

Este artigo é baseado na palestra “Estrutura física e fragmentação – quando e por que desfragmentar tabelas e índices”, que apresentei aos colegas DBAs da empresa RAIZEN em março do ano passado.
Na primeira parte do artigo, eu apresento detalhes das estruturas física e lógica associadas aos bancos de dados do SQL Server. Desta vez, eu usarei estes conceitos para mostrar como funcionam os índices, o que causa sua fragmentação e como minimizar este problema, que é um dos maiores causadores de degradação de performance do banco.
Índices clusterizados, não-clusterizados e heaps
Quando criamos uma tabela, as páginas de dados não têm nenhuma sequência definida para armazenamento dos dados. Os registros serão gravados na ordem em que são inseridos. Quando ocorre esta situação, estas páginas não indexadas são chamadas de pilhas ou “heaps”.
Porém, o uso de heaps traz um inconveniente: quando precisarmos localizar registros específicos da tabela, o otimizador terá que varrer todas as páginas de dados para identificar quem atende os critérios da sua pesquisa. Esta operação é conhecida como “table scan”. Evidentemente, isso leva tempo para ser executado e, no caso de tabelas grandes, tem um impacto sério na performance.
Então, alguém teve a ideia de criar índices (não-clusterizados), que são como catálogos que relacionam os valores de um ou mais campos da tabela com a página de dados – onde existe um registro com este valor. A estrutura mais comum usada pelos índices é conhecida como B-tree (que falaremos a seguir). Graças a esta estrutura, o otimizador de consultas localiza rapidamente quais páginas de dados devem ser lidas.
Mais tarde alguém teve uma ideia ainda melhor: por que não armazenar registros nas páginas de dados de forma ordenada com base em um ou mais campos da planilha? Assim, as próprias páginas de dados da tabela funcionariam como um índice. Esta é a ideia do índice clusterizado, um componente essencial na arquitetura de dados do SQL Server.
Índices clusterizados também costumam usar a estrutura B-tree (a menos que se use o recurso dos índices clusterizados columnstore, disponíveis a partir do SQL Server 2014). Porém, eles têm uma peculiaridade importante: o nível mais detalhado da estrutura, chamado de “folha” é composto pelas próprias páginas de dados da tabela, ordenadas conforme a definição do índice. Veja o diagrama a seguir.
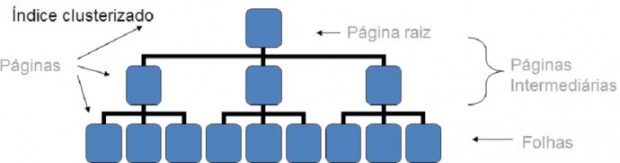
‘Quando existe o índice clusterizado, todos os demais índices da tabela se aproveitam da ordenação das páginas de dados, melhorando ainda mais sua eficiência. A existência deste índice é tão importante na arquitetura do SQL Server que a MICROSOFT definiu que, por default, o campo considerado chave primária da tabela teria automaticamente um índice clusterizado associado a ele.
Inserindo registros nas páginas de dados
Quando inserimos um novo registro numa tabela, o SQL SERVER vai procurar a página de dados ativa e verificar se existe espaço suficiente para armazenar o registro. O diagrama a seguir esboça esta ideia de forma simplificada e didática. Na prática, os registros não são necessariamente gravados dentro da página de forma contínua e sequencial, como sugere o esquema abaixo.
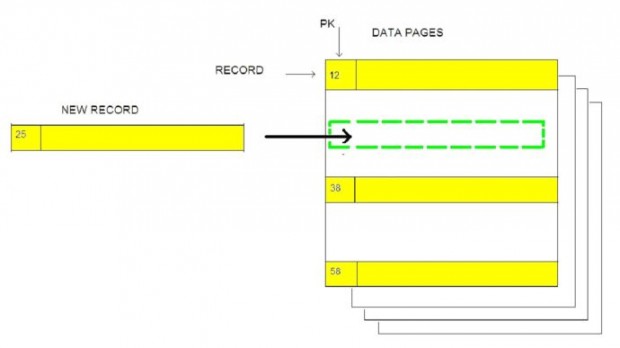
No diagrama, a tabela tem uma chave primária no primeiro campo (identificado como PK). Consequentemente, tem um índice clusterizado nesta coluna, que obriga que os registros sejam gravados nas páginas de dados de forma ordenada, conforme os valores deste campo PK.
