

Formulários de login são chatos. Neste exemplo, vamos criar um formulário de login especial. Apenas para usuários felizes. A felicidade é algo complicado, mas pelo menos um sorriso é mais fácil de obter, e tudo é melhor com um sorriso. Nosso formulário de login só aparecerá se o usuário sorrir. Vamos começar.
Devo admitir que este projeto é apenas uma desculpa para brincar com diferentes tecnologias que me interessam. Semanas atrás eu descobri uma biblioteca chamada face_classification. Com essa biblioteca, eu posso executar a classificação de emoção a partir de uma imagem.
A ideia é simples. Criamos o script de servidor RabbitMQ RPC que responde com a emoção do rosto dentro de uma imagem, então obtemos o frame do fluxo de vídeo da webcam (com HTML5) e enviamos esse frame usando websocket para um servidor socket.io. Esse servidor websocket (nó) pede ao RabbitMQ RPC a emoção e envia de volta ao navegador, além da emoção, a imagem original com um retângulo sobre o rosto.
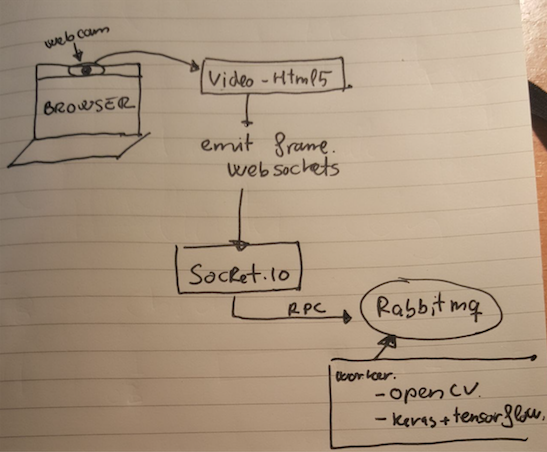
Front-end
Assim como usaremos o socket.io para websockets, utilizaremos o mesmo script para servir o frontend (o login e a captura de vídeo HTML5).
<!doctype html>
<html>
<head>
<title>Happy login</title>
<link rel="stylesheet" href="css/app.css">
</head>
<body>
<div id="login-page" class="login-page">
<div class="form">
<h1 id="nonHappy" style="display: block;">Only the happy user will pass</h1>
<form id="happyForm" class="login-form" style="display: none" onsubmit="return false;">
<input id="user" type="text" placeholder="username"/>
<input id="pass" type="password" placeholder="password"/>
<button id="login">login</button>
<p></p>
<img id="smile" width="426" height="320" src=""/>
</form>
<div id="video">
<video style="display:none;"></video>
<canvas id="canvas" style="display:none"></canvas>
<canvas id="canvas-face" width="426" height="320"></canvas>
</div>
</div>
</div>
<div id="private" style="display: none;">
<h1>Private page</h1>
</div>
<script src="https://code.jquery.com/jquery-3.2.1.min.js" integrity="sha256-hwg4gsxgFZhOsEEamdOYGBf13FyQuiTwlAQgxVSNgt4=" crossorigin="anonymous"></script>
<script src="https://unpkg.com/sweetalert/dist/sweetalert.min.js"></script>
<script type="text/javascript" src="/socket.io/socket.io.js"></script>
<script type="text/javascript" src="/js/app.js"></script>
</body>
</html>
Aqui, nos conectaremos ao websocket e emitiremos o frame da webcam para o servidor. Também ouviremos um evento chamado “response”, no qual o servidor nos notificará quando uma emoção for detectada.
let socket = io.connect(location.origin),
img = new Image(),
canvasFace = document.getElementById('canvas-face'),
context = canvasFace.getContext('2d'),
canvas = document.getElementById('canvas'),
width = 640,
height = 480,
delay = 1000,
jpgQuality = 0.6,
isHappy = false;
socket.on('response', function (r) {
let data = JSON.parse(r);
if (data.length > 0 && data[0].hasOwnProperty('emotion')) {
if (isHappy === false && data[0]['emotion'] === 'happy') {
isHappy = true;
swal({
title: "Good!",
text: "All is better with one smile!",
icon: "success",
buttons: false,
timer: 2000,
});
$('#nonHappy').hide();
$('#video').hide();
$('#happyForm').show();
$('#smile')[0].src = 'data:image/png;base64,' + data[0].image;
}
img.onload = function () {
context.drawImage(this, 0, 0, canvasFace.width, canvasFace.height);
};
img.src = 'data:image/png;base64,' + data[0].image;
}
});
navigator.getMedia = (navigator.getUserMedia || navigator.webkitGetUserMedia || navigator.mozGetUserMedia);
navigator.getMedia({video: true, audio: false}, (mediaStream) => {
let video = document.getElementsByTagName('video')[0];
video.src = window.URL.createObjectURL(mediaStream);
video.play();
setInterval(((video) => {
return function () {
let context = canvas.getContext('2d');
canvas.width = width;
canvas.height = height;
context.drawImage(video, 0, 0, width, height);
socket.emit('img', canvas.toDataURL('image/jpeg', jpgQuality));
}
})(video), delay)
}, error => console.log(error));
$(() => {
$('#login').click(() => {
$('#login-page').hide();
$('#private').show();
})
});
Backend
Finalmente, vamos trabalhar no backend. Basicamente, eu verifico os exemplos que podemos ver no projeto face_classification e ajustamos um pouco de acordo com as minhas necessidades.
