



Top 10 hacks de SQL para machine learning
Neste artigo, descrevo algumas técnicas avançadas de TSQL para lidar com dados antes de partir para o Machine Learning.

A linguagem SQL é o recurso computacional mais utilizado para lidar com dados. Neste artigo, descrevo algumas técnicas avançadas de TSQL para lidar com dados antes de partir para o Machine Learning.
A manipulação de dados antes da aplicação de diversos algoritmos de machine learning é muito comum. De fato, não é raro ouvir que aproximadamente 70% ou mais do tempo gasto em projetos de data science é apenas manipulando dados antes de efetivamente aplicar algum algoritmo de machine learning.
Existem várias tecnologias, linguagens e recursos para manipular os dados. Contudo, quando falamos de Big Data, faz muito sentido ter o suporte de um banco de dados em algum momento, uma vez que será preciso lidar com quantidades de dados que muitas vezes não cabem na memória. Portanto, é razoável admitir que a manipulação dos dados envolva a linguagem SQL caso bancos de dados relacionais estejam envolvidos no projeto.
Como já tenho uma boa experiência em SQL Server, resolvi compartilhar alguns dos meus “hacks” de código TSQL que mais vêm me ajudando nos projetos. Obviamente estas manipulações de dados podem ser feitas de diversas maneiras (algumas até mais otimizadas do que os códigos deste artigo) e com diferentes linguagens.
Antes de apresentar o top 10, aproveito para citar o meu curso de introdução ao Machine Learning com Python. Este curso apresenta diversas manipulações de dados também, uma vez que o conteúdo é muito focado na parte prática. As inscrições já estão acabando para turma de novembro, mas acredito que ainda dê tempo de fechar algumas vagas acessando este link.
1. Importação com o BULK INSERT

Quando se trabalha com machine learning, é quase certo que será necessário lidar com arquivos texto mais cedo ou mais tarde. O formato mais comum de dados em arquivo texto é o CSV (comma separated values), no qual, cada linha é separada por um conjunto de caracteres de final de linha (tipicamente o CR+LF) e cada coluna da linha é separada por outro caractere (tipicamente a vírgula).
Não gosto muito de utilizar o assistente de importação do SQL Server para lidar com arquivos CSV porque ele sempre me dá algum erro na importação. Portanto, para lidar rapidamente com a importação de dados neste formato, eu faço as seguintes passos:
- Inicializo o assistente de importação do SQL Server e indico que quero importar dados de um arquivo texto (flat file) para o SQL Server. Sigo o assistente até a tela de mapeamento, onde copio o comando CREATE TABLE gerado pela ferramenta e cancelo o assistente;
- Altero manualmente o comando CREATE TABLE gerado para colocar varchar(4000) em todas as colunas. Assim, consigo importar os dados primeiro e me preocupar com a conversão de tipos depois;
- Crio a tabela com o comando CREATE TABLE;
- Executo o comando BULK INSERT e importo os dados. Algo como o código abaixo:
BULK INSERT MeuBanco.dbo.MinhaTabela FROM 'c:\ArquivoDados.csv' WITH ( FIELDTERMINATOR = ',', ROWTERMINATOR = '\n' );
- Monto uma instrução SELECT que lê os dados importados da tabela e faço a conversão de cada coluna para um tipo de dados adequado. Este SELECT contém a cláusula INTO para gerar uma tabela já com os tipos certos que serão utilizada nas análises.
2. Leitura rápida de arquivos CSV

