Entendendo o Kafka – Uma visão executiva Inicial
No mundo atual …. sênior, superintendente, enfim, todo executivo precisa ter uma visão de Kafka, compreender como esse tipo …


No mundo atual da digitalização e alta velocidade de informações eu entendo que todo gerente, gerente sênior, superintendente, enfim, todo executivo precisa ter uma visão de Kafka, compreender como esse tipo de solução pode proporcionar agilidade para os negócios de sua organização.
Se você ainda não conhece Kafka e produtos semelhantes a ele entenda que você tem no mínimo uma proposição de solução a menos que seus concorrentes e/ou os players que estão no seu bench.
O que é Event Stream Processing? E o que é o Kafka?
O processamento de fluxo de eventos, ou ESP (Event Stream Processing), é um conjunto de tecnologias projetadas para auxiliar na construção de sistemas de informações orientados a eventos.
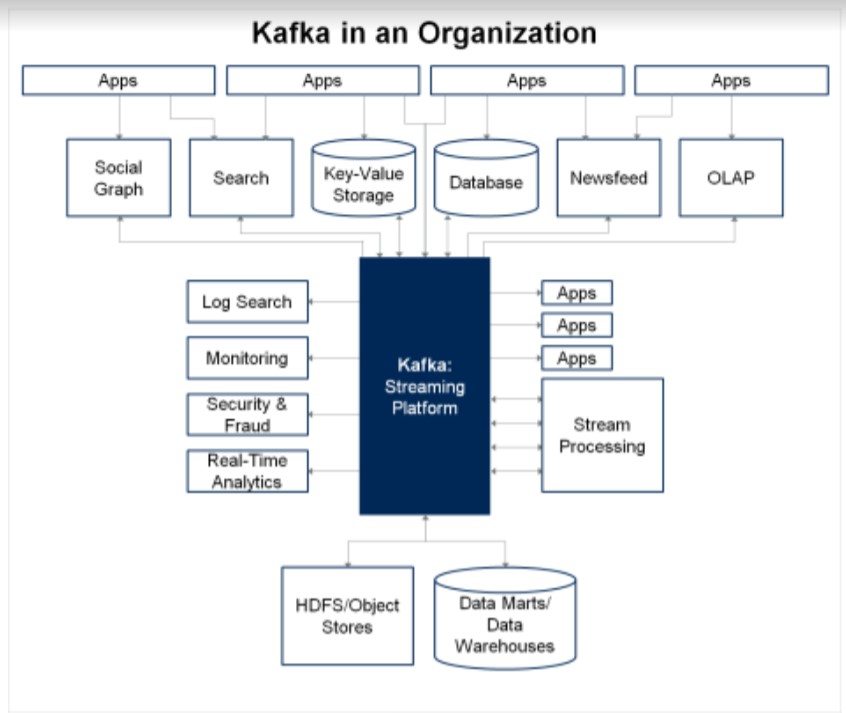
Apache Kafka é uma plataforma open-source de processamento de streams desenvolvida pela Apache Software Foundation, escrita em Scala e Java. O projeto tem como objetivo fornecer uma plataforma unificada, de alta capacidade e baixa latência para tratamento de dados em tempo real.
O Apache Kafka é uma solução largamente utilizada tanto em empresas de pequeno porte como em empresas de grande porte.
É um sistema de eventos Publisher-subscriber (publicador-assinante) originalmente projetado para resolver o problema de comunicação de dados ponto a ponto e processamento de dados entre vários sistemas dentro de uma organização.
A maioria das organizações tem fontes de dados onde os dados são gerados e consumidos de várias formas, de dados estruturados transacionais a arquivos de log e saídas ETL.
A troca de dados entre esses sistemas geralmente resulta em uma explosão de sistemas distintos, processando-os com diferentes pipelines de dados.
O Kafka surgiu da necessidade de fornecer uma plataforma consolidada para oferecer suporte a um fluxo de dados contínuo e perfeito entre esses sistemas.
