

Arquiteturas de microsserviços resolvem o problema de escalabilidade computacional, mas invariavelmente introduzem um ponto cego operacional massivo. Quando uma transação de usuário transita por cinco contextos delimitados (bounded contexts) independentes e falha silenciosamente, a correlação manual de logs fragmentados consome horas de engenharia investigativa. Essa opacidade destrói a confiabilidade do sistema e prolonga o Tempo Médio de Recuperação (MTTR) durante incidentes críticos, violando Acordos de Nível de Serviço (SLAs). A implementação de uma malha de telemetria agnóstica baseada no padrão OpenTelemetry e centralizada no Azure Application Insights resolve esta cegueira sistêmica. Ao padronizar a emissão de rastreamentos (traces), métricas e logs, e ao injetar cabeçalhos de correlação universais em cada requisição de rede, as corporações constroem um mapa topológico automatizado em tempo real. Esta arquitetura entrega visibilidade absoluta sobre a latência e os gargalos de cada componente isolado, garantindo observabilidade acionável e resiliência proativa para sistemas corporativos hospedados no ecossistema Microsoft Azure (Beyer et al., 2016).
Pré-requisitos
O provisionamento desta infraestrutura de observabilidade exige proficiência em instrumentação de código e análise de grafos de telemetria. O ambiente deve ser automatizado utilizando o Terraform versão 1.7.0 ou superior e o provedor HashiCorp AzureRM versão 3.90.0. A camada de computação requer o Python 3.12, acoplado às bibliotecas padrão opentelemetry-api, opentelemetry-sdk e ao exportador oficial azure-monitor-opentelemetry. A configuração infraestrutural exige privilégios de Contribuidor (Contributor) no Azure para orquestrar os espaços de trabalho do Log Analytics e gerenciar as chaves de roteamento de telemetria.
Passo a Passo
Provisionamento do Backend Analítico Unificado
A fundação da observabilidade inicia-se com a criação de um repositório centralizado capaz de ingerir, indexar e correlacionar milhões de pontos de dados de telemetria por segundo. Provisionamos um Azure Log Analytics Workspace acoplado a um recurso do Azure Application Insights utilizando Terraform. A justificativa técnica para separar logicamente o Application Insights do Workspace subjacente baseia-se na governança de dados corporativa. O Workspace atua como o banco de dados analítico bruto operando sob a linguagem Kusto Query Language (KQL), permitindo retenção de longo prazo e cruzamento de dados com métricas de infraestrutura do Kubernetes ou máquinas virtuais. O Application Insights, atuando como a camada de apresentação inteligente, consome esses dados para gerar mapas de aplicação dinâmicos, perfis de desempenho e alertas de anomalia baseados em aprendizado de máquina. O recurso exporta uma string de conexão (Connection String) imutável, que servirá como a única credencial de roteamento necessária para que os microsserviços relatem seus estados de execução.
resource "azurerm_resource_group" "observability_rg" {
name = "rg-enterprise-observability"
location = var.location
}
resource "azurerm_log_analytics_workspace" "core_laws" {
name = "laws-enterprise-core"
location = azurerm_resource_group.observability_rg.location
resource_group_name = azurerm_resource_group.observability_rg.name
sku = "PerGB2018"
retention_in_days = 30
}
resource "azurerm_application_insights" "microservices_ai" {
name = "ai-enterprise-microservices"
location = azurerm_resource_group.observability_rg.location
resource_group_name = azurerm_resource_group.observability_rg.name
workspace_id = azurerm_log_analytics_workspace.core_laws.id
application_type = "web"
}
output "application_insights_connection_string" {
value = azurerm_application_insights.microservices_ai.connection_string
sensitive = true
}Como instrumentamos o código da nossa aplicação para enviar dados contínuos de telemetria para este espaço de trabalho sem acoplar rigidamente nosso núcleo de domínio corporativo a SDKs proprietários ou bibliotecas fechadas da Microsoft?
