

Este artigo é baseado na palestra “Estrutura Física e Fragmentação – Quando e Porquê Desfragmentar Tabelas e Índices”, que apresentei aos colegas DBAs da empresa RAIZEN em março deste ano.
Introdução
Quando trabalhamos com bancos de dados, é importante entendermos os conceitos lógicos (como tabelas e registros) e os conceitos físicos (como alocação de disco, buffers de memória etc) envolvidos. Porém, nem sempre temos consciência da interação que acontece entre eles. E este entendimento é essencial para garantir a boa performance de um banco de dados.
Nesta primeira parte do artigo, eu apresento alguns detalhes das estruturas física e lógica de bancos de dados do SQL Server. Na segunda parte, mostrarei como estes conceitos influenciam a fragmentação de índices, um conhecido vilão que degrada performance das consultas.
Estruturas lógicas e físicas
Quando pensamos em dados armazenados em qualquer SGDB relacional, instintivamente pensamos em registros gravados em tabelas. Porém estes são conceitos lógicos e têm pouco a ver com a forma como estes dados estão gravados fisicamente.
A partir daqui precisamos detalhar as coisas e entender a interação entre aspectos lógicos e aspectos físicos do nosso banco.
Registros são associados a tabelas e o relacionamento entre as tabelas é que define o seu modelo lógico do banco de dados. Registros, tabelas e relacionamentos são provavelmente os conceitos lógicos mais conhecidos nos SGBDs relacionais. Mas vejamos a operação física envolvida na busca de registros de uma única tabela para entendermos os demais conceitos:
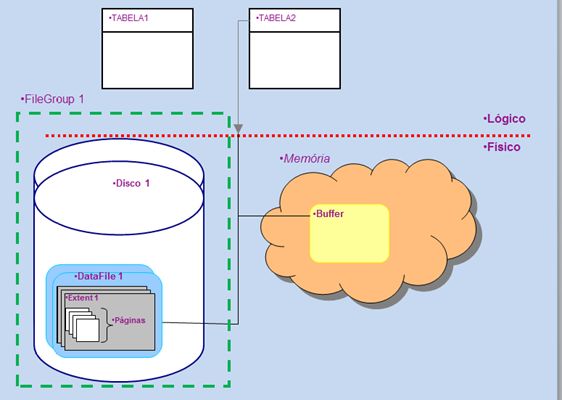
Filegroup
Quando lemos dados da tabela Tabela2, o SGBD precisa primeiramente identificar o filegroup a que ela está associada. Este é um conceito lógico que informa onde serão gravados os dados de uma ou mais tabelas.
O filegroup do SQL Server é o conceito mais próximo que temos da ideia de tablespace, usada em outros SGBDs (DB2, ORACLE, POSTGRES, SYBASE, etc).
A diferença principal entre tablespaces e filegroups é que este último se associa apenas a arquivos de dados (os datafiles) e não a porções de memória (os bufferpools).
Na prática, não existe restrição para a quantidade de tabelas associadas a um mesmo filegroup. Podemos associar centenas de tabelas pequenas a um único filegroup. Em contrapartida, uma tabela muito grande que seja particionada terá ao menos um filegroup associado a cada partição.
Eu costumo implementar bases de dados com, no mínimo, dois filegroups: o default, PRIMARY, reservado para tabelas e um segundo filegroup reservado para índices.
Mas é preciso cuidado, porque a associação entre a tabela e o filegroup é permanente. Se for necessário mover a tabela para outro filegroup, terá que ser criada uma nova tabela e os dados movimentados entre a tabela velha e a nova.
Datafile
É um arquivo de dados associado a um filegroup. Um datafile pode conter dados de N tabelas, desde que todas elas estejam vinculadas ao mesmo filegroup. O administrador não tem controle sobre quais datafiles serão usados para armazenar os dados de uma tabela, pois isso é administrado pelo próprio SGBD.
Novos datafiles podem ser criados em um filegroup a qualquer momento, ou seja, sempre que o espaço livre nos datafiles passe o limite de segurança adotado (geralmente entre 80% e 90% de ocupação do datafile). E este novo datafile pode ser alocado em qualquer disco do servidor.
Já vi bases com todo tipo de estratégia de gerenciamento de datafiles: as que usam um datafile por filegroup e as que usam dezenas de datafiles por filegroup. Eu entendo que os dois extremos são problemáticos, porque um número muito grande de filegroups vai ser tão difícil de gerenciar quanto um número muito grande de datafiles.
