uma rejeição:
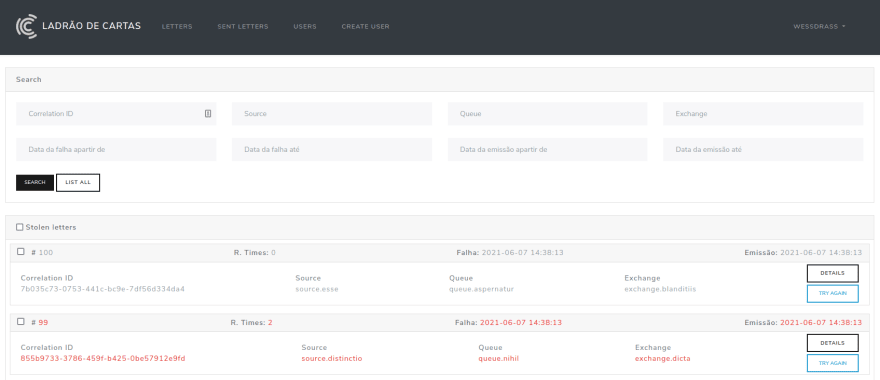
Acima está retratada a listagem das mensagens rejeitadas, nesse serviço conseguimos filtrar as mensagens pela suas propriedades, Toda rejeição ocorre em uma fila e exchange específicas e em um certo momento. Os filtros são capazes de trazer rejeições que ocorreram em uma determinada fila ou em um determinado momento.
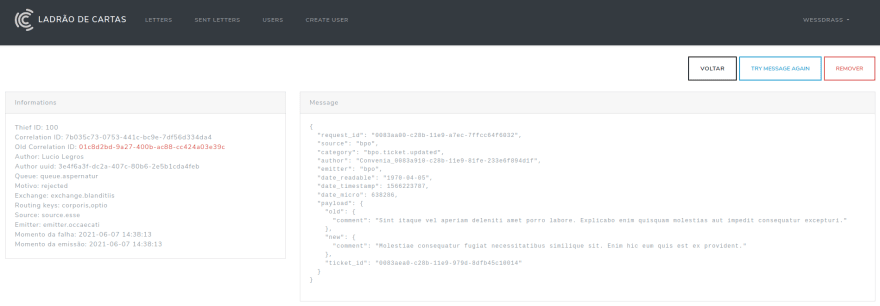
Ná página de detalhes da mensagem rejeitada temos todas as informações da mensagem, sabemos de que serviço ela veio, sabemos qual foi o listener que a rejeitou e o mais importante, temos o correlation_id que será utilizado para confrontar o erro com as exceptions que cairem no sentry. Com essas informações sabemos exatamente o porque uma mensagem foi rejeitada e o envio para o sentry é feito pelo listener logo antes de rejeitar a mensagem:


As imagens acima mostram um erro real que ocorreu no ambiente de produção e a parte de tags contendo o correlation_id, infelizmente não posso mostrar a exception com mais detalhes para não expor dados sensíveis :/
Legal, o serviço traz bastante visibilidade para os erros que ocorreram mas como os desenvolvedores são avisados sobre o ocorrido? O LetterThief tem uma integração com o slack assim toda a equipe é notificada quando um erro ocorre e pode agir imediatamente para resolver o problema.

Na imagem acima vemos a notificação que chega no slack, ela contém a fila onde ocorreu o problema e o link para a mensagem no serviço do LetterThief, dessa forma o desenvolvedor responsável já sabe que deve corrigir o problema o quanto antes.
Você deve estar se perguntando o que acontece com a mensagem após a correção do problema já que muito provavelmente ela deveria causar algum efeito no sistema mas acabou não causando devido ao erro ocorrido, após resolver o erro o desenvolvedor tem a capacidade de reenviar a mensagem através do LetterThief.

Na imagem acima é possível ver o botão “TRY MESSAGE AGAIN” que resulta nessa confirmação que está sendo exibida, após a confirmação, a mensagem será reenviada diretamente para a fila de onde o erro foi causado, dessa forma o processamento deve ocorrer normalmente.
Cuidados adicionais
Você deve estar se deparando com algumas questões após ter chego até aqui, a verdade é que para tudo isso funcionar corretamente temos que ter alguns cuidados que são garantidos em um fluxo rígido de code review:
- Os listeners devem ser idempotentes, como pode ocorrer um erro durante o processamento, no caso de uma criação no banco de dados por exemplo, não podem haver registros duplicados, devemos fazer a opção por uma função de
upsertao invés de umcreate, isso vai evitar que dois registros sejam criados quando a mensagem for reenviada, lembrando que a mensagem pode ser reenviada mais de uma vez. - O listener deve obrigatoriamente enviar a mensagem para o sentry e logo em seguida rejeitar a mensagem no fallback, muita lógica não é bem vinda aqui pois não podem haver falhas dentro do fallback, isso causaria a devolução da mansagem para a fila e o problema de reprocessamento infinito apresentado no inicio do post.
- Devemos ser cuidadosos ao avaliar datas dentro do listener, não devemos nunca avaliar o momento em que a mensagem chega no listener, sempre devemos avaliar a data em que o evento foi emitido, isso chega obrigatoriamente com todo o evento, dessa forma evitamos de processar uma data errada devido ao delay da mensagem.
Conclusão
Toda arquitetura distribuída tem uma complexidade mais elevada, observabilidade e tratamento de erros são pautas de muitas talks e donos da preocupação de várias equipes. Sem dúvidas em uma arquitetura orientada a eventos precisamos de uma forma de lidar com erros no processamento de mensagens assíncronas. No caso específico da Convenia a melhor saída foi fazer nosso próprio serviço que atende exatamente ao que precisamos. Existem outras opções de message broker como kafka que podem trazer soluções já prontas para esse problema, o que te economizará o trabalho de desenvolver e manter a solução, de qualquer forma é muito importante ter uma solução similar a essa para auxiliar a equipe no dia a dia.
O LetterThief foi desenvolvido com a premissa da segurança em relação a perda de mensagens, se reparar cuidadosamente vai ver que utilizando o LetterThief é impossível perder uma mensagem no meio do caminho, ou ela foi processada corretamente ou foi parar no LetterThief, caso o desenvolvedor do listener tenha sido muito transgressor ao implementar o listener, a mensagem voltará para a fila, independente da opção que adotarmos acho essa premissa de “nunca perder a mensagem” importante para se levar em consideração.
Artigo publicado originalmente aqui e republicado em iMasters a pedido do autor.

De 0 a 10, o quanto você recomendaria este artigo para um amigo?