



Um ambiente simples usando Kubernetes e OpenShift Next Gen – Parte 02
Este artigo é parte de uma série sobre o básico necessário para usar o Kubernetes.

Este artigo é parte de uma série sobre o básico necessário para usar o Kubernetes. Caso você não tenha lido o primeiro, recomendo lê-lo e depois voltar aqui para não ficar perdido.
Conhecendo os componentes básicos explicados no post anterior, posso preparar a aplicação que mostrei para o Kubernetes.
O primeiro passo é definir quais são os Pods do meu cluster.
Embora o primeiro impulso seja colocar cada um dos contêineres em um Pod distinto e seguir em frente, esse não é necessariamente a melhor forma de defini-los. Por exemplo, em uma situação, certos contêineres têm o mesmo objetivo, ou dependem muito um do outro é uma boa ideia mantê-los juntos.
Mas para a minha aplicação, faz mais sentido um Pod por contêiner, um para o servidor HTTP e outro para o banco de dados. Como não é uma boa ideia simplesmente definir um Pod diretamente, criei dois Deployments: o node-deployment e o db-deployment.
No momento da escrita desse artigo, os Deployments ainda estavam marcados como uma versão beta, mas já são bastante usados, então é confiável.
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: "db-deployment"
spec:
replicas: 1
template:
metadata:
labels:
name: "db-pod"
spec:
containers:
- name: "db"
image: "lucassabreu/openshift-mysql-test"
ports:
- name: "mysql-port"
containerPort: 3306
env:
- name: MYSQL_DATABASE
value: appointments
- name: MYSQL_ROOT_PASSWORD
value: "root"
- name: MYSQL_USER
value: "appoint"
- name: MYSQL_PASSWORD
value: "123"
volumeMounts:
- name: "mysql-volume"
mountPath: "/var/lib/mysql"
volumes:
- name: "mysql-volume"
O primeiro Deployment é para o db-deployment. Os arquivos de configuração são simples de ler: sempre começamos o arquivo dizendo o tipo de objeto que será criado, o metadata e definimos as specs (que variam para cada tipo de componente).
Defini que preciso de apenas um Pod (réplica) e que as mesmas serão identificáveis pelas labels: name=db-pod.
Outras duas informações importantes são ports e volumeMounts.
- ports: definem quais portas deverão ser expostas no Pod e permitem que possam ser mapeadas nos Services posteriormente. Também é recomendado nomeá-las (mysql-port), assim podemos usar o nome como identificador no lugar de números.
- volumeMounts: definem todos os volumes do contêiner, dessa forma, o volume de dados do MySQL precisou ser mapeado (/var/lib/mysql).
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: "node-deployment"
spec:
replicas: 1
template:
metadata:
labels:
name: "node-pod"
spec:
containers:
- name: "node"
image: "lucassabreu/openshift-app-test"
ports:
- name: node-port
containerPort: 8080
protocol: TCP
env:
- name: DATABASE_CONNECTION
value: mysql://appoint:123@db-service:3306/appointments
O segundo Deployment é do servidor HTTP; chamei-o de node-deployment. Ele segue as mesmas regras do anterior, sendo até mais simples.
A novidade aqui é o db-service, que vou explicar agora:
apiVersion: "v1"
kind: Service
metadata:
name: "db-service"
spec:
ports:
- port: 3306
targetPort: "mysql-port"
protocol: TCP
selector:
name: "db-pod"
O db-service é o nome do Service que defini para agrupar os Pods de banco de dados; o Service ficou bem simples e basicamente tem duas partes:
- selector: define uma regra para selecionar quais Pods fazem parte do Service. No caso estou usando uma regra bem simples de name=db-pod.
- ports: permite que você mapeie as portas dos Pods para uma porta no Service, no caso estou roteando a porta de nome mysql-port para a 3306 do Service. Assim, toda chamada para db-service:3306 será direcionada para a mysql-port de um dos Pods.
apiVersion: "v1"
kind: Service
metadata:
name: "node-service"
spec:
ports:
- port: 80
targetPort: "node-port"
protocol: TCP
selector:
name: "node-pod"
O node-service segue a mesma lógica, mas para os Pods do servidor HTTP:
apiVersion: v1
kind: Route
metadata:
name: "node-route"
spec:
to:
kind: Service
name: "node-service"
Por fim, criei uma Route para expor o serviço node-service para a Internet. Eu poderia definir qual o nome de host, mas como não o fiz, o OpenShift irá gerar uma URL automaticamente para mim.
Essa URL pode ser descoberta entrando na Dashboard do OpenShift ou com o comando oc get routes:
$ oc get routes NAME HOST/PORT PATH SERVICES PORT TERMINATION node-route node-route-medium-example.44fs.preview.openshiftapps.com node-service <all>
Para aplicar as configurações no cluster, a OpenShift disponibiliza um cliente de linha de comando, que usa basicamente a mesma estrutura do kubectl, o oc. Então, tudo que precisa ser feito é executar:
oc apply -f db-deployment.yml,node-deployment.yml,db-srv.yml,node-srv.yml,node-route.yml # Ou oc apply -f db-deployment.yml oc apply -f node-deployment.yml oc apply -f db-srv.yml oc apply -f node-srv.yml oc apply -f node-route.yml
As instruções de como instalar o cliente e configurá-lo estão nesse link. Caso não queira criar os todos esses fontes, pode pegá-los aqui, ou executar:
git clone -b v1 \
https://github.com/lucassabreu/openshift-next-gen.git
Agora, no console do OpenShift deverão aparecer todos esses componentes rodando.
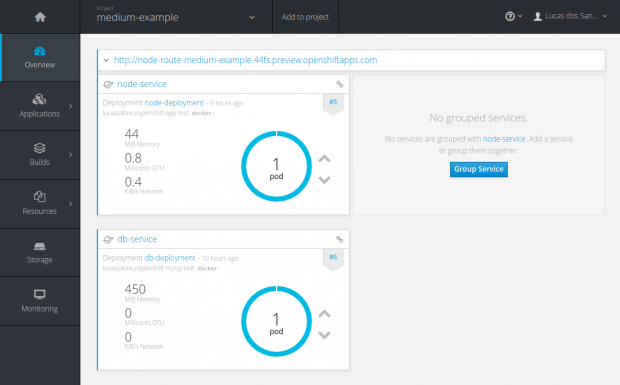
Caso esteja acompanhando as etapas, você já deve ter visto esse Dashboard, mas caso esteja apenas lendo: esse Dashboard é a tela principal dos clusters que você criar no OpenShift; basta clicar aqui, autenticar-se com o GitHub, criar um Project, e pronto! Em Overview, você verá os componentes surgirem e sumirem em tempo real, conforme vai aplicando as configurações.
Voltando… Nesse momento, temos o mesmo comportamento da aplicação local, rodando dentro do Kubernetes, empenhando o mínimo possível de configuração.
Mas existem alguns problemas no que foi definido.
O primeiro é que os db-pods estão totalmente efêmeros, ou seja, se eu adicionar novos dados nele, no momento que o Pod fosse destruído, os dados iriam junto e sem backup!
Irei mostrar como resolver esse problema no próximo artigo.
É bacharel em Sistemas de Informação pela UNIVILLE (2016). Trabalha na área desde final de 2010, trabalhou com customização para área Financeira do ERP linha Datasul e Business Intelligence na TOTVS SA. Atualmente programador na Coderockr desde 2016 com desenvolvimento de sistemas Web.



