

Este artigo deveria ter sido publicado na edição de novembro da Revista iMasters (#12). No entanto, por um erro nosso, o conteúdo saiu errado – em vez de publicar o texto que você lerá abaixo, publicamos o artigo anterior da Fernanda Weiden. Pedimos nossas sinceras desculpas a ela e a você, leitor.
***
Um grande número de websites que se tornam populares e atraem milhares de usuários começa como uma simples arquitetura LAMP: Linux, Apache, MySQL e PHP. No Facebook não foi diferente. Com o crescimento do site, foi necessário encontrar soluções para que o acesso aos dados fosse rápido e mais eficaz do que o acesso direto à base de dados (que no nosso caso também é MySQL). Foi quando começamos a usar memcache. Isso, explico, muito antes de eu chegar por aqui.
O memcache é um software que faz armazenamento de pares de chave e valor em memória. Ele oferece uma série de vantagens para as arquiteturas que o utilizam:
- O acesso à memória é mais rápido do que o acesso a disco, portanto você proporciona uma melhor experiência aos seus usuários;
- Serve como um “escudo” para os seus servidores de bancos de dados, que receberão uma quantidade menor de requisições, já que os acessos ao banco de dados são reduzidos a somente dados solicitados com menor frequência;
- Como seus bancos de dados são menos acessados, o hardware desses servidores provavelmente poderá ser menos potente, e terá um tempo de vida maior. A combinação desses fatores contribui para baixar os custos com esse tipo de hardware, que geralmente é mais robusto e, portanto, mais caro que servidores normais.
Uma consequência do uso de tecnologias de cache é que, com o aumento da sua infraestrutura, o cache passa de otimização para necessidade. E como qualquer parte da arquitetura que é vital para o funcionamento do seu sistema, quanto mais limpa e escalável, melhor. Como ampliar o tamanho do seu cache quando um só computador não é mais suficiente para armazenar todos os dados que você precisa?
Algumas vezes, os engenheiros acabam criando mais complexidade do que necessário ao ter que implementar uma lógica que saiba para onde enviar cada requisição na camada da aplicação web. Pelo menos o começo é sempre assim. Porém, a simplicidade se torna necessária para garantir a escalabilidade das soluções e também o nível de confiabilidade dos sistemas.
No Facebook, a resposta para esse desafio foi dada com uma solução de engenharia com a qual eu trabalho todos os dias: mcrouter. O mcrouter é o roteador do protocolo memcache, que é usado no Facebook para rotear todo o tráfego que tenha origem ou destino em um dos nossos servidores de cache. Em situações de pico, o mcrouter hoje roteia pouco menos do que 5 bilhões de requisições por segundo. No último dia 15 de setembro, foi liberado como Software Livre e está disponível no GitHub sob licença BSD.
Basicamente, o mcrouter recebe todas as requisições destinadas ao memcache, e as direciona baseado em regras que você pode criar para esse roteamento. Essas regras vão desde pooling de conexões, para reaproveitar conexões com os servidores de memcache, a diferentes esquemas para distribuição de dados entre os participantes de seu cluster memcache.
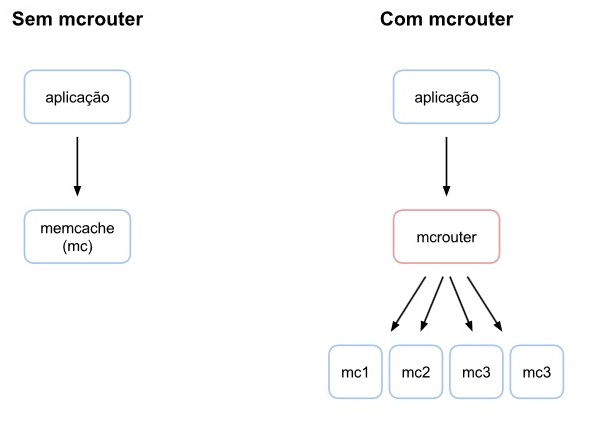
Utilizando o mcrouter, você pode criar o conceito de pools replicadas, uma resposta ao desafio de alta disponibilidade da sua camada de cache, fazendo com que o próprio mcrouter resolva a escrita de dados nas diversas réplicas dessa pool. Ele também pode fazer o roteamento baseado no prefixo das chaves armazenadas em cada servidor, e assim pode combinar workloads ou cargas similares em alguns servidores selecionados para cada uma desses padrões de carga ou tipo de dados.
O mcrouter também monitora os servidores de destino, e marca aqueles que não estejam “saudáveis” como não disponíveis. Quando isso acontece, ele faz automaticamente o failover (ou redirecionamento após falha) para outro destino. Desse modo, assim que o monitoramento interno do mcrouter informa que o destino original está novamente funcionando, as requisições voltam a ser direcionadas para ele. Outras funcionalidades importantes são suporte para IPv6 (Internet Protocol version 6) e SSL (Secure Sockets Layer).
Para quem se interessa por cache e gosta de brincar com infraestruturas de larga escala e altamente disponíveis, fica meu convite para experimentar esse “brinquedinho” e analisar seus benefícios para suas arquiteturas em particular.
E cada vez que você acessar o Facebook, pode ter certeza de que cada requisição de cache está passando por esse codepath.
Mais informações estão disponíveis neste link.

De 0 a 10, o quanto você recomendaria este artigo para um amigo?