

Um dos primeiros artigos no meu site foi sobre tabelas dinâmicas. Eu criei uma biblioteca para dinamizar tabelas em meus scripts PHP.
A biblioteca não é muito bonita (lança muitos alertas), mas funciona. Atualmente estou brincando com análise de dados em Python e usando Pandas.
O objetivo deste artigo é algo que gosto muito: aprender fazendo. Eu quero fazer as mesmas operações que fiz há oito anos no texto, mas agora com Pandas.
Vamos começar!
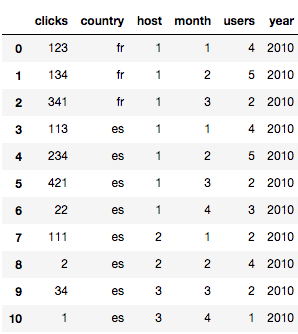
Começarei com a mesma fonte de dados que usei há quase 10 anos. Um simples conjunto de registros com cliques e número de usuários.
Eu crio um dataframe com estes dados:
import numpy as np
import pandas as pd
data = pd.DataFrame([
{'host': 1, 'country': 'fr', 'year': 2010, 'month': 1, 'clicks': 123, 'users': 4},
{'host': 1, 'country': 'fr', 'year': 2010, 'month': 2, 'clicks': 134, 'users': 5},
{'host': 1, 'country': 'fr', 'year': 2010, 'month': 3, 'clicks': 341, 'users': 2},
{'host': 1, 'country': 'es', 'year': 2010, 'month': 1, 'clicks': 113, 'users': 4},
{'host': 1, 'country': 'es', 'year': 2010, 'month': 2, 'clicks': 234, 'users': 5},
{'host': 1, 'country': 'es', 'year': 2010, 'month': 3, 'clicks': 421, 'users': 2},
{'host': 1, 'country': 'es', 'year': 2010, 'month': 4, 'clicks': 22, 'users': 3},
{'host': 2, 'country': 'es', 'year': 2010, 'month': 1, 'clicks': 111, 'users': 2},
{'host': 2, 'country': 'es', 'year': 2010, 'month': 2, 'clicks': 2, 'users': 4},
{'host': 3, 'country': 'es', 'year': 2010, 'month': 3, 'clicks': 34, 'users': 2},
{'host': 3, 'country': 'es', 'year': 2010, 'month': 4, 'clicks': 1, 'users': 1}
])
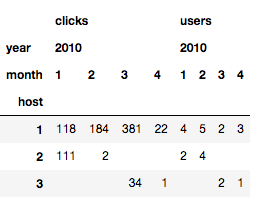
Agora queremos fazer uma operação dinâmica simples – queremos dinamizar no host.
pd.pivot_table(data,
index=['host'],
values=['users', 'clicks'],
columns=['year', 'month'],
fill_value=''
)
Podemos adicionar totais.
pd.pivot_table(data,
index=['host'],
values=['users', 'clicks'],
columns=['year', 'month'],
fill_value='',
aggfunc=np.sum,
margins=True,
margins_name='Total'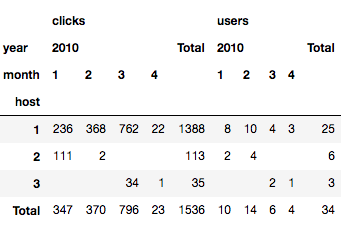
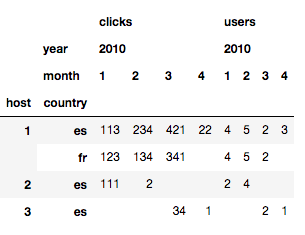
Também podemos dinamizar em mais de uma coluna. Por exemplo: host e country.
pd.pivot_table(data,
index=['host', 'country'],
values=['users', 'clicks'],
columns=['year', 'month'],
fill_value=''
)
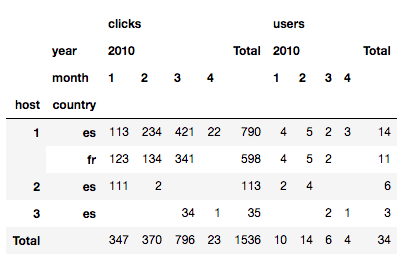
E também totais.
pd.pivot_table(data,
index=['host', 'country'],
values=['users', 'clicks'],
columns=['year', 'month'],
aggfunc=np.sum,
fill_value='',
margins=True,
margins_name='Total'
)
Podemos agrupar por dataframe e calcular subtotais.
data.groupby(['host', 'country'])[('clicks', 'users')].sum()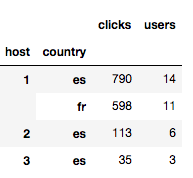
data.groupby(['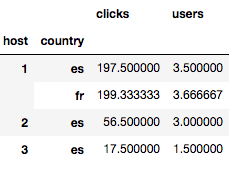
E finalmente podemos misturar totais e subtotais.
out = data.groupby('host').apply(lambda sub: sub.pivot_table(
index=['host', 'country'],
values=['users', 'clicks'],
columns=['year', 'month'],
aggfunc=np.sum,
margins=True,
margins_name='SubTotal',
))
out.loc[('', 'Max', '')] = out.max()
out.loc[('', 'Min', '')] = out.min()
out.loc[('', 'Total', '')] = out.sum()
out.index = out.index.droplevel(0)
out.fillna('', inplace=True)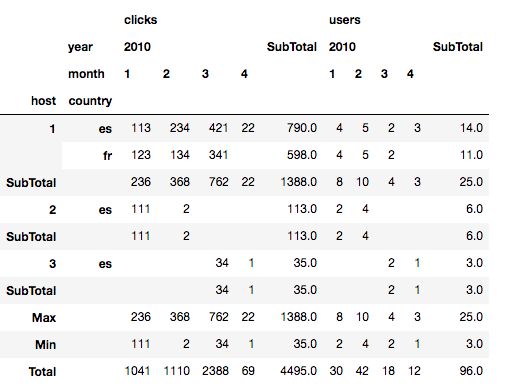
E isso é tudo. Muito para aprender ainda sobre análise de dados, mas Pandas será definitivamente um bom amigo meu.
Você pode ver o notebook Jupiter na minha conta do GitHub.
***
Gonzalo Ayuso faz parte do time de colunistas internacionais do iMasters. A tradução do artigo é feita pela Redação iMasters, com autorização do autor, e você pode acompanhar o artigo em inglês no link: https://gonzalo123.com/2019/03/11/data-analysis-with-python-pivot-tables-with-pandas/

De 0 a 10, o quanto você recomendaria este artigo para um amigo?