

No Uber, fazemos um esforço para escrever serviços de back-end eficientes para manter os nossos custos de computação baixos. Isso se torna cada vez mais importante à medida que o nosso negócio cresce; aparentemente pequenas ineficiências são muito ampliadas na escalabilidade do Uber. Nós descobrimos que gráficos de chamas são uma ferramenta eficaz para a compreensão das características da CPU e memória dos nossos serviços, e os usamos muito em nossos serviços Go e JavaScript. A fim de obter gráficos de chamas de alta qualidade para os serviços Python, escrevemos um perfilador de alta performance chamado Pyflame, implementado em C++. Neste artigo, vamos explorar considerações de design e algumas características únicas de execução que fazem do Pyflame uma alternativa melhor para perfis do código Python.
Profilers determinísticos
O Python oferece diversos profilers determinísticos internos através dos módulos profile e cProfile. Os profilers determinísticos no Python (profile e cProfile) trabalham usando a facilidade sys.settrace() para instalar uma função de rastreamento que é executada em vários pontos de interesse, tais como o início e o fim de cada função e no início de cada linha lógica de código. Esse mecanismo produz informação de perfil de alta resolução, mas tem uma série de deficiências.
Alta sobrecarga
A primeira desvantagem é a sua extremamente alta sobrecarga: geralmente vemos isso reduzir a velocidade de programas em 2x. Pior, descobrimos que essa sobrecarga para causar número de perfis imprecisos em muitos casos. O módulo cProfile tem dificuldade em relatar com precisão estatísticas de tempo para os métodos que funcionam muito rapidamente, porque a própria sobrecarga do profiler é significativa nesses casos. Muitos engenheiros não utilizam informações de perfil, porque eles não podem confiar na sua precisão.
A falta de informações de chamada de pilha completa
O segundo problema com os profilers determinísticos internos é que eles não gravam informações completas na pilha de chamadas. Os perfis internos de módulos de informações somente registram informações subindo um nível de pilha, o que limita a utilidade desses módulos. Por exemplo, quando um decorador é aplicado a um grande número de funções, o decorador frequentemente aparece nos receptores e nos chamadores de seções de saída dos perfis, com a informação da chamada verdadeira obscurecida devido a informações da pilha de chamadas achatadas. Essa desordem faz com que seja difícil entender as informações de receptor e de chamador verdadeiras.
Falta de serviços escritos para profiling
Finalmente, os profilers determinísticos internos exigem que o código seja explicitamente instrumentado para criação de perfis. Um problema comum para nós é que muitos serviços não foram escritos com perfis em mente. Sob carga alta, podemos encontrar problemas de desempenho graves com o serviço e pretendemos recolher informações de perfil rapidamente. Desde que o código não esteja instrumentado para profiling, não há nenhuma maneira de começar imediatamente a coleta de informações de perfil. Se a carga é grave o suficiente, podemos precisar de um engenheiro para escrever código para habilitar um profiler determinista (normalmente adicionando um método RPC para ligá-lo e outro para despejar os dados de perfil). Esse código, em seguida, precisa ser revisado, testado e implementado. O ciclo inteiro pode demorar várias horas, o que não é rápido o suficiente para nós.
Profilers de amostragem
Há também uma série de profilers de amostragem de terceiros para Python. Eles normalmente trabalham instalando um temporizador de intervalo POSIX, que interrompe periodicamente o processo e executa um manipulador de sinal para gravar informações de pilha. Profilers de amostragem fazem a amostra do processo perfilado em vez de recolher as informações de perfil determinístico. Essa técnica é eficaz porque a resolução de amostragem pode ser marcada para cima ou para baixo. Quando a resolução de amostragem é alta, os dados de perfil são mais precisos, mas o desempenho é prejudicado. Por exemplo, a resolução de amostragem pode ser definida como alta para obter perfis detalhados com uma correspondente alta quantidade de sobrecarga, ou ela pode ser definida como baixa para obter perfis menos detalhados com menos sobrecarga.
Algumas limitações vêm com profilers de amostragem. Primeiro, eles normalmente vêm com alta sobrecarga porque são implementados em Python. O Python propriamente dito não é rápido, especialmente em comparação com C ou C++. Na verdade, o profiler determinista cProfile é implementado em C por essa razão. Com esses profilers de amostragem, obter um desempenho aceitável muitas vezes significa definir a frequência do temporizador para algo que é relativamente grosseiro.
A outra limitação é que o código precisa ser explicitamente instrumentado para profiling, assim como com profilers deterministas. Portanto, profilers de amostragem existentes levam ao mesmo problema de antes: sob carga alta, queremos o perfil de algum código apenas para perceber que temos de reescrevê-lo em primeiro lugar.
