

Tem gente que adora o operador LIKE. Ele oferece uma flexibilidade impressionante para pesquisar cadeias de caracteres. Isso é fato.
Mas ele tem um problema sério: operador LIKE, assim como todas as funções SQL, gera predicados “non-SARGable”, ou seja, ele cria critérios de pesquisa que não usam índices.
Obs.: SARG é uma abreviatura pra Search Argument, que, neste caso, se refere a “argumento de pesquisa” de índices; este é um termo usado pela Microsoft há décadas, mas não conheço nenhuma tradução adequada para ele.
Não importa que exista um índice exatamente sobre o campo usado junto como o LIKE. Este índice nunca será usado de forma otimizada. Normalmente, o que acontece é que o otimizador de consultas terá que fazer uma varredura sobre o catálogo de algum índice (o INDEX SCAN). Consequentemente, consultas que usam operador LIKE, via de regra, têm uma performance ruim.
Este comportamento não é problema se você usar o LIKE em consultas envolvendo pequenos volumes de dados (digamos, menos que 10 mil registros). Mas a situação se complica quando tabelas com milhões de registros são usadas na consulta.
Buscando alternativas
Eu já cansei de ver aplicações que usam consultas com cinco, dez ou até mais argumentos na cláusula WHERE, pesquisando campos alfanuméricos com o famigerado “LIKE ‘%xxxxx%’”. Evidente que uma consulta destas nunca terá boa performance. Conscientemente ou não, o desenvolvedor que escreveu esta consulta fez uma troca: abriu mão de performance em benefício da flexibilidade.
Mesmo que você seja um desenvolvedor mais criterioso, não existem soluções milagrosas quando são usados argumentos “non-SARGable”. Porém existem alternativas muito interessantes (mas de alcance restrito) que podem ser aplicadas em casos críticos, ou seja, quando a consulta vai rodar sobre tabelas muito grandes.
Por exemplo, observe que o argumento “Campo1 LIKE ‘xxxxx%’” equivale ao argumento”LEFT(Campo1, 5) = ‘xxxxx’”. O mesmo acontece quando se tem o símbolo ‘%’ exclusivamente do lado esquerdo da cadeia, quando então usamos a função RIGHT.
É verdade que os dois predicados apresentados acima são “non-SARGable” e por isso não vão usar índices adequadamente. Mas o segundo permite que nós usemos uma condição de contorno para o problema.
Este segundo predicado pode ser reescrito para definir uma coluna calculada. Colunas calculadas existem atualmente em todos os principais SGBDs do mercado e são bem fáceis de criar. E, indexando a coluna calculada, poderemos finalmente usar um índice de forma adequada.
Veja na Listagem 1 a sintaxe para definição deste novo campo e o seu índice. Simples e eficiente!
Listagem 1: criando uma coluna calculada com índice:
ALTER TABLE NomeTabela
ADD CampoCalculado AS ( LEFT(CampoOriginal, NumeroPosicoes) )
GO
CREATE INDEX NomeIndice
ON NomeTabela( CampoCalculado)
GO
Avaliando resultados
Para ilustrar a eficiência desta solução, usei uma tabela com cerca de 120 milhões de registros (que chamarei apenas de Tabela) e escolhi um campo alfanumérico de 18 posições variáveis (que chamei de Campo1). O campo calculado (chamado Campo2), terá apenas os 5 primeiros caracteres do campo original (Campo1). Cada um destes dois campos terá seu próprio índice, cada um definido sobre uma das duas colunas estudadas.
A Listagem 2 apresenta estas definições e as duas consultas que foram executadas.
ALTER TABLE Tabela ADD Campo2 AS ( LEFT(Campo1, 5) ) GO CREATE INDEX ixColunaCalc ON Tabela( Campo2 ) GO CREATE INDEX ixColunaOrig ON Tabela( Campo1 ) GO PRINT 'CONSULTA 1' SELECT COUNT(*) FROM Tabela WHERE Campo1 LIKE '76223%' GO PRINT 'CONSULTA 2' SELECT COUNT(*) FROM Tabela WHERE Campo2 = '76223' GO
Definidos os critérios, vamos agora ver os resultados, apresentados nas Figuras 1 e 2.
