



Criando Aplicações Resilientes: uma visão geral
Quer saber o que são as chamadas Aplicações Resilientes? Neste artigo de Maicon Carlos Pereira você conhece os principais conceitos e aprende a criá-las.


O que é resiliência? Se procurarmos por uma definição no dicionário (Google), veremos:
- Na física: propriedade que alguns corpos apresentam de retornar à forma original após terem sido submetidos a uma deformação elástica.
- No sentido figurado: é capacidade de se recobrar facilmente ou se adaptar à má sorte ou às mudanças.
Nesta série de artigos trataremos de resiliência como:
- Capacidade da aplicação de se recuperar de falhas e continuar a funcionar
Dizemos que:
No melhor cenário, a aplicação se recupera sem o usuário/cliente perceber. No pior cenário, a aplicação oferece serviços de forma limitada (que chamamos de graceful degradation).
Falhas
As falhas em sistemas distribuídos podem ser classificadas de acordo com sua duração em:
- Transientes: ocorrem uma vez e desaparecem com curta duração. Se você repetir a operação é provável que terá sucesso
- Intermitentes: falhas transientes que ocorrem repetidamente. Elas acontecem e desaparecem por “vontade própria”
- Permanentes: são as falhas que permanecerão até que alguma ação seja tomada como, por exemplo, trocar um equipamento ou corrigir o software
Também podemos classificar essas falhas segundo seu comportamento:
- Travamento ou queda: o recurso parou de funcionar devido a um travamento ou perda do estado interno
Omissão: o recurso não responde às requisições - Temporização: as respostas estão fora da sincronia esperada
- Bizantinas ou Aleatórias: o recurso responde de forma totalmente arbitrária
Por vezes, quando projetamos e desenvolvemos nossos sistemas, não levamos em consideração que eles poderão falhar.
Peter Deutsch e James Gosling elencaram oito itens que normalmente são assumidos como verdadeiros em projetos de sistemas distribuídos e que a longo prazo se mostram errados e podem resultar em problemas (oito falácias de sistemas distribuídos). São eles:
- A rede é de confiança
- Latência é zero
- Largura de banda é infinita
- A rede é segura
- A topologia não muda
- Há somente um administrador
- Custo de transporte é zero
- A rede é homogênea
Microsserviços
Está cada vez mais comum a construção de aplicações baseadas em arquitetura microsserviços ou a migração de monolíticos para essa arquitetura. A arquitetura de microsserviços tem promessas interessantes – entre elas é favorecer a alta disponibilidade.
Porém, uma arquitetura de microsserviços com erros de modelagem em que existirem muitas chamadas HTTP encadeadas sincronamente, pode levar a um cenário oposto.
Vejam a imagem e os cenários a seguir, sendo simplista, mas com o propósito de demostrar essa questão.
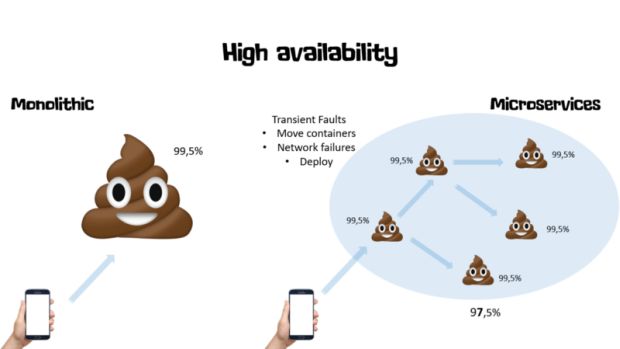
- Monolítico: um servidor tem uma disponibilidade calculada em 99.5% para servir um sistema monolítico
- Microsserviços: Cinco servidores, também com 99.5% de disponibilidade cada. Porém, nessa arquitetura um serviço faz chamadas encadeadas e síncronas a outros serviços. Logo, acrescenta outros pontos de falhas e a disponibilidade do sistema se dá pelo fato da disponibilidade de todos os serviços envolvidos. Neste cenário, será 97.5%, sendo menor que a disponibilidade do cenário Monolítico.
Em microsserviços, as falhas podem ser diversas, desde falhas em hardware a movimentações de contêineres entre nós.
A questão que alguns podem ter é mesmo com uma disponibilidade alta como as dos nossos cenários. As falhas realmente podem acontecer? Devo me preocupar com isso?
Logo, não é uma questão de “se as falhas vão acontecer”, mas sim “quando elas vão acontecer”.
O livro “.NET Microservices: Architecture for Containerized .NET Applications”, diz:
- A falha intermitente é garantida em um sistema distribuído e baseado em nuvem, mesmo quando cada dependência tem uma disponibilidade excelente. Esse é um fato que você precisa considerar.
Conclusão
Ser resiliente é aceitar que falhas irão acontecer e tratá-las da melhor maneira.
Nos próximos artigos veremos padrões aplicáveis à software para construir aplicações resilientes.
Deixe seu feedback e acompanhe a série!
Graduado em Ciência da Computação e MBA em Gerenciamento de Projetos, Scrum Master Professional. Com mais de 12 anos no mundo de desenvolvimento de software, atualmente atuando como especialista em engenharia de software na Ti da Patrus Transportes.