Pyflame ao resgate
Com o Pyflame, queríamos manter todos os benefícios possíveis de perfis:
- Recolher a pilha Python completa, todo o caminho até a sua raiz
- Emitir os dados num formato que pode ser utilizado para gerar um gráfico de chama
- Ter baixa sobrecarga
- Trabalhar com processos não explicitamente instrumentados para profiling
Mais importante, o nosso objetivo é evitar todas as limitações existentes. Pode parecer impossível pedir todos os recursos sem fazer quaisquer sacrifícios. Mas não é tão impossível quanto parece!
Usando ptrace para Python Profiling
A maioria dos sistemas Unix implementa um sistema de rastreio do processo de chamada especial denominado ptrace(2). O ptrace não é parte da especificação POSIX, mas implementações Unix, como BSD, OS X e Linux, fornecem uma implementação ptrace que permite que um processo leia e escreva para endereços de memória virtual arbitrária, leia e escreva registros de CPU, forneça sinais etc. Se você já usou um depurador como o GDB, então já utilizou o software que é implementado usando ptrace.
É possível usar ptrace para implementar um profiler Python. A ideia é unir periodicamente ptrace ao processo, usar a memória de rotinas para obter o rastreamento de pilha Python, e depois separar o processo. Especificamente com Linux ptrace, um profiler pode ser escrito usando os tipos de solicitação PTRACE_ATTACH, PTRACE_PEEKDATA e PTRACE_DETACH. Em teoria, isso é bastante simples. Na prática, é complicado pelo fato de que a recuperação do rastreamento de pilha usando apenas o pedido PTRACE_PEEKDATA é de muito baixo nível e não intuitivo.
Primeiro, vamos brevemente cobrir como a solicitação PTRACE_PEEKDATA funciona no Linux. Esse tipo de solicitação lê dados em um endereço de memória virtual no processo rastreado. A assinatura da chamada de sistema ptrace no Linux se parece com isto:
long ptrace(enum __ptrace_request request, pid_t pid, void *addr, void *data);
Ao usar PTRACE_PEEKDATA, os seguintes argumentos de função são fornecidos:
| Parameter | Value |
| request | PTRACE_PEEKDATA |
| pid | The traced process ID |
| addr | The memory address to read |
| data | Unused (NULL by convention) |
O valor que o ptrace(2) retorna é um long com o endereço de memória. No Linux com o GCC, o tipo long é definido como sendo o mesmo que a arquitetura nativa de tamanho da palavra, então, em um sistema de 32-bits, o valor de retorno é um inteiro de 32 bits assinado, e em um sistema de 64-bits, o valor de retorno é um inteiro de 64 bits assinado.
Há uma complicação adicional aqui. Em caso de erro, o ptrace(2) retorna o valor -1 e seta errno adequadamente. No entanto, os dados no endereço que estamos lendo realmente podem conter o valor -1. Portanto, um valor de retorno de -1 é ambíguo: houve um erro ou esse endereço de memória realmente tinha -1? Para resolver essa ambiguidade na leitura dos dados, é preciso primeiro limpar errno e, em seguida, fazer o pedido ptrace. Então, se o valor de retorno é -1, vamos verificar se errno foi definido durante a chamada ptrace. Curiosamente, a ambiguidade na interpretação do valor de retorno é um artefato do invólucro libc GNU. A chamada de sistema subjacente no Linux usa o valor de retorno para sinalizar um erro, e ele armazena os dados pegos para o campo field, que devem ser fornecidos nesse caso.
Extraindo o estado da thread
Internamente, o Python é estruturado com um ou mais intérpretes independentes, e cada subintérprete acompanha uma ou mais threads. Devido ao bloqueio do intérprete global, apenas uma thread é executada em qualquer momento dado. As informações da thread atualmente em execução são mantidas em uma variável global chamada _PyThreadState_Current, que normalmente não é exportada pela API do Python C. A partir dessa variável, o Pyflame pode encontrar o frame object atual. A partir do quadro atual, todo o rastreamento de pilha pode ser desenrolado. Por conseguinte, uma vez que o Pyflame localiza a posição de memória do _PyThreadState_Current, é possível recuperar o resto da informação pilha usando PTRACE_PEEKDATA, como descrito acima. O Pyflame segue o ponteiro de estado da thread para um frame object, e cada frame object tem um ponteiro de volta para outro frame. O frame final tem um ponteiro de volta para NULL. Cada objeto de frame mantém campos que podem ser usados para recuperar o nome do arquivo, número da linha e nome da função para o frame.
