

O Lucene é um framework para busca textual de alta performance escrito totalmente em Java e bastante fácil de usar. Podemos adicionar as funcionalidades de busca em qualquer aplicação, uma vez que o Lucene conta com uma API bastante completa e plugável. A biblioteca é bastante famosa, sendo utilizada em alguns dos maiores portais da Internet.
Há uma versão para .Net, o Lucene.Net, e ports para outras linguagens. Uma alternativa bastante interessante é o Solr (pronuncia-se ‘sólar’), um servidor corporativo de buscas já otimizado para aplicações web, que é um subprojeto do Lucene. No Solr, as operações podem ser feitas através de JSON, XML, HTTP, CSV, etc, o que permite a integração com virtualmente todas as plataformas.
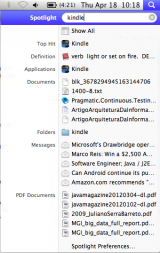
Tanto Windows quanto o Mac OS X têm mecanismo de busca nativo, o que faz com que encontrar um arquivo qualquer seja muito fácil. No Mac, o Spotlight procura em todo o sistema de arquivo em busca de aplicativos, e-mails, documentos, definição no vocabulário, diretórios, etc.
Nos dois casos (Windows e Mac) estamos limitados ao sistema de arquivos da máquina do usuário. Neste artigo vamos implementar um buscador utilizando Lucene, que pode indexar vários formatos de documento, até mesmo através da rede, e disponibilizar essa informação para todos os usuários de uma corporação.
Em artigos posteriores veremos como indexar bancos de dados relacionais e discutiremos as vantagens, desvantagens, possibilidades e limitações deste tipo de solução.
As funcionalidades de um buscador: indexação e busca
A indexação consiste em recuperar o texto contido em um documento e adicioná-lo ao índice, tornando essa informação disponível para o usuário. Imaginando que hoje estamos acostumados a ter qualquer informação imediatamente, o fator velocidade é essencial. Essa operação é lenta, pois envolve muito processamento e gravação em disco. Indexar grandes volumes de dados demora bastante tempo e para isso há ferramentas específicas.
Para o Lucene, cada item indexado é um Document e contém uma coleção de campos. Um campo deve ter nome e valor textual. A busca pode ser feita em qualquer um desses campos.
O Google, Bing, Yahoo!, Ask, etc funcionam assim. Além da página de busca, há um webcrawler visitando todos os sites da Internet e indexando seu conteúdo. Esse processo é constante, até porque a internet é dinâmica. Sem contar que hoje temos conteúdo multimídia; não é apenas texto ou HTML como foi no começo da internet, há décadas atrás. Hoje a internet tem muito mais que apenas texto. Temos imagem, som, vídeo, portais verticais, Wolpham Alpha, web semântica e mídias sociais. E tudo isso deve estar disponível em tempo real.
A busca consiste em recuperar os documentos que contém um termo informado pelo usuário. No Lucene essa operação é extremamente rápida. Mesmo uma consulta complexa, feita em um índice com milhões de documentos, dura menos de um segundo. Além disso, o resultado da busca pode vir ordenado ou classificado (melhores resultados aparecem primeiro). E são muitas as opções de consulta fornecidas pelo Lucene:
- Busca por palavra-chave ou frase;
- Busca em campos específicos;
- Busca com wildcard (* e ?);
- Busca aproximada, utilizando a Distância de Levenshtein;
- Busca por proximidade entre palavras;
- Busca por intervalos de valores (datas, números ou letras);
Vale notar que o Lucene indexa apenas texto. Para indexar documentos binários (MS Office, PDF, RTF, etc) temos que utilizar alguma biblioteca de extração de texto, como o Apache Tika, que consegue recuperar texto em diversos formatos de arquivo.
O projeto
Composto por duas classes (Indexador e Buscador), o projeto proposto indexa um diretório informado pelo programador. Pode ser um diretório local, um compartilhamento Windows ou um diretório NFS.