Instrumentação Hexagonal com OpenTelemetry
Instrumentamos a aplicação adotando o padrão aberto OpenTelemetry exclusivamente nas camadas de adaptadores da nossa Arquitetura Hexagonal. O princípio fundamental deste design dita que a lógica de domínio (as regras de negócios de faturamento ou inventário) deve permanecer completamente limpa e ignorar a existência de mecanismos de rastreamento. Instanciamos o provedor global de rastreamento (Tracer Provider) no ponto de entrada da aplicação (Entrypoint) e utilizamos o pacote azure-monitor-opentelemetry para direcionar a exportação dos dados. Quando uma requisição HTTP entra no adaptador primário (como um controlador FastAPI), iniciamos um trecho (Span) que mede o tempo total da operação. Este Span é passado explicitamente ou via variáveis de contexto (ContextVars) para os adaptadores secundários que conversam com o banco de dados. Dessa forma, a engenharia evita o aprisionamento tecnológico (vendor lock-in). Se a corporação decidir migrar a análise de telemetria do Azure para o Datadog ou Jaeger, nenhuma linha de código dentro dos microsserviços precisa ser reescrita; apenas a classe exportadora no ponto de entrada é substituída.
import os
import time
from typing import Dict, Any
from opentelemetry import trace
from azure.monitor.opentelemetry import configure_azure_monitor
# Configuração executada na inicialização do microsserviço (Entrypoint)
configure_azure_monitor(
connection_string=os.environ["APPLICATIONINSIGHTS_CONNECTION_STRING"],
logger_name="EnterpriseDomainLogger"
)
tracer = trace.get_tracer("PaymentMicroservice", "1.0.0")
class PaymentDomainService:
def process_payment(self, account_id: str, amount: float) -> str:
# O domínio permanece puro, focando apenas na lógica de negócios
time.sleep(0.1) # Simulação de cálculo pesado
return f"txn_{account_id}_success"
class HttpPrimaryAdapter:
def __init__(self, domain_service: PaymentDomainService):
self.domain_service = domain_service
def handle_request(self, payload: Dict[str, Any]) -> Dict[str, str]:
# O adaptador envolve a execução do domínio em um Span instrumentado
with tracer.start_as_current_span("process_payment_request") as span:
account_id = payload.get("account_id", "unknown")
amount = payload.get("amount", 0.0)
span.set_attribute("business.account_id", account_id)
span.set_attribute("business.transaction_amount", amount)
try:
result = self.domain_service.process_payment(account_id, amount)
span.set_status(trace.StatusCode.OK)
return {"status": result}
except Exception as e:
span.set_status(trace.StatusCode.ERROR, str(e))
span.record_exception(e)
raise e
domain = PaymentDomainService()
adapter = HttpPrimaryAdapter(domain)Uma vez que o serviço gera e exporta rastreamentos locais detalhados de forma agnóstica, como propagamos esse exato contexto de execução através da rede quando nosso adaptador necessita invocar um microsserviço downstream gerenciado por outra equipe?
Propagação de Contexto W3C e Correlação Distribuída
Propagamos esse contexto de execução utilizando o padrão universal W3C Trace Context, injetando identificadores matemáticos diretamente nos cabeçalhos do protocolo HTTP ou em metadados de mensagens AMQP. O Application Insights requer uma cadeia hierárquica ininterrupta para desenhar o Mapa da Aplicação (Application Map). Quando o microsserviço A (Pedidos) invoca o microsserviço B (Faturamento), ele deve repassar o trace_id global (que representa a transação inteira do usuário) e o seu próprio span_id atual (que servirá como o parent_id para a próxima operação). O OpenTelemetry automatiza essa extração e injeção através de propagadores nativos. O adaptador cliente HTTP extrai o contexto ativo da thread atual e o serializa no cabeçalho traceparent. O microsserviço receptor lê esse cabeçalho antes de iniciar sua própria instrumentação, unificando a árvore de execução. Essa padronização garante correlação perfeita mesmo se os serviços downstream forem construídos em Go, Java ou hospedados em outra nuvem, consolidando a rastreabilidade ponta a ponta.