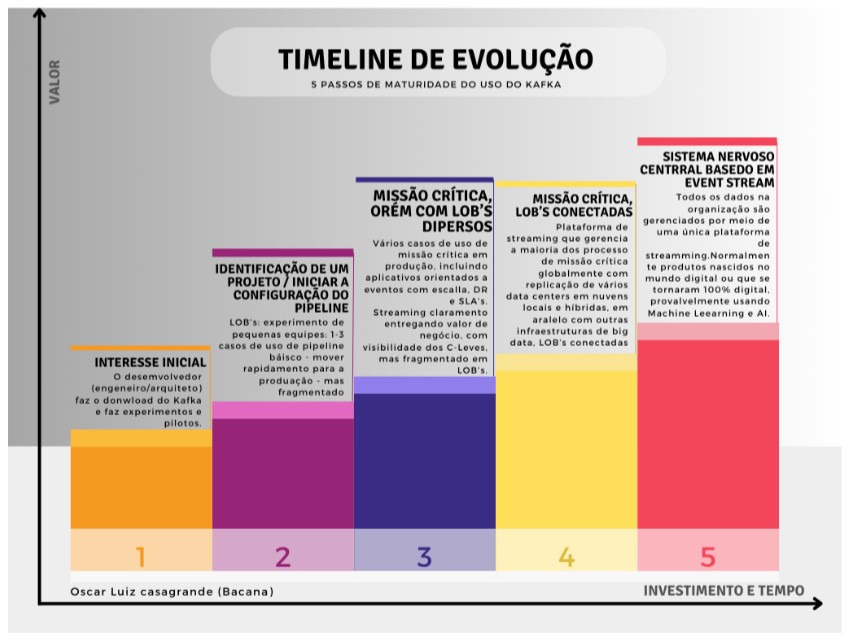
5 passos para adoção do Kafka
- 1. Interesse inicial: O desenvolvedor (engenheiro/arquiteto) faz o download e faz experimentos e pilotos;
- 2. Identificação de um projeto / Iniciar a configuração do pipeline: LOBs: experimento de pequenas equipes: 1-3 casos de uso de pipeline básico – mover rapidamente para a produção – mas fragmentado;
- 3. Missão crítica, porém com LOBs díspares:Vários casos de uso de missão crítica em produção, incluindo aplicativos orientados a eventos contextuais com escala, DR e SLAs. Streaming claramente entregando valor de negócios, com visibilidade C-Levels, mas fragmentado em LOBs;
- 4. Missão crítica, LOBs conectadas: Plataforma de streaming que gerencia a maioria dos processos de missão crítica globalmente com replicação de vários datacenters em nuvens locais e híbridas; em paralelo com outras infraestruturas de big data; LOBs conectados;
- 5. Sistema nervoso central baseado em Event Stream: Todos os dados na organização são gerenciados por meio de uma única plataforma de streaming. Normalmente produtos nascidos no mundo digital ou que se tornaram 100% digital, provavelmente usando Machine Learning e AI;
LOB – Line of business
Arquitetura do Kafka
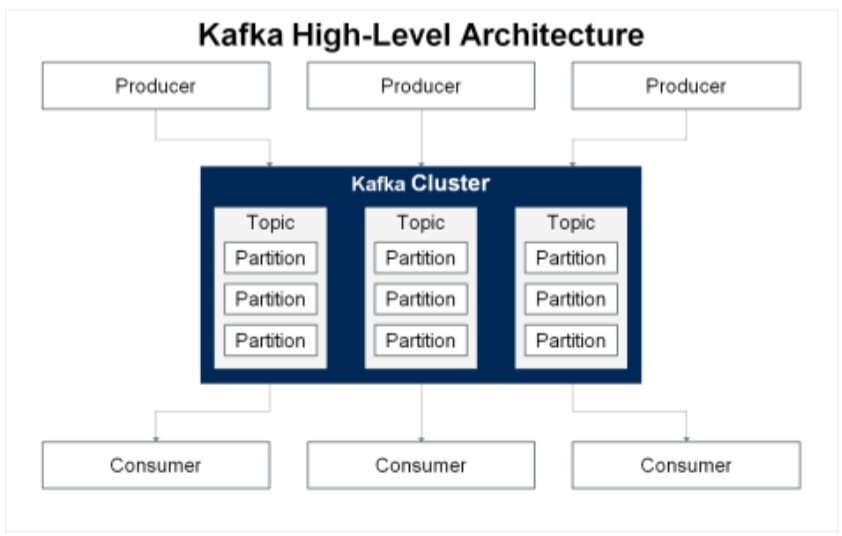
● Broker: um único nó Kafka é um broker. Ele recebe mensagens de produtores, atribui deslocamento e confirma as mensagens para
armazenamento. Ele atende às solicitações de busca dos consumidores para partições de tópico e envia a mensagem.
● Produtor/Producer: um aplicativo ou sistema que pode gravar dados no cluster é o produtor. Esta é a fonte de mensagens para tópicos do Kafka. Os produtores publicam mensagens de acordo com os protocolos Kafka. O produtor se conecta a pelo menos um broker para buscar metadados e, em seguida, envia a sequência de bytes ordenada ao broker. É responsabilidade do produtor determinar quais dados de partição de tópico precisam ser enviados.