Sendo assim, o novo registro (PK=25) tem que ser inserido na mesma página que tem os registros com os valores 12 e 38. Se o registro não couber na página atual, o SQL Server quebrará a página atual em duas (page split) para manter a ordenação exigida.
Quando acontece o page split, o SGBD ativa a próxima página vazia disponível na extensão e, em seguida, transfere aproximadamente metade destes registros para a nova página. Depois, finalmente, o novo registro será escrito nesta página. Se não houver páginas vazias nesta extensão, o SGBD partirá para a próxima extensão. E se não houver nenhuma extensão vazia, acontecerá o “AutoGrowth” do banco, ou seja, o SGBD vai alocar novas porções de disco e organizá-las em segmentos de 64Kbytes (lembre-se que são sempre 8 páginas de 8Kbytes).
Lógico que todas estas ações tomam um tempo enorme para serem executadas. E, além disso, existe outra questão: depois deste evento, teremos duas páginas com aproximadamente 50% de espaço praticamente “desperdiçado”.
Portanto, eventos envolvendo page split são extremamente indesejáveis e causam diversos problemas, como lentidão e crescimento desnecessário do banco, por exemplo.
Hora de falar do FILL FACTOR
Para minimizar a ocorrência de page split em casos críticos, o SQL Server dispõe do parâmetro “FILLFACTOR”. Ele funciona como um fator de segurança no preenchimento das páginas de dados. Ou seja, quando a página chegar ao nível de X% de ocupação (número definido no FILLFACTOR), o SGBD passará a usar uma nova página de dados.
Isso garante que as páginas de dados terão uma margem de segurança para inserção/alteração de registros, reduzindo a chance de ocorrência de page split durante a inserção de um novo registro. Por exemplo, se o FILLFACTOR definido para uma tabela for de 90%, as páginas de dados dessa tabela vão reservar 10% do espaço para eventuais manutenções futuras.
É preciso lembrar que esta estratégia traz efeitos colaterais óbvios. O primeiro deles é que cada página de dados vai deixar uma porção do disco reservada (mas não utilizada). Portanto, seu banco de dados vai precisar de mais espaço em disco, o buffer de memória vai desperdiçar espaço para carregar a página de dados inteira e assim por diante… Como diz Kendra Little, o uso do FILLFACTOR requer um “equilíbrio delicado”, porque ele pode resolver o problema de page split, mas se for mal definido pode causar problemas ainda maiores.
Tendo isso em mente, é preciso observar algumas peculiaridades do FILLFACTOR: ao contrário do que se pode imaginar, ele não se aplica a tabelas, mas sim a índices, clusterizados ou não-clusterizados. Tradução: não se pode aplicar o fator de preenchimento numa tabela se ela for composta de heaps; é necessário que ela tenha um índice clusterizado.
O valor default do FILLFACTOR quando se instala uma nova instância do SQL Server é zero, que significa 100% de ocupação da página (0 ou 100 trazem o mesmo resultado, neste caso). A Microsoft é bastante cautelosa sobre o uso deste parâmetro e, portanto, não é recomendável alterar este valor default. A ideia do FILLFACTOR é de usá-lo em situações críticas e não como um parâmetro aplicado a todos os objetos do banco.
O mais indicado é identificar índices que tenham problemas críticos com fragmentação (que veremos a seguir) e reconstruir estes índices usando o valor mais adequado.
ALTER INDEX [NomeIndice] ON [NomeTabela]
REBUILD WITH (FILLFACTOR = {ValorDesejado} );
Não é tarefa simples escolher um novo valor de FILLFACTOR. Em muitos casos, é um processo de tentativa e erro até que se chegue num valor que de fato se verifique melhoria de performance do banco. Pinal Dave recomenda um critério de escolha do FILLFACTOR com base no nível de atividade no índice, com valores que variam entre 70 e 100%, conforme o caso.
O que é fragmentação
Fragmentação é o resultado de qualquer processo que altere a ordenação física dos registros dentro de cada página ou que aumente desnecessariamente a quantidade de páginas do índice.
Quando acontece o primeiro caso, os registros deixam de ser escritos em segmentos contínuos do disco e isso é chamado de fragmentação interna. O segundo caso é quando acontece, por exemplo, o page split. Esse caso é conhecido como fragmentação externa. Em qualquer dos casos, teremos queda de performance do banco de dados, já que o SGBD fará mais esforço para executar as mesmas operações.
Em termos de linguagem SQL, a fragmentação é causada por operações de UPDATE, DELETE. Com frequência menor, as operações de INSERT também podem causar fragmentação, mas isso acontece em situações especiais. Por exemplo, no caso de INSERT em tabelas que tenham índice clusterizado definido sobre campos não sequenciais.
