

Ultimamente vim pensando a respeito de lançar o blog e começar escrevendo um artigo sobre como criar um web service RESTful, mas antes disso, conversando num hangout com alguns outros devs, percebi que antes do “como fazer”, seria bacana um “o que é”, para mostrar os fundamentos e os conceitos por trás da arquitetura REST. A grande discussão na ocasião era: até que ponto vale a pena usar um grande esforço para tornar a sua aplicação RESTful.
Primeiramente, gostaria de falar o que este artigo NÃO é: este artigo não tem como objetivo mostrar o porquê de usar REST ao invés de usar SOAP ou qualquer outro protocolo/arquitetura para construir sua API. Este artigo tem como principal objetivo, na verdade, deixar claro o que é o REST; quais as vantagens de usar esta arquitetura; o que faz da sua API ser considerada RESTful e o porquê muitas dizem que são, mas na verdade não são.
Vamos lá.
O que é REST?
O termo foi definido no ano 2000, na tese de doutorado de Roy Fielding e é a sigla para Representational State Transfer: é um design de arquitetura construído para servir aplicações em rede. A aplicação mais comum de REST é a própria World Wide Web, que utilizou REST como base para o desenvolvimento do HTTP 1.1.
REST traz uma série de benefícios – que irei falar logo mais – mas ele não é um padrão, você não é obrigado a seguí-lo para construir seus web services ou aplicação web, ele é apenas uma espécie de guia com algumas recomendações.
Este tema é muito comentado quando falamos em construção de web services, mas este não é um modelo de arquitetura específico para construção de APIs somente, ele pode – E DEVE – ser utilizado na construção de sistemas web que não serão expostos na forma de API necessariamente.
As restrições do REST
1. Client-Server
É a restrição básica para uma aplicação REST. O objetivo desta divisão é separar a arquiterura e responsabilidades em dois ambientes. Assim, o cliente (consumidor do serviço) não se preocupa com tarefas do tipo: comunicação com banco de dados, gerenciamento de cache, log, etc. E o contrário também é válido, o servidor (provedor do serviço) não se preocupa com tarefas como: interface, experiência do usuário, etc. Permitindo, assim, a evolução independente das duas arquiteturas.
Neste modelo, o servidor espera pelas requisições do cliente, executa estas requests e devolve uma resposta.