● Consumidor/Consumer: os consumidores Kafka consomem as mensagens criadas pelos produtores dos tópicos Kafka. Os consumidores assinam um ou mais tópicos. Cada consumidor tem uma identidade única e controla como lê os dados da partição de tópico Kafka. Os consumidores têm compensações de consumidor que são armazenadas no Apache ZooKeeper.
● Registro: os dados gravados no Kafka são chamados de registro. Geralmente não há limite de tamanho, mas os registros geralmente têm
menos de 1 MB.
● Tópico: Kafka organiza conjuntos de registros em tópicos. Um tópico é um agrupamento de informações relacionadas que seriam do interesse de um consumidor. Da mesma forma que um cliente se inscreve em uma lista de correio ou grupo de distribuição específico, um consumidor Kafka se inscreve em um tópico.
● Partição: cada tópico é armazenado como várias partições. Novos registros gravados em um tópico Kafka são anexados a uma partição para esse tópico. O Kafka escolhe e equilibra automaticamente as partições para o tópico (isso também pode ser feito manualmente). Mais partições permitem o dimensionamento paralelo de gravações e leituras de tópicos.
● Replicação: Cada partição é replicada entre os brokers. Os produtores e consumidores irão gravar e ler em uma partição líder, mas várias partições de réplicas sincronizadas são mantidas em cada partição líder. Isso fornece redundância de dados em caso de falhas do corretor.
● Cluster: coleções de corretores formam clusters Kafka. Como as partições são replicadas entre os brokers, os consumidores chamam os dados de vários brokers. Cada partição pertence a um broker, conhecido como líder dessa partição. Existem cópias de cada partição em outros brokers, conhecidos como réplicas.
● Offset: Cada mensagem no Kafka é atribuída com um offset. Os tópicos consistem em partições, e cada partição armazena mensagens na ordem em que chegam. Os consumidores reconhecem as mensagens com um deslocamento, indicando que todas as mensagens anteriores ao
deslocamento foram recebidas pelo consumidor.
● ZooKeeper: uma ferramenta como o Apache ZooKeeper é necessária para gerenciar um cluster de corretores. O ZooKeeper mantém metadados de cluster, incluindo tópicos e listas de corretores ativos.
● Persistente: o Kafka usa armazenamento durável para manter todos os registros. Os dados gravados no Kafka são retidos por parâmetros de tempo configuráveis chamados tempo de vida (TTL), como horas, dias ou mais. O conceito de persistência de dados de Kafka permite que Kafka armazene o consumo de seus conjuntos de dados. Os consumidores podem extrair dados em suas próprias velocidades – em milissegundos ou dias. O TTL padrão é sete dias.
● Append-only/Somente anexo: depois que os dados são gravados no Kafka, eles se tornam imutáveis. Os registros não são alterados, apenas novos adicionados. Isso cria uma trilha de auditoria e permite a reconstrução e a proveniência de todos os registros em um sistema Kafka. Os dados brutos também são preservados e se prestam a casos de uso de consumo adicionais.
● Publisher-subscriber/Publicador-assinante: comunicação dos corretores Kafka entre os processos do cliente que produzem ou consomem registros. Kafka implementa essa comunicação usando o padrão publicar-assinar (pub-sub). Esse padrão é fundamental para arquiteturas orientadas a eventos, permitindo que um ou mais produtores publiquem registros de eventos em um tópico sem conhecimento dos destinatários e permitindo que um número arbitrário de consumidores receba e processe esses eventos de forma independente e assíncrona.
Arquitetura
Espero que você tenha curtido esse artigo! Você gostaria de saber mais sobre Kafka e ESP? Quer ver aplicações na prática? Quer saber como ele pode resolver problemas de log (regulatório), estoque, localização entre outras coisas? Só comentar aqui no artigo que falarei desses temas com muito gosto, e dependendo da questão eu posso até desenvolver um artigo para responder a isso!
Um abração e até próxima bacana!
Referências
https://en.wikipedia.org/wiki/Event_stream_processing
https://pt.wikipedia.org/wiki/Apache_Kafka
https://www.infoq.com/br/articles/apache-kafka-licoes/
https://www.confluent.io/apache-kafka-report/
é técnico em Processamento de Dados pelo Colégio Técnico Elevação, tecnólogo em Desenvolvimento de Sistemas para Web no Instituto Brasileiro de Tecnologia Avançado (IBTA, agora Instituto Veris) e faz pós-graduação em Engenharia de Sistemas com ênfase em SOA, no Instituto Veris.