Indexador
package net.marcoreis.util;
import java.io.*;
import java.text.*;
import org.apache.log4j.*;
import org.apache.lucene.analysis.*;
import org.apache.lucene.analysis.standard.*;
import org.apache.lucene.document.*;
import org.apache.lucene.index.*;
import org.apache.lucene.store.*;
import org.apache.lucene.util.*;
import org.apache.tika.*;
public class Indexador {
private static Logger logger = Logger.getLogger(Indexador.class);
//{1}
private String diretorioDosIndices = System.getProperty("user.home")
+ "/indice-lucene";
//{2}
private String diretorioParaIndexar = System.getProperty("user.home")
+ "/Dropbox/MaterialDeEstudo/big-data";
//{3}
private IndexWriter writer;
//{4}
private Tika tika;
public static void main(String[] args) {
Indexador indexador = new Indexador();
indexador.indexaArquivosDoDiretorio();
}
public void indexaArquivosDoDiretorio() {
try {
File diretorio = new File(diretorioDosIndices);
apagaIndices(diretorio);
//{5}
Directory d = new SimpleFSDirectory(diretorio);
logger.info("Diretório do índice: " + diretorioDosIndices);
//{6}
Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_36);
//{7}
IndexWriterConfig config = new IndexWriterConfig(Version.LUCENE_36,
analyzer);
//{8}
writer = new IndexWriter(d, config);
long inicio = System.currentTimeMillis();
indexaArquivosDoDiretorio(new File(diretorioParaIndexar));
//{12}
writer.commit();
writer.close();
long fim = System.currentTimeMillis();
logger.info("Tempo para indexar: " + ((fim - inicio) / 1000) + "s");
} catch (IOException e) {
logger.error(e);
}
}
private void apagaIndices(File diretorio) {
if (diretorio.exists()) {
File arquivos[] = diretorio.listFiles();
for (File arquivo : arquivos) {
arquivo.delete();
}
}
}
public void indexaArquivosDoDiretorio(File raiz) {
FilenameFilter filtro = new FilenameFilter() {
public boolean accept(File arquivo, String nome) {
if (nome.toLowerCase().endsWith(".pdf")
|| nome.toLowerCase().endsWith(".odt")
|| nome.toLowerCase().endsWith(".doc")
|| nome.toLowerCase().endsWith(".docx")
|| nome.toLowerCase().endsWith(".ppt")
|| nome.toLowerCase().endsWith(".pptx")
|| nome.toLowerCase().endsWith(".xls")
|| nome.toLowerCase().endsWith(".txt")
|| nome.toLowerCase().endsWith(".rtf")) {
return true;
}
return false;
}
};
for (File arquivo : raiz.listFiles(filtro)) {
if (arquivo.isFile()) {
StringBuffer msg = new StringBuffer();
msg.append("Indexando o arquivo ");
msg.append(arquivo.getAbsoluteFile());
msg.append(", ");
msg.append(arquivo.length() / 1000);
msg.append("kb");
logger.info(msg);
try {
//{9}
String textoExtraido = getTika().parseToString(arquivo);
indexaArquivo(arquivo, textoExtraido);
} catch (Exception e) {
logger.error(e);
}
} else {
indexaArquivosDoDiretorio(arquivo);
}
}
}
private void indexaArquivo(File arquivo, String textoExtraido) {
SimpleDateFormat formatador = new SimpleDateFormat("yyyyMMdd");
String ultimaModificacao = formatador.format(arquivo.lastModified());
//{10}
Document documento = new Document();
documento.add(new Field("UltimaModificacao", ultimaModificacao,
Field.Store.YES, Field.Index.NOT_ANALYZED));
documento.add(new Field("Caminho", arquivo.getAbsolutePath(),
Field.Store.YES, Field.Index.NOT_ANALYZED));
documento.add(new Field("Texto", textoExtraido, Field.Store.YES,
Field.Index.ANALYZED));
try {
//{11}
getWriter().addDocument(documento);
} catch (IOException e) {
logger.error(e);
}
}
public Tika getTika() {
if (tika == null) {
tika = new Tika();
}
return tika;
}
public IndexWriter getWriter() {
return writer;
}
}
- Diretório que irá guardar o índice;
- Diretório que contém os documentos que serão indexados;
- IndexWriter: cria e mantém o índice;
- Biblioteca que extrai texto de diversos formatos conhecidos;
- Directory: representa o diretório do índice;
- Analyser/StandardAnalyser: fazem o pré-processamento do texto. Existem analisadores inclusive em português;
- IndexWriterConfig: configurações para criação do índice. No projeto serão utilizados os valores padrão;
- Inicializa o IndexWriter para gravação;
- Extrai o conteúdo do arquivo com o Tika;
- Monta um Document para indexação
Field.Store.YES: armazena uma cópia do texto no índice, aumentando muito o seu tamanho;
Field.Index.ANALYZED: utilizado quando o campo é de texto livre;
Field.Index.NOT_ANALYZED: utilizado quando o campo é um ID, data ou númerico. - Adiciona o Document no índice, mas este só estará disponível para consulta após o commit.