Algumas vezes preciso observar rapidamente o conteúdo de um arquivo CSV diretamente em uma instrução SELECT antes de fazer a importação. Esta observação rápida geralmente é feita em arquivos pequenos só para verificar as primeiras linhas do cabeçalho ou algo assim.
Para estes casos, utilizo a função OPENROWSET() com as opções BULK e SINGLE_CLOB. Este tipo de operação não separa em linhas e colunas o conteúdo, mas ajuda quando preciso dar aquela olhada esperta nos dados antes de prosseguir com a importação. Exemplo:
SELECT a.* FROM OPENROWSET( BULK 'E:\temp\teste1.csv', SINGLE_clob) AS a;
3. Mediana e moda
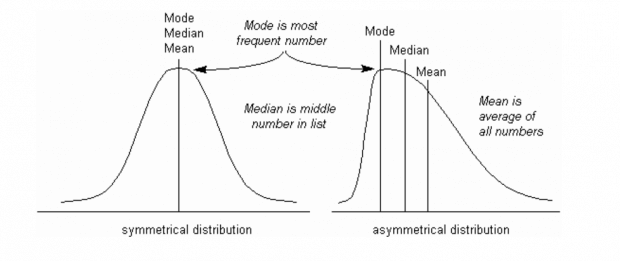
O SQL Server possui uma função de agregação para o cálculo da média (AVG()), porém não existe algo pronto para o cálculo da mediana ou moda. Estas duas métricas são importantes, especialmente quando se está analisando a distribuição de frequência de valores de atributos. De fato, se os valores da média, mediana e moda forem muito diferentes, isso significa que a distribuição está “inclinada” para a esquerda ou direita e isso diz algo importante sobre os dados.
O cálculo da moda é simples: basta fazer um SELECT com uma agregação e obter a primeira linha com a cláusula top através da ordenação decrescente. Por exemplo, para obter a moda da tabela TB_DADOS que contém a coluna VALOR basta executar o comando abaixo:
SELEC TOP 1 VALOR, COUNT(VALOR) FROM TB_DADOS ORDER BY COUNT(VALOR) DESC
Já a mediana é um pouco mais complicada. Vasculhando na internet, encontrei a solução abaixo que faz alguns SELECTs na mesma tabela com o uso da cláusula TOP PERCENT.
SELECT ( (SELECT MAX(VALOR) FROM (SELECT TOP 50 PERCENT VALOR FROM TB_DADOS ORDER BY VALOR) AS BottomHalf) + (SELECT MIN(VALOR) FROM (SELECT TOP 50 PERCENT VALOR FROM TB_DADOS ORDER BY VALOR) AS TopHalf) ) / 2.0 AS Mediana
A referência do script acima é esta pergunta no StackOverflow.
4. Contando e separando valores

Certos valores de colunas com caracteres possuem alguns delimitadores que devem ser separados para obter os dados no formato tabular. Esta operação de separar os dados chama-se slipt e existem diversas maneiras de se fazer isso no SQL Server. Este link contêm vários exemplos de como isso pode ser feito para, por exemplo, transformar a string “a,b,c” em um resultado tabular com uma linha e três colunas.
Em alguns casos, também é útil contar a quantidade de repetição de certos caracteres. Para isso, utilizo uma expressão rápida que é a subtração da quantidade total de caracteres do tamanho de uma segunda string. Esta segunda string é gerada trocando o caractere que desejo contar da string original pela string vazia. Por exemplo, se desejo contar a quantidade de letras ‘a’ da coluna NOME da tabela TB_DADOS, eu faria algo como:
SELECT NOME, LEN(NOME) – LEN(REPLACE(NOME,’a’,’’)) as QTD_LETRAS_A FROM TB_DADOS
5. Processamento para cada coluna

A etapa de exploração dos dados muitas vezes requer que façamos cálculos para cada um dos atributos, especialmente se possuirmos conjuntos de dados com vários atributos. Este tipo de tarefa pode ser maçante e muito chata se não for otimizada, pois teríamos que digitar cada nome das colunas em diversas instruções.
Quando me deparo com este tipo de situação, eu emprego a seguinte técnica: faço um SELECT que vai gerar diversas instruções SQL dinamicamente como uma string. Este SELECT utiliza a tabela de sistema sys.all_columns que contêm a coluna name, responsável por armazenar o nome da coluna. Depois que o SELECT for retornado, eu copio e colo (CTRL+C e CTRL+V) o resultado da coluna calculada e mando executar.
Como exemplo, vamos supor que desejamos executar um agregação para ver frequência de valores para cada coluna da tabela TB_DADOS. Para isso podemos gerar as diversas instruções SELECT que fazem uso do COUNT() a partir do SELECT abaixo.
SELECT 'SELECT ''' + NAME + ''''
+ ' , COUNT(*) AS TOTAL'
+ ' FROM TB_DADOS'
FROM SYS.all_columns
WHERE OBJECT_ID = OBJECT_ID('TB_DADOS')
6. Aleatoriedade e Split