Figura 1: plano de execução da consulta 1:
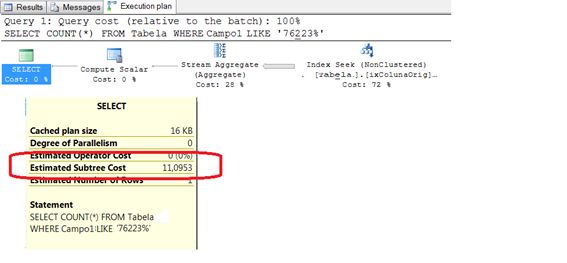
Figura 2: plano de execução da consulta 2:
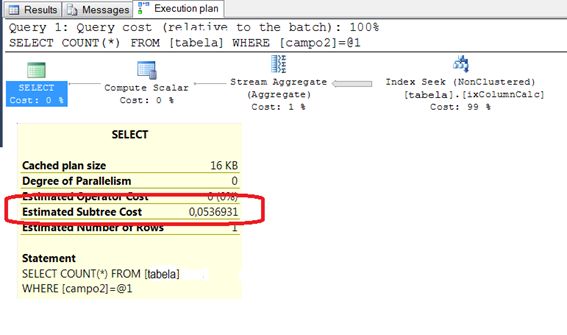
A primeira coisa a se observar é que tanto na consulta 1, como na consulta 2 foram executadas as operações de INDEX SEEK sobres os respectivos índices. Teoricamente, esta seria a melhor condição de pesquisa de um índice. Porém, o custo de execução estimado para as duas consultas varia tremendamente: 11,0953 na consulta 1 e apenas 0,0536931 para a segunda consulta. Ou seja, apesar dos dois planos de execução serem muito parecidos (são exatamente as mesmas operações executadas nos dois casos), o custo total da consulta com coluna calculada representa menos de 0.5% do custo da primeira, que usa o operador LIKE.
Importante observar nestes exemplos que a cardinalidade do campo original (Campo1) é muito baixa. Consequentemente, a cardinalidade do campo calculado (Campo2) era ainda menor. A Tabela 1 resume estes números em detalhe.
Tabela 1: cardinalidade dos campos original e calculado:
| CAMPO | VALORES DISTINTOS | TOTAL DE REGISTROS | CARDINALIDADE |
| Campo1 | 46.000 | 120.000.000 | 0,000383 |
| Campo2 | 7.451 | 120.000.000 | 0,000062 |
Cardinalidades tão baixas atrapalham bastante a performance dos dois índices. Ainda assim, a performance da segunda consulta foi extraordinariamente melhor do que a da consulta que usa o operador LIKE.
Conclusão
O teste apresentado demonstra claramente a vantagem da estratégia de uso da coluna calculada. No entanto este resultado é apenas ilustrativo.
A diferença de performance entre consultas que usam LIKE e consultas que usam colunas calculadas vai variar conforme uma infinidade de variáveis (como, por exemplo, a quantidade de registros da tabela, cardinalidade do campo original e do campo calculado, quantidade de páginas de dados da tabela e de cada um dos índices, atualização de estatísticas de uso de índice etc).
Além do mais, a alternativa de coluna calculada só existe quando é possível substituir o operador LIKE por uma função SQL. Evidentemente, isso é uma limitação importante, porque predicados que envolvam os famosos “LIKE ‘%xxxxx%’” não poderão usar esta estratégia.
De qualquer modo, quando estiver analisando problemas de performance das suas consultas, é bom ter em mente que a coluna calculada pode ser uma alternativa bastante interessante.
Até a próxima!
Leituras sugeridas:
- Crivelini, Wagner. Estudando ações para otimização de índices. Portal iMasters. 21/08/2013.

De 0 a 10, o quanto você recomendaria este artigo para um amigo?