

No artigo de hoje, vou mostrar como podemos realizar o tratamento do código HTML obtido a partir de uma web page realizando tarefas como obter o HTML, converter para texto, extrair links e extrair imagens. Vamos usar os recursos da classe WebClient e expressões regulares via classe Regex.
Obtendo informações da web
A plataforma .NET fornece duas classes presentes no namespace System.NET que podemos usar para podermos interagir diretamente com servidores usando HTTP. São elas:
- WebRequest – Realiza uma requisição para uma URI – Uniform Resource Identifier;
- WebResponse – Fornece uma resposta a partir de uma URI – Uniform Resource Identifier.
Para podermos usar os recursos da classe WebRequest podemos usar as classes HttpWebRequest e HttpWebResponse que fornecem implementações específicas destas classes.
Dessa forma, a classe HttpWebRequest fornece suporte para as propriedades e métodos definidos na classe WebRequest e para propriedades e métodos adicionais que permitem interagir usando o protocolo HTTP.
- O método Create() de uma instância da classe WebRequest para iniciar os objetos HttpWebRequest;
- O método GetResponse() realiza uma requisição síncrona através da propriedade RequestUri, retornando um objeto HttpWebResponse contendo a resposta de uma requisição;
- O método GetRequestStream() obtém um objeto stream usado para escrever os dados da requisição.
Usando estas duas classes, temos tudo que precisamos para fazer o download de uma página web completa em um stream ou postar dados para uma URL.
Expressões regulares
A plataforma .NET vem com um poderoso mecanismo de expressões regulares que é acessível a qualquer linguagem da plataforma: VB .NET, C# etc.
Uma expressão regular ou regex para simplificar, é um modelo que descreve uma certa quantidade de texto. A expressão regular mais simples consiste de um único caractere. Ex: a. Este padrão irá coincidir com a primeira ocorrência do caractere em uma string. Se a string for “Isto é apenas um teste”, a primeira ocorrência será a letra a antes da letra p (de apenas).
As expressões regulares possuem 11 caracteres especiais conhecidos como meta caracteres. São eles:
[ , \ , ^ , $ , . , | , ? , * , + , { , }
Para usar qualquer um destes caracteres como um literal em uma expressão regular, temos que usar um caractere de escape (\). Assim, se você deseja escrever 1+1=2 deverá usar 1 \+ 1=2. De outra forma, o caractere + terá um significado especial.
Regex é a classe mais importante deste grupo e qualquer código para um expressão regular instancia pelo menos um objeto desta classe (ou usar um dos métodos estáticos da classe Regex). Você instancia este objeto passando o padrão de critério escrito no formato especial da linguagem usada para expressão regulares. No exemplo a seguir, a expressão regular define qualquer grupo de dois caracteres consistindo de uma vogal seguida por um dígito:
Dim re As New Regex(“[aeiou\d”)
O método de localização do objeto Regex aplica a expressão regular à string passada como argumento; e retorna um objeto do tipo MatchCollection, uma coleção somente-leitura que representa todas as ocorrências coincidentes com o critério usado.
A classe Regex representa o mecanismo para tratar as expressões regulares na plataforma .NET. Ela pode ser usada para analisar rapidamente grandes quantidades de texto para encontrar padrões de caracteres específicos; para extrair, editar, substituir ou excluir substrings de texto, ou para adicionar as strings extraídas a uma coleção para gerar um relatório.
Para usar as expressões regulares, definimos o padrão desejado para identificar em um fluxo de texto usando a sintaxe documentada nos elementos de linguagem das expressões regulares. A seguir, instanciamos um objeto Regex. Finalmente executamos alguma operação, como a substituição de texto que corresponda ao padrão de expressão regular, ou a identificação de um padrão coincidente.
A enumeração RegexOptions fornece valores enumerados para usar para definir opções de expressões regulares. Os valores possíveis são:
| Valor | Descrição |
| None | Especifica que nenhuma opção foi definida |
| IgnoreCase | Especifica a comparação case-sensitive |
| ExplicitCapture | Especifica que as únicas capturas válidas são explicitamente nomeadas ou grupos numerados do formulário (? <name> …). Isso permite que os parênteses sem nome atuem como grupos de não captura, sem a deselegância sintática da expressão (:? …). |
| Singleline | Especifica modo linha-única. Muda o significado do ponto (.) Para que coincida com todos os caracteres (em vez de cada caractere, exceto \ n). |
| IgnorePatternWhitespace | Elimina espaços em branco sem escape do padrão e permite comentários marcados com #. No entanto, o valor IgnorePatternWhitespace não afeta ou elimina o espaço em branco nas classes de caracteres. |
| ECMAScript | Permite o comportamento compatível com ECMAScript para a expressão. Este valor pode ser usado apenas em conjunto com os valores IgnoreCase, Multiline, e Compiled. A utilização deste valor com quaisquer outros valores gera uma excepção. |
| CultureInvariant | Especifica que as diferenças culturais na linguagem será ignorada. |
| Compiled | Especifica que a expressão regular é compilada para um assembly. Isto obtém um rendimento melhor na execução, mas aumenta o tempo de inicialização. Este valor não deve ser atribuído à propriedade Opções ao chamar o método CompileToAssembly. |
| Multiline | Modo multilinha. Altera o significado de ^ e $ para que eles correspondam ao início e final, respectivamente, de qualquer linha, e não apenas o início e o fim de toda a cadeia. |
| RightToLeft | Especifica que a pesquisa será da direita para a esquerda em vez de da esquerda para a direita. |
Recursos usados: Visual Studio 2013 Express for Windows Desktop
Criando o projeto no VS 2013 Express Edition
Abra o VS 2013 Express for Windows desktop e clique em New Project. A seguir, selecione Visual Basic -> Windows Forms Application.