Sempre que possível, é interessante manter as quantidades de filegroups e datafiles no menor número possível. Mas aí entramos em outro problema: qual o tamanho máximo recomendável para um datafile? Esta é realmente uma questão em aberto. Eu nunca encontrei documentação oficial da Microsoft recomendando o tamanho máximo de datafile para cada versão de SQL e/ou versão do Windows. Este número pode variar segundo vários fatores, por exemplo, o tamanho dos discos usados, tipo de dispositivo de storage, versão de sistema operacional etc.
Na empresa onde trabalho nós adotamos o limite arbitrário de 32GB por datafile. Como costumamos usar discos de 200 Gb ou mais, isso nos dá uma boa versatilidade para alocação de novas bases.
Disco
Na realidade, não há nenhum vínculo formal entre o SQL Server e os discos do seu servidor. Os discos em si podem ser usados para qualquer coisa, conforme sua conveniência. A vinculação dos discos com o SQL se restringe aos datafiles.
Claro que a escolha do tipo de disco usado influencia a boa operação do banco. Discos com alta capacidade de escrita são indicados para arquivos de log ou datafiles que recebem muitas transações, já que ambos os casos têm níveis altos de inserção de dados. Discos com alta capacidade de leitura devem ser usados para discos de índices ou dados de aplicações de BI, por exemplo.
Existe uma gama enorme de opções de discos disponíveis no mercado, com preços muito diferentes. Mas o dinheiro não é tudo nesta história. É muito importante conciliar as características do disco com as características do seu servidor e também dos tipos de arquivo que usarão estes discos.
Extensão
É a menor porção de disco que pode ser reservada pelo SQL Server, com tamanho fixo de 64 Kb. Cada vez que um datafile precisa crescer, o SQL Server verifica o tamanho do parâmetro “AUTOGROWTH” (número normalmente expresso em megabytes ou em percentual do tamanho do datafile). E em seguida calcula quantas extensões de 64 Kb serão reservadas no disco.
Extensões são chamadas de uniformes ou mistas, dependendo se estão vinculadas a uma ou mais tabelas.
Página de dados
A págian de dados é uma área de 8 Kb vinculada a uma tabela específica – um conjunto de 8 páginas forma 1 extensão. A página é onde de fato se armazenam os dados.
Cada página é reservada para uma única tabela e cada registro deve ser gravado obrigatoriamente dentro da mesma página. Essa é uma característica muito importante para entender os problemas de divisão de páginas (ou “page split”) e fragmentação, que serão discutidos ao longo destes artigos.
Observação 01: No caso de registros com campos LOB (varchar(8000), varchar(max), varbinary, etc), o armazenamento é um pouco diferente, mas não tratarei desta questão aqui, já que o assunto requer um artigo específico sobre tema.
O esquema abaixo foi apresentado num artigo de Paul Randall e mostra didaticamente como a página de dados é preenchida. Ela sempre tem um cabeçalho de 96 Bytes, a área de gravação de dados e o slot array, que é uma espécie de mapa.
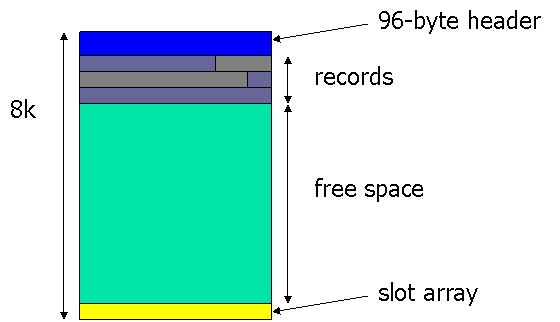
Na prática, a área de gravação não é homogênea como se vê neste esquema. Os espaços ocupados por cada um dos registros não são necessariamente contínuos e se misturam os espaços ocupados por registros e os espaços livres. Quem informa exatamente em que posição física do disco se encontra determinado registro é o slot array (o tal mapa que eu havia mencionado).
Memória
Evidente que memória é um componente essencial para operação do SGBD, mas o gerenciamento da memória do SQL Server não reserva porções específicas para cada filegroup.
No SQL Server, gerenciamento de memória oferece ao DBA poucas opções de configuração. Isso costuma assustar profissionais habituados com SGBDs que rodam em UNIX, pois praticamente tudo em matéria de memória é gerenciado pelo próprio SGBD.
O gerenciamento de memória do SQL Server melhorou muito nos últimos 10 ou 15 anos, mas eu tenho a sensação que a própria Microsoft incentiva a postura do “instale o máximo de memória que puder e deixe o resto pro SGBD”.