Muitas vezes precisamos gerar uma quantidade X de valores da tabela de forma aleatória. Esta operação é muito comum quando precisamos fazer o split dos dados e separá-los em conjuntos de treinamento e testes. Muitas ferramentas de machine learning possuem diversos recursos para fazer esta tarefa, mas com o TSQL podemos utilizar a cláusula TOP PERCENT para limitar o percentual de dados retornados. Já para gerar aleatoriedade podemos utilizar a cláusula ORDER BY junto com a função NEWID().
Por exemplo, se desejarmos separar os dados tabela TB_DADOS com as colunas ID e VALOR em um split aleatório de 80% de dados de treinamento e 20% de teste podemos fazer algo com o SELECT abaixo, que utiliza uma tabela temporária chamada #T_AUX.
/* Primeiro os 80% de treinamento */ SELECT TOP 80 PERCENT ID, DADOS INTO #T_AUX FROM TB_DADOS ORDER BY NEWID() /* Agora os 20% restantes */ SELECT * FROM DADOS WHERE ID NOT IN (SELECT ID FROM #T_AUX)
7. Gerando ids
![]()
A geração de colunas com valores identificadores é algo muito comum no Machine Learning, uma vez que a maioria dos algoritmos trabalha apenas com valores numéricos para os atributos. No SQL Server é possível fazer isso rapidamente criando uma nova coluna do tipo numérico na tabela que possua a propriedade IDENTITY, como o exemplo abaixo mostra.
ALTER TABLE TB_DADOS ADD NOVO_ID INT IDENTITY(1,1)
É importante destacar que o comando acima cria uma nova coluna e já coloca os valores numerados sequencialmente. Dependendo da necessidade, pode ser preciso gerar os valores sem alterar a tabela e para isso recomendo o SELECT abaixo que usa a cláusula OVER() junto com a função ROW_NUMBER() para criar novos ids para a uma coluna chamada VALOR a partir uma tabela fictícia, chamada TB_DADOS
SELECT ROW_NUMBER() OVER (ORDER BY A.VALOR) AS NOVO_ID , A.VALOR FROM ( SELECT DISTINCT VALOR FROM TB_DADOS) AS A
8. RMSE
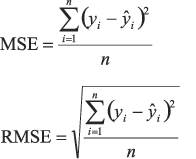
A sigla RMSE (Root Mean Square Error) representa uma métrica importante quando estamos lidando com regressão. Ela é utilizada para verificar o quão “boa” é a sua previsão e faz o papel de outras métricas empregadas para verificar a qualidade de modelos que fazem classificação.
Em geral, utilizamos a RMSE na comparação entre técnicas de regressão e aquela que tiver o melhor valor para esta métrica potencialmente pode ser empregada. Para calcular a RMSE, basta ter uma sequência de números em uma tabela. Infelizmente, o SQL Server não possui recursos próprios para o cálculo do RMSE, mas encontrei este script que faz o cálculo utilizando um CTE em conjunto com a cláusula OVER. No exemplo abaixo calculo o RMSE utilizando de uma tabela temporária chamada #NUMBERS que possui a coluna NUMBER.
WITH nums AS ( SELECT NUMBER, ROW_NUMBER() OVER (ORDER BY NUMBER) AS rn FROM #NUMEROS ) SELECT SQRT(AVG(POWER(np.NUMBER - nn.NUMBER, 2))) FROM nums np JOIN nums nn ON nn.rn = np.rn + 1
9. Cálculo de correlações