Informe o nome Tratando_HTML e clique no botão OK.
A seguir, a partir da ToolBox inclua os seguintes controles no formulário do projeto:
- 1 TextBox – txtURL
- 1 Button – btnHTML
- 1 TextBox – txtHTML , Multiline = True , ScrollBars =Both
- 1 Button – btnHTML_Texto
- 1 TextBox – txtTexto , Multiline = True, ScrollBars =Both
Disponha os controles no formulário conforme o leiaute da figura abaixo:
1. Obtendo código HTML e convertendo para texto
O objetivo é obter código HTML de uma URL informada e, em seguida, converter o código HTML para texto.
Os namespaces usados são:
Imports System.Text Imports System.Text.RegularExpressions
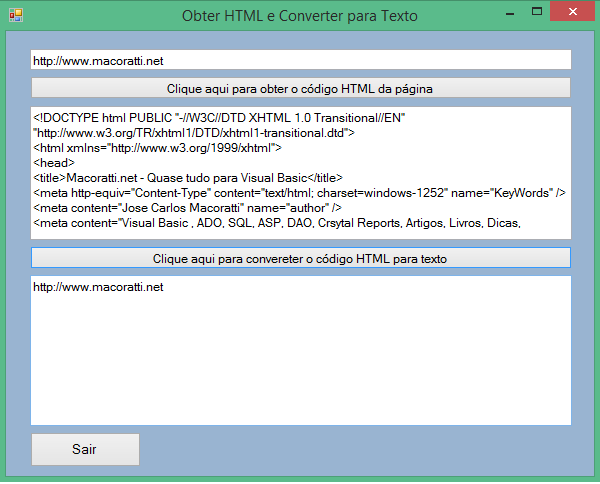
O HTML é obtido da URL usando o método DownloadData:
UTF8Encoding().GetString(objWC.DownloadData(URL))
A conversão do HTML para texto é feito via expressões regulares:
objRegEx.Replace(HTML, "<[^>]*>", "")
O código do projeto é exibido abaixo:
Private Sub btnHTML_Click(sender As Object, e As EventArgs) Handles btnHTML.Click
Try
txtHTML.Text = pegaHTML(txtURL.Text)
Catch ex As Exception
MessageBox.Show(" Erro : " + ex.Message, "Erro", MessageBoxButtons.OK, MessageBoxIcon.Error)
End Try
End Sub
Private Sub btnHTML_Texto_Click(sender As Object, e As EventArgs) Handles btnHTML_Texto.Click
Try
txtTexto.Text = removeTags(txtURL.Text)
Catch ex As Exception
MessageBox.Show(" Erro : " + ex.Message, "Erro", MessageBoxButtons.OK, MessageBoxIcon.Error)
End Try
End Sub
Public Function removeTags(ByVal HTML As String) As String
Try
'Remove as tags do HTML
Return Regex.Replace(HTML, "<[^>]*>", "")
Catch ex As Exception
MessageBox.Show(" Erro : " + ex.Message, "Erro", MessageBoxButtons.OK, MessageBoxIcon.Error)
End Try
End Function
Public Function pegaHTML(ByVal URL As String) As String
' Retorna o HTML da URL informada
Dim objWC As New System.Net.WebClient
Return New UTF8Encoding().GetString(objWC.DownloadData(URL))
End Function
Estamos usando dois métodos :
- removeTags(HTML) – remove as tags do HTML
- pegaHTML(URL) – retorna o HTML para a URL informada
Executando o projeto obtemos:
Fica como tarefa para você realizar um ajuste mais fino na conversão do código HTML para texto usando as expressões regulares.
Na segunda parte do artigo eu vou mostrar com podemos extrair links e imagens do código HTML usando expressões regulares.
Pegue a primeira parte do projeto aqui: WebBrowser_1.zip

De 0 a 10, o quanto você recomendaria este artigo para um amigo?