2. Stateless
Um mesmo cliente pode mandar várias requisições para o servidor, porém, cada uma delas devem ser independentes, ou seja, toda requisição deve conter todas as informações necessárias para que o servidor consiga entendê-la e processá-la adequatamente.
Neste caso, o servidor não deve guardar nenhuma informação a respeito do estado do cliente. Qualquer informação de estado deve ficar no cliente, como as sessões, por exemplo.
3. Cacheable
Como muitos clientes acessam um mesmo servidor, e muitas vezes requisitando os mesmos recursos, é necessário que estas respostas possam ser cacheadas, evitando processamento desnecessário e aumentando significativamente a performance.
Isso significa que um primeiro cliente solicita um determinado resource para o servidor, o servidor processa esta requisição e armazena isso temporariamente no cache. Quando os demais clientes solicitam o mesmo resource, o servidor devolve o que está no cache sem ter que reprocessá-lo. A regra para limpar o cache varia de resource para resource, pode ser limpo sempre que houver uma troca de estado no resource; pode ser limpo em um determinado intervalo de tempo antes de ser reprocessado, de hora em hora, por exemplo, e por aí vai.
4. Uniform Interface
É, basicamente, um contrato para comunicação entre clientes e servidor. São pequenas regras para deixar um componente o mais genérico possível, o tornando muito mais fácil de ser refatorado e melhorado.
Dentro desta regra, existe uma espécie de guideline para fazer essa comunicação uniforme:
1) Identificando o resource – cada resource deve ter uma URI específica e coesa para poder ser acessado, por exemplo, para trazer um determinado usuário cadastrado no site:
HTTP/1.1 GET http://rplansky.com/user/rplansky
2) Representação do resource – é a forma como o resource vai ser devoldido para o cliente. Esta representação pode ser em HTML, XML, JSON, TXT, entre outras. Exemplo de como seria um retorno simples da chamada acima:
{
"name": "Ricardo Plansky",
"job": "Web Analyst/Developer",
"hobbies": ["football", "coding", "music"]
}
3) Resposta auto-explicativa – além do que vimos até agora, é necessário a passagem de meta informações (metadata) na requisição e na resposta. Algumas destas informações são: código HTTP da resposta, Host, Content-Type, etc. Tendo como exemplo a mesma URI que acabamos de ver:
GET /#!/users/rplansky HTTP/1.1 User-Agent: Chrome/37.0.2062.94 Accept: application/json Host: rplansky.com
4) Hypermedia – Esta parte por muitas vezes é esquecida quando falamos de REST. Consiste em retornar todas as informações necessárias na resposta para que cliente saiba navegar e ter acesso a todos os resources da aplicação. Não vou prolongar neste item que será o assunto do próximo post. Apenas um exemplo:
Requisição
HTTP/1.1 POST http://rplansky.com/rplansky/posts
Resposta
{
"post": {
"id": 42,
"title": "Conceitos REST",
"decription": "Um pouco sobre conceito da arquitetura REST",
"_links": [
{
"href": "/rplansky/post/42",
"method": "GET",
"rel": "self"
},
{
"href": "/rplansky/post/42",
"method": "DELETE",
"rel": "remove"
},
{
"href": "/rplansky/post/42/comments",
"method": "GET",
"rel": "comments"
},
{
"href": "/rplansky/posts/42/comments",
"method": "POST",
"rel": "new_comment"
},
{...}
]
},
"_links": {
"href": "/post",
"method": "GET",
"rel": "list"
}
}
5. Layered System
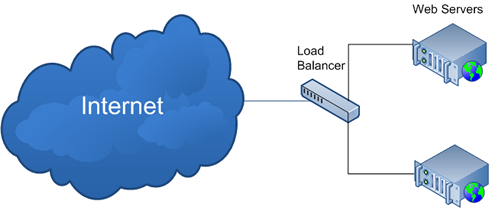
A sua aplicação deve ser composta por camadas, e estas camadas devem ser fáceis de alterar, tanto para adicionar mais camadas, quanto para removê-las. Dito isso, um dos princípios desta restrição é que o cliente nunca deve chamar diretamente o servidor da aplicação sem antes passar por um intermediador, no caso, pode ser um load balancer ou qualquer outra máquina que faça a interface com o(s) servidor(es). Isso garante que o cliente se preocupe apenas com a comunicação com o intermediador e o intermediador fica responsável por distribuir as requições nos servidores, seja um ou mais, indifere nesse caso. O importante é ficar claro que criando um intermediador, a sua estrutura fica muito mais flexível à mudanças.
6. Code-On-Demand (Opcional)
Esta condição permite que o cliente possa executar algum código sob demanda, ou seja, estender parte da lógica do servidor para o cliente, seja através de um applet ou scripts. Assim, diferentes clientes podem se comportar de maneiras específicas mesmo que utilizando exatamente os mesmos serviços providos pelo servidor.
Como este item não faz parte da arquitetura em si, ele é considerado opcional. Ele pode ser utilizado quando executar alguma parte do serviço do lado do cliente for mais eficaz ou rápida.
E o que é RESTful?
Muita gente, quando usa diferentes URIs, verbos HTTP e diferentes formatos de retorno, passa a dizer que tem uma API RESTful. Tudo isso é muito importante e faz parte, mas não é apenas isso que compõe o RESTful.
Para uma API ser considerada RESTful ela deve seguir estritamente as regras definidas na arquitetura REST (com exceção da 6, obviamente, que é opcional), além de possuir um certo nível de coesão e maturidade, definidos na escala chamada de Richardson Maturity Model.
Falarei no próximo artigo mais detalhadamente sobre como construir na prática uma API RESTful seguindo este modelo. Mas para dar uma breve noção, os níveis são:
Nível 0: Resumidamente é a ausência de qualquer regra, é apenas a utilização do HTTP como transporte das operações no servidor. Normalmente se usa apenas um endpoint (URI) e um verbo HTTP.
Nível 1: Aplicação de resources. A API é dividida em diferentes endpoints que apontam para um ou mais resources.
Nível 2: Implementação de verbos HTTP para diferentes tipos de operações que deseja executar. Uma mesma URI por aceitar mais de um verbo HTTP, por exemplo: GET /user pode retornar todos os usuários e POST /user passando os atributos do usuário pode criar um novo.
Nível 3: Um novo conceito é adicionado, chamado: HATEOAS (Hypertext As The Engine Of Application State). Onde a API deve fornecer para o cliente toda a informação necessária para interagir com a aplicação.
Conclusão
REST é um modelo de arquitetura bem definido para servir aplicações web. Ele já oferece todo o guideline necessário para construirmos um serviço coeso, escalável e performático – e não é difícil. No dia-a-dia nós já utilizamos muitas das recomendações do REST: client-server, cache, stateless, etc. Para passarmos a ser RESTful, é apenas uma questão de se policiar e botar em prática alguns novos passos, até que tudo se torne automático. Seguir este modelo de arquitetura nos permite se preparar para o crescimento do serviço sem grandes impactos, além de oferecer aos clientes da aplicação um modelo que é de conhecimento comum, intuitivo até, evitando a necessidade de fazê-lo entender sobre uma nova arquitetura para consumir o serviço.
Em breve falo um pouco mais de REST… na prática.
Referências

De 0 a 10, o quanto você recomendaria este artigo para um amigo?