from rabbit import builder
import logging
import numpy as np
from keras.models import load_model
from utils.datasets import get_labels
from utils.inference import detect_faces
from utils.inference import draw_text
from utils.inference import draw_bounding_box
from utils.inference import apply_offsets
from utils.inference import load_detection_model
from utils.inference import load_image
from utils.preprocessor import preprocess_input
import cv2
import json
import base64
detection_model_path = 'trained_models/detection_models/haarcascade_frontalface_default.xml'
emotion_model_path = 'trained_models/emotion_models/fer2013_mini_XCEPTION.102-0.66.hdf5'
emotion_labels = get_labels('fer2013')
font = cv2.FONT_HERSHEY_SIMPLEX
# hyper-parameters for bounding boxes shape
emotion_offsets = (20, 40)
# loading models
face_detection = load_detection_model(detection_model_path)
emotion_classifier = load_model(emotion_model_path, compile=False)
# getting input model shapes for inference
emotion_target_size = emotion_classifier.input_shape[1:3]
def format_response(response):
decoded_json = json.loads(response)
return "Hello {}".format(decoded_json['name'])
def on_data(data):
f = open('current.jpg', 'wb')
f.write(base64.decodebytes(data))
f.close()
image_path = "current.jpg"
out = []
# loading images
rgb_image = load_image(image_path, grayscale=False)
gray_image = load_image(image_path, grayscale=True)
gray_image = np.squeeze(gray_image)
gray_image = gray_image.astype('uint8')
faces = detect_faces(face_detection, gray_image)
for face_coordinates in faces:
x1, x2, y1, y2 = apply_offsets(face_coordinates, emotion_offsets)
gray_face = gray_image[y1:y2, x1:x2]
try:
gray_face = cv2.resize(gray_face, (emotion_target_size))
except:
continue
gray_face = preprocess_input(gray_face, True)
gray_face = np.expand_dims(gray_face, 0)
gray_face = np.expand_dims(gray_face, -1)
emotion_label_arg = np.argmax(emotion_classifier.predict(gray_face))
emotion_text = emotion_labels[emotion_label_arg]
color = (0, 0, 255)
draw_bounding_box(face_coordinates, rgb_image, color)
draw_text(face_coordinates, rgb_image, emotion_text, color, 0, -50, 1, 2)
bgr_image = cv2.cvtColor(rgb_image, cv2.COLOR_RGB2BGR)
cv2.imwrite('predicted.png', bgr_image)
data = open('predicted.png', 'rb').read()
encoded = base64.encodebytes(data).decode('utf-8')
out.append({
'image': encoded,
'emotion': emotion_text,
})
return out
logging.basicConfig(level=logging.WARN)
rpc = builder.rpc("image.check", {'host': 'localhost', 'port': 5672})
rpc.server(on_data)
Aqui você pode ver o protótipo de trabalho em ação:
Talvez possamos fazer o mesmo com outras ferramentas e de forma ainda mais simples, mas como eu disse antes, este exemplo é apenas uma desculpa para brincar com estas tecnologias:
- Enviar frames da webcam via websockets
- Conectar um aplicativo web a um aplicativo Python via RabbitMQ RPC
- Brincar com script de classificação de rosto
Por favor, não use esse script em produção. É apenas uma prova de conceitos. Com sorrisos, mas uma prova de conceitos.
Você pode ver o projeto na minha conta do GitHub.
***
Gonzalo Ayuso faz parte do time de colunistas internacionais do iMasters. A tradução do artigo é feita pela Redação iMasters, com autorização do autor, e você pode acompanhar o artigo em inglês no link: https://gonzalo123.com/2018/05/07/happy-logins-only-the-happy-user-will-pass/

De 0 a 10, o quanto você recomendaria este artigo para um amigo?