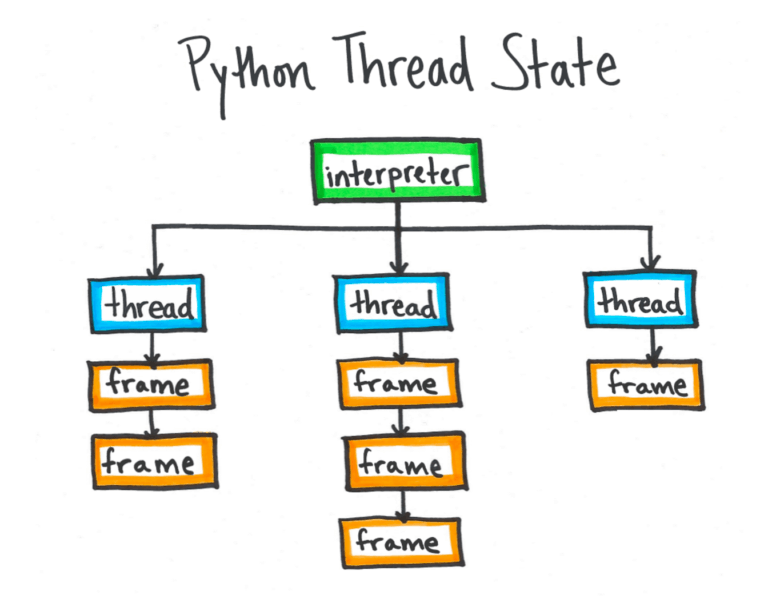 Cada interpretador Python acompanha um ou mais objetos de estado da thread, e cada estado da thread possui um ponteiro para uma lista ligada de frames que representam a pilha de chamadas para essa thread. O símbolo _PyThreadState_Current aponta para a thread ativa.
Cada interpretador Python acompanha um ou mais objetos de estado da thread, e cada estado da thread possui um ponteiro para uma lista ligada de frames que representam a pilha de chamadas para essa thread. O símbolo _PyThreadState_Current aponta para a thread ativa.
A parte mais difícil disso é realmente localizar o endereço do _PyThreadState_Current. Dependendo de como o interpretador foi compilado, existem duas possibilidades:
- No modo de construção padrão, _PyThreadState_Current é um símbolo regular com um endereço bem conhecido na área em que o texto que não se altera. Embora o endereço não seja alterado, o valor real para o endereço depende de que compilador é usado, quais flags de compilação são usadas etc.
- Quando o Python é compilado com -enable-shared, o símbolo _PyThreadState_Current não está incorporado no próprio Python, mas em uma biblioteca dinâmica. Nesse caso, a randomização de espaço do layout de endereço (ASLR) significa que o endereço de memória virtual é diferente cada vez que o interpretador é executado.
Em ambos os casos no Linux, o símbolo pode ser localizado ao analisar as informações ELF do intérprete (ou a partir de libpython em uma compilação dinâmica). Sistemas Linux incluem um arquivo de cabeçalho chamado elf.h que tem as definições necessárias para analisar um arquivo ELF. A memória Pyflame mapeia o arquivo e, em seguida, usa essas definições struct ELF para analisar as estruturas ELF relevantes. Se a seção especial ELF .dynamic indica que as ligações de construção são contra libpython, então o Pyflame passa a analisar esse arquivo. Em seguida, localiza o símbolo _PyThreadState_Current na seção ELF .dynsym, quer a partir do Python executável em si ou de libpython, dependendo do modo de construção.
Para builds Python dinâmicos, o endereço do _PyThreadState_Current tem que ser aumentado com o offset ASLR. Isto é feito lendo /proc/PID/maps para obter os deslocamentos de mapeamento de memória virtual para o processo. O deslocamento desse arquivo é adicionado ao valor lido a partir do libpython para obter o endereço de memória virtual verdadeiro para o símbolo.
Interpretando o frame data
No código-fonte para o interpretador Python, você vê a sintaxe regular de C para referência aos ponteiros e acesso a campos de struct:
// frame has type void* void *f_code = (struct _frame*)frame->f_code; void *co_filename = (PyCodeObject*)f_code->co_filename;
Em vez disso, o Pyflame tem que usar ptrace para ler a partir do espaço de memória virtual do processo de Python e implementar manualmente o ponteiro dereferencing. O que se segue é um trecho representativo do código do Pyflame que emula o código na listagem de código anterior:
const long f_code = PtracePeek(pid, frame + offsetof<(_frame, f_code));
const long co_filename =
PtracePeek(pid, f_code + offsetof(PyCodeObject, co_filename));
Aqui, um método auxiliar chamado PtracePeek() implementa a chamada para ptrace com o parâmetro PTRACE_PEEKDATA e lida com a verificação de erros. Os ponteiros são representados como longs sem sinal, e a macro offsetof é usada para calcular struct offsets. O código ptrace em Pyflame é mais detalhado do que o código C regular, mas a estrutura lógica das duas listagens de código é exatamente a mesma.