A correlação entre dois grupos de valores é uma das mais importantes tarefas quando se está analisando o impactado das features em um modelo de machine learning. Esta importância se deve ao fato que quando descobrimos correlações significativas podemos, entre outras tarefas, reduzir a quantidade de features do nosso modelo e talvez otimizar o processo de treinamento.
Entre as várias métricas de correção, podemos citar o coeficiente de Person, ANOVA, GINI, Information Gain e outros. O SQL Server não possui recursos próprios para isso, mas existe um pacote de assemblies do .NET muito bom que pode ajudar: o TotallySQL. Este pacote é software livre e possui diversos recursos e o subconjunto de assemblies .NET que calcula as correlações está agrupado na namesspace SQLStatics. Recomendo a instalação deste componente para quem está pensando em cálculos mais avançados dentro do SQL Server.
10. Gerando dados com uma distribuição normal
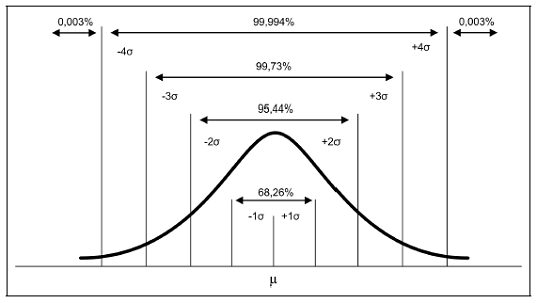
A distribuição normal (também chamada gaussiana) é muito utilizada em projetos de data science, especialmente quando precisamos gerar rapidamente uma base de números a partir de algumas características. Uma vez com esta base de teste podemos testar alguns algoritmos e verificar se está tudo OK.
Os parâmetros necessários para gerar dados de acordo com uma distribuição normal são a média e o desvio padrão. Para gerar rapidamente os dados no SQL Server eu utilizo o script abaixo adaptado do post escrito por Phil Factor no site Simple-Talk, uma ótima referência para conteúdo do SQL Server. Destaco que pode ser necessário converter o tipo de dados, pois muitas vezes o float obtido pelo script pode gerar problemas de arredondamento indesejados.
/* CRIANDO AS VARIÁVEIS */ /* TABELA NA MEMÓRIA COM A SEQUÊNCIA DE NÚMEROS */ /* DE ACORDO COM A DISTRIBUIÇÃO NORMAL */ DECLARE @RANDOMNUMBERS TABLE (NUMBER FLOAT) DECLARE @MEAN FLOAT /* A MÉDIA */ DECLARE @STANDARDDEVIATION FLOAT /* O DESVIO PADRÃO */ DECLARE @II INT /* CONTADOR */ DECLARE @TOTALWANTED INT /* A QUANTIDADE DE NÚMEROS DESEJADA */ /* COLOQUE AQUI OS VALORES DA MÉDIA, DESV. PADRÃO */ /* E TOTAL DE LINHAS DESEJADAS */ SELECT @MEAN=2.8, @STANDARDDEVIATION=0.5, @II=1, @TOTALWANTED=10000; /* GERANDO OS VALORES EM UM LOOP */ WHILE @II<= @TOTALWANTED BEGIN INSERT INTO @RANDOMNUMBERS(NUMBER) SELECT ((RAND()*2-1)+(RAND()*2-1)+(RAND()*2-1))*@STANDARDDEVIATION+@MEAN; SELECT @II=@II+1; END /* CONSULTANDO OS VALORES GERADOS */ SELECT * FROM @RANDOMNUMBERS
v
Mauro Pichiliani é bacharel em Ciência da Computação, Mestre e doutorando em computação pelo ITA (Instituto Tecnológico de Aeronáutica). Trabalha há mais de 10 anos utilizando diversos bancos de dados e ferramentas de programação. Pode ser contatato no twitter como @pichiliani e no e-mail pichiliani@gmail.com