Acredito que a maior novidade ocorrida em matéria de gerenciamento seja a opção da inclusão das “extensões de buffer” do SQL Server 2014. Ela permite que DBA apresente discos SSD como parte do cache do SGBD.
Escrevendo no disco
Como se sabe, quando executamos uma operação de INSERT, os registros não são gravados em disco logo depois do “COMMIT”. A operação passa por um longo caminho pelo Log de Transações até finalmente ser gravado no banco de dados (existem artigos muito bons sobre esta questão na própria MICROSOFT TECHNET).
Quando os registros forem gravados na página de dados, eles ocuparão a área clara do diagrama acima. Se acontecer de um ou mais registros não caberem nesta página de dados, será usada uma nova página da extensão em uso. Isso é conhecido como “page split” e quando acontece, é um processo natural dentro do banco, mas obviamente ele consome mais tempo que uma operação de escrita normal. Mas a situação piora quando a 8ª página da última extensão do datafile fica lotada.
Neste caso, o datafile não tem mais nenhum espaço reservado em disco. Então, antes que possa ocorrer o page split, o SQL Server tentará executar a operação de AUTOGROWTH (caso esta opção esteja habilitada), preparando a área de disco no tamanho especificado e organizando as extensões e páginas que couberem nesta área. É lógico que este processo todo é muito lento.
Só depois de todas estas operações que os dados são gravados na página de dados, garantindo de fato a “durabilidade” da transação (o “D” da sigla “ACID”).
Cenários mais nebulosos
Não é preciso ter muita imaginação para piorar muito este cenário de page split que requer crescimento do datafile.
Considere que sua transação com um único INSERT (vamos chamá-la de T1) disparou o page split. Imagine que uma segunda transação (T2) executou várias operações até que chegou num UPDATE que envolvia um registro armazenado na página de dados que estava sofrendo a divisão.
Como esta página de dados está bloqueada (“lock”) pela transação T1, a transação T2 e todos os locks que ela gerou permanecerão na fila aguardando o COMMIT da transação T1.
Quando acontece um cenário desses, é bastante provável que os usuários comecem a reclamar de lentidão no banco de dados.
Recomendações
Para evitar estas situações, existem diversas ações preventivas, mas eu acho importante destacar três delas:
- Sobre a configuração do banco: verifique o nível de isolamento de transações que seja mais adequado para a sua aplicação; alguns isolamentos mais restritivos causam uma infinidade de bloqueios e isso afeta terrivelmente as operações concorrentes;
- Sobre a programação do banco: evite transações muito longas; elas podem manter objetos bloqueados por muito tempo, causando enfileiramento de transações e, consequentemente, lentidão;
- Sobre uso dos discos: a opção AUTOGROWTH é de extrema importância e merece mais atenção dos DBAs. Não basta ativá-la; é preciso estudar qual é o tamanho de crescimento de arquivos mais adequado para seu banco de dados.
A questão do tamanho de incremento dos arquivos no AUTOGROWTH muitas vezes é desprezada pelos DBAs, como se ela não fosse importante. Errado. Ela é essencial para boa operação do banco.
Como vimos, esta operação pode causar lentidão na operação e, portanto, deve-se minimizar o número de vezes que ela acontece a cada dia. Por outro lado, o tamanho deste incremento não pode ser grande demais, porque se não, esta operação vai tomar um tempo enorme quando ela acontecer.
Portanto é bom definir um incremento compatível com o nível de crescimento diário dos seus datafiles. Hoje em dia, muita gente usa incrementos de 100 Mb para o AUTOGROWTH de datafiles.
Observação: no caso de arquivos de log, a questão é diferente, porque o log pode crescer e decrescer muito rapidamente; por isso que tantos DBAs adotam incrementos percentuais para arquivos de log (por exemplo, 10%).
Até a próxima!
Leituras sugeridas
- How Does SQL Server Store Data? por Brent Ozar
- Understanding Pages and Extents por MICROSOFT TECHNET
- Data Pages & Extents por TOADWORLD
- Maximum Capacity Specifications for SQL Server por MSDN
- Buffer Management por MICROSOFT TECHNET
- Inside the Storage Engine: Anatomy of a page por Paul Randall
- SQL Server: Understanding the Data Page Structure por Nelson John.
- Data Pages in Buffer Pool por Pinal Dave
- SQL Server Transaction Log Architecture and Management por MICROSOFT TECHNET
- What Is a Page Split, What Happens, Why Does It Happen, Why worry? por Tony Rogerson

De 0 a 10, o quanto você recomendaria este artigo para um amigo?