Fragmentação e fluxo de informação
Estratégias inadequadas em relação ao fluxo de informação do sistema costumam levar à necessidade de execução de diversos UPDATEs e/ou DELETEs nas tabelas do banco. Evidentemente esta situação vai impactar na fragmentação da tabela.
A situação será tanto pior quanto maior o nível de atividade desta tabela, pois a fragmentação vai crescer a cada nova operação. A tendência neste cenário é que rapidamente a tabela alcance níveis de fragmentação muito altos, exigindo a ação dos DBAs.
Fragmentação e o tamanho dos registros
Outro fator agravante é o tamanho médio dos registros da tabela. Lembre-se que as páginas de dados no SQL Server têm sempre 8 Kbytes. Se o tamanho médio dos registros for de 1 Kbyte, por exemplo, na melhor de todas as hipóteses vão caber 8 registros por página de dados. E claro que a probabilidade de acontecer page split durante a operação do banco aumenta dramaticamente.
Fragmentação e estratégia de indexação
Pode até parecer um contrassenso dizer que a estratégia de indexação afeta fragmentação. Mas isso acontece.
Quando temos uma tabela cujo índice principal (o índice clusterizado) se fragmenta muito rapidamente, muito provavelmente todos os índices desta tabela sofrerão com o mesmo problema. Não adianta criar um monte de índices para tentar escapar do problema.
Aliás, existem muitos casos em que a indexação excessiva causa um problema maior do que a inexistência de índices. Pense bem: índices são úteis nas operações de SELECT, mas eles precisam ser atualizados a cada operação de INSERT, UPDATE ou DELETE. Portanto, quanto mais índices existirem na tabela, mais o tempo será gasto em cada operação de INSERT, UPDATE ou DELETE.
Fragmentação e modelo de dados
Muitas vezes, as manutenções para reconstrução de índices são feitas online, com a base em operação. Porém, esta operação não é permitida caso a tabela indexada contenha campos do tipo LOB (Large OBject). É neste ponto que o modelo de dados afeta a fragmentação: dependendo da estrutura lógica da tabela, não é possível sanear o problema de fragmentação com a base online.
Esta questão do modelo de dados é frequentemente esquecida, causando problemas para administração do banco a partir do momento em que ele entra em operação.
Em minha opinião, não é uma boa ideia incluir campos LOB em tabelas transacionais. Quando é necessário usar campos com os tipos de dados IMAGE, TEXT, NTEXT, VARBINARY(MAX), XML, VARCHAR(MAX) e NVARCHAR(MAX), eu prefiro criar uma tabela auxiliar associada à tabela mãe. Assim, operações como UPDATE não afetarão a tabela auxiliar.
Fragmentação versus FILLFACTOR
Considerando estas definições, concluímos que o uso do FILLFACTOR citado acima causa intencionalmente a fragmentação externa. Ele reserva espaço na página para uso futuro e, assim, aumenta a quantidade de páginas necessárias para armazenar dados.
Observe que o FILLFACTOR sacrifica um pouco a performance para minimizar a ocorrência de eventos que possam causar uma queda de performance ainda maior. Portanto, mais uma vez, deve-se ter muito cuidado no uso deste parâmetro.
Recomendações
Questões de indexação e fragmentação não são assuntos para começarem a ser avaliados quando a base chega à produção.
Isso deve ser pensado desde a definição do modelo de banco de dados. Coisas elementares, como tipos de dados ou o tamanho dos registros serão importantes para boa operação de seu banco.
Tenha isso em mente quando começar a criação do seu próximo banco de dados.
No próximo artigo apresentarei recursos para identificar propriedades físicas dos índices e técnicas de desfragmentação.
Leituras sugeridas
- How Does SQL Server Store Data? por Brent Ozar
- 5 Things About FILLFACTOR por Kendra Little
- What is the Best Value for the Fill Factor? Index, Fill Factor and Performance, Part 2 por Pival Dave
- Types of Indexes por MSDN
- SQL SERVER – Fragmentation por Pinal Dave
- SQL Server Index Fragmentation, Types and Solutions Pankaj Mittal
- Reorganizing and Rebuilding Indexes por MICROSOFT TECHNET
- A SQL Server DBA myth a day: (29/30) fixing heap fragmentation por Paul Randall
- When a Delete isn’t Really a Delete… por Paul Randall

De 0 a 10, o quanto você recomendaria este artigo para um amigo?