Buscador
package net.marcoreis.util;
import java.io.*;
import javax.swing.*;
import org.apache.log4j.*;
import org.apache.lucene.analysis.*;
import org.apache.lucene.analysis.standard.*;
import org.apache.lucene.document.*;
import org.apache.lucene.index.*;
import org.apache.lucene.queryParser.*;
import org.apache.lucene.search.*;
import org.apache.lucene.store.*;
import org.apache.lucene.util.*;
public class Buscador {
private static Logger logger = Logger.getLogger(Buscador.class);
private String diretorioDoIndice = System.getProperty("user.home")
+ "/indice-lucene";
public void buscaComParser(String parametro) {
try {
Directory diretorio = new SimpleFSDirectory(new File(diretorioDoIndice));
//{1}
IndexReader leitor = IndexReader.open(diretorio);
//{2}
IndexSearcher buscador = new IndexSearcher(leitor);
Analyzer analisador = new StandardAnalyzer(Version.LUCENE_36);
//{3}
QueryParser parser = new QueryParser(Version.LUCENE_36, "Texto",
analisador);
Query consulta = parser.parse(parametro);
long inicio = System.currentTimeMillis();
//{4}
TopDocs resultado = buscador.search(consulta, 100);
long fim = System.currentTimeMillis();
int totalDeOcorrencias = resultado.totalHits;
logger.info("Total de documentos encontrados:" + totalDeOcorrencias);
logger.info("Tempo total para busca: " + (fim - inicio) + "ms");
//{5}
for (ScoreDoc sd : resultado.scoreDocs) {
Document documento = buscador.doc(sd.doc);
logger.info("Caminho:" + documento.get("Caminho"));
logger.info("Última modificação:" + documento.get("UltimaModificacao"));
logger.info("Score:" + sd.score);
logger.info("--------");
}
buscador.close();
} catch (Exception e) {
logger.error(e);
}
}
public static void main(String[] args) {
Buscador b = new Buscador();
String parametro = JOptionPane.showInputDialog("Consulta");
b.buscaComParser(parametro);
}
}
- IndexReader: classe abstrata responsável por acessar o índice;
- IndexSearcher: implementa os métodos necessários para realizar buscas em um índice;
- QueryParser/Query: representa a consulta do usuário. Outros exemplos de query podem ser vistos no Javadoc;
- Realiza a busca e armazena o resultado em um TopDocs;
- ScoreDoc: representa cada um dos documentos retornados na busca.
Exemplos de busca
Busca por palavra-chave
Rode o Buscador e digite “java” como termo de consulta. Será mostrado o resultado com vários documentos contendo essa palavra. Em seguida, busque por “java -ejb”, ou seja, documentos que contém o termo “java” e não “ejb”.
Intervalos
Para pesquisar um intervalo, utilize a consulta “UltimaModificacao:[20110101 TO 20110606]“. Funciona também para intervalo de letras.
Busca aproximada
Digite “servlet~” ou “servlet~0.7″ e compare os resultados. O resultado mostra documentos que contenham algum termo parecido com “servlet”, usando a Distância de Levenshtein. O padrão é 0.5, ou seja, “servlet~” e “servlet~0.5″ são iguais para o Lucene. Podemos aumentar a precisão, como é o caso de servlet~0.7
Código
O código-fonte do aplicativo está disponível aqui.

De 0 a 10, o quanto você recomendaria este artigo para um amigo?