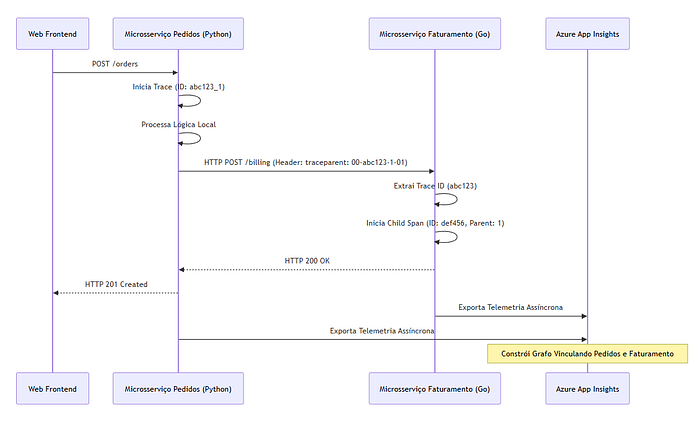
Diagrama de sequência
import requests
from opentelemetry.propagate import inject
from opentelemetry.trace.propagation.tracecontext import TraceContextTextMapPropagator
class OutboundHttpAdapter:
def __init__(self, billing_service_url: str):
self.billing_service_url = billing_service_url
def notify_billing(self, invoice_data: dict) -> None:
# Inicia um Span representando a chamada de rede externa
with tracer.start_as_current_span("http_post_billing") as span:
headers = {}
# O Propagator injeta os cabeçalhos W3C (traceparent e tracestate) no dicionário
TraceContextTextMapPropagator().inject(headers)
span.set_attribute("http.method", "POST")
span.set_attribute("http.url", self.billing_service_url)
response = requests.post(
self.billing_service_url,
json=invoice_data,
headers=headers,
timeout=5.0
)
span.set_attribute("http.status_code", response.status_code)
response.raise_for_status()Se a propagação de contexto garante o rastreamento perfeito sob condições normais em ambientes de teste, como identificamos e resolvemos os casos onde a telemetria desaparece silenciosamente ou os gráficos de dependência se partem durante picos massivos de tráfego na produção?
Solução de Problemas Comuns
Identificamos e resolvemos o desaparecimento de telemetria inspecionando e ajustando as políticas de Amostragem (Sampling) do OpenTelemetry e do Application Insights. Em ambientes de produção recebendo milhares de requisições por segundo, exportar 100% dos rastreamentos consome largura de banda excessiva e inflaciona a fatura do Azure Log Analytics. Por padrão, muitos SDKs e o próprio Azure implementam amostragem baseada em taxa (Rate Limiting Sampling). Se a equipe de engenharia reportar que transações de erro específicas não estão aparecendo no portal do Azure, o sistema provavelmente descartou a telemetria na origem. A solução técnica exige a configuração explícita de um amostrador baseado em cauda (Tail-Based Sampler) ou um OTEL_TRACES_SAMPLER=parentbased_traceidratio no ambiente da aplicação, garantindo que se uma transação falhar, toda a árvore de rastreamento seja forçosamente registrada e exportada, suprimindo o descarte estocástico de erros críticos.
Outra falha estrutural apresenta-se através da fragmentação do Mapa de Aplicação, onde o microsserviço A e o microsserviço B aparecem como nós completamente isolados, sem arestas de conexão. Este sintoma de “spans órfãos” é causado pela quebra na cadeia do W3C Trace Context. A causa raiz invariavelmente repousa em proxies intermediários, malhas de serviço (Service Meshes) ou gateways de API (como o Azure Application Gateway ou NGINX) configurados incorretamente para descartar cabeçalhos HTTP desconhecidos. Para restaurar a integridade do grafo, inspecione a configuração de roteamento dos equipamentos de rede intermediários e garanta que os cabeçalhos traceparent e tracestate estejam explicitamente declarados na lista de permissões (Allowlist) de repasse (Pass-through headers) de toda a infraestrutura de trânsito.
Conclusão
A instrumentação nativa com OpenTelemetry ancorada no Azure Application Insights transcende a mera coleta de logs, elevando a operação a um estado de observabilidade determinística. Ao separar a geração de telemetria na camada de adaptadores e aplicar rigorosamente a propagação W3C, as corporações adquirem imunidade contra a complexidade arquitetônica de ecossistemas fortemente distribuídos. Esta topologia rastreável permite respostas cirúrgicas a incidentes e otimização contínua de latência. O amadurecimento desta disciplina exige a construção de alertas dinâmicos baseados em KQL (Kusto Query Language), acionando rotinas automáticas de reversão de implantação (Rollback) no Azure DevOps caso as taxas de erro ou percentis de latência exportados pelos rastreamentos ultrapassem os limiares de tolerância estipulados nos Objetivos de Nível de Serviço (SLOs).

De 0 a 10, o quanto você recomendaria este artigo para um amigo?