O código para realmente extrair nomes e números de linha é interessante. O Python 2 armazena nomes de arquivos usando um tipo chamado PyStringObject, que simplesmente armazena a linha de dados da string (em um deslocamento fixo a partir do cabeçalho do struct). O Python 3 tem uma manipulação muito mais complicada da string devido à unificação interna do tipo de string e tipos de Unicode. Para strings que contêm apenas dados ASCII, os dados de string bruta podem ser encontrados em linha na estrutura da mesma forma. O Pyflame atualmente só suporta todos os nomes de arquivos ASCII no Python 3.
Implementar o número da linha de decodificação para o Pyflame foi uma das partes mais difíceis de desenvolver o Pyflame. O Python armazena os dados do número da linha em uma estrutura de dados interessante chamada “line number table”, em um campo no objeto de código chamado f_lnotab. Há um arquivo chamado lnotab_notes.txt no código-fonte do Python que explica a estrutura de dados exata. Primeiro, saiba que o interpretador Python funciona convertendo o código Python regular para uma representação bytecode de nível inferior. Normalmente, uma linha de código Python se expande para muitas instruções de bytecode. Instruções de bytecode, portanto, tipicamente avançam muito mais rapidamente do que linhas de código. Em vez de armazenar e atualizar um campo de número de linha em cada frame, o interpretador Python usa uma estrutura de dados comprimidos que associa offsets bytecode para alinhar as compensações numéricas. A estrutura de dados bytecode-para-número-de-linha é calculada uma vez para cada código de objeto. O número de linha pode ser calculado implicitamente para qualquer instrução bytecode.
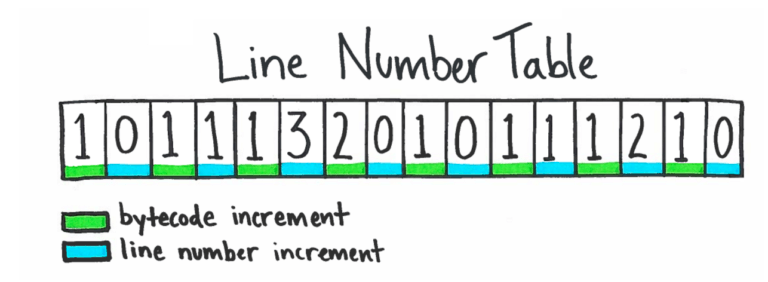 A tabela de número da linha é um array com incrementos de bytecode e o número da linha intercalados. O número da linha para um determinado endereço de bytecode é calculado mantendo uma soma de ambos os incrementos de bytecode e incrementos do número da linha e parando no endereço desejado.
A tabela de número da linha é um array com incrementos de bytecode e o número da linha intercalados. O número da linha para um determinado endereço de bytecode é calculado mantendo uma soma de ambos os incrementos de bytecode e incrementos do número da linha e parando no endereço desejado.
Representando serviços dockerizados/containers
No Uber, executamos a maioria dos nossos serviços em containers Linux usando Docker. Um dos desafios interessantes da construção do Pyflame foi fazê-lo funcionar com containers Linux. Normalmente, os processos no host não podem interagir com os processos em container. No entanto, na maioria dos casos, o usuário root pode usar ptrace em processos de container, e é assim que nós usamos o Pyflame em produção no Uber.
Containers Docker usam mount namespaces para isolar os recursos do sistema de arquivos entre o host e o container. O Pyflame tem que acessar os arquivos dentro do container para acessar o arquivo ELF correto e calcular deslocamentos de símbolos. O Pyflame coloca os containers mount namespaces utilizando as chamadas setns(2) de sistema. Em primeiro lugar, Pyflame compara /proc/self/ns/fs com /proc/PID/ns/fs. Se eles diferem, o Pyflame coloca namespace de montagem do processo, chamando open(2) no /proc/PID/ns/fs e, em seguida, chamando setns(2) no descritor de arquivo resultante. Ao reter um descritor de arquivo aberto no original /proc/self/ns/fs, o Pyflame pode, posteriormente, retornar ao seu namespace original (isto é, escapar do container).
Exprimente o Pyflame
Achamos que o Pyflame é uma ferramenta extremamente útil para os perfis do código Python no Uber e para encontrar caminhos de código ineficientes para otimizar. Lançamos o Pyflame como software livre, sob a licença Apache 2.0. Por favor, experimente-o e nos deixe saber se você encontrar quaisquer erros. E, como sempre, adoramos receber pull requests, então por favor pode enviar se você tem melhorias.
***
Este artigo é do Uber Engineering. Ele foi escrito por Evan Klitzke. A tradução foi feita pela Redação iMasters com autorização. Você pode conferir o original em: https://eng.uber.com/pyflame/.

De 0 a 10, o quanto você recomendaria este artigo para um amigo?