



Hekaton, você está por dentro?
A Microsoft anunciou o pré-lançamento do SQL Server 2014 CTP1. O HEKATON é um dos “personagens” mais esperado neste lançamento.

A Microsoft anunciou o pré-lançamento do SQL Server 2014 CTP1 com várias novidades e algumas com certeza vieram para quebrar paradigmas. O HEKATON é um dos “personagens” mais esperado neste lançamento, e vai quebrar algumas barreiras e mudar a forma de trabalhar e pensar em banco de dados.
Bom, mas o que é esse tal de Hekaton? É um novo recurso do SQL Server 2014 para ambientes OLTP, que possibilita trabalhar com banco de dados em memória, o famoso in memory. Onde nesse novo “mundo” não existe mais latches, locks e bloqueios em processamento de escrita e leitura com uma velocidade extremamente “violenta”.
Com essa nova engine é possível colocar tabelas em memória, ou seja, elas são realmente criadas em memória, o que é diferente do CACHE, onde a tabela é criada em disco e depois os dados são alocados em memória (CACHE).
Utilizando esta tabela otimizada, podemos ganhar muito desempenho podendo, em alguns casos, alcançar trinta vezes mais performance comparado com operações realizadas em tabelas alocadas em disco. O interessante é que podemos escolher quais tabelas vão ser otimizadas e não obrigatoriamente o banco inteiro precisa ser colocado em memória.
Como funciona
Com a nova engine, as tabelas que são otimizadas em memória passam a não utilizar mais arquitetura B-TRE e sim um Hash Key. Como assim?
Agora cada registro armazenado recebe um Hash Key, que é uma chave única para o registro. Na arquitetura B-TRE, quando é feita uma requisição, é necessário navegar pelos níveis do índice a partir do ROOT até encontrar o registro desejado e, caso esteja utilizando um índice non-clustered e exista algum campo na consulta que não faça parte desse índice, é necessário ir para o índice clustered e buscar esse campo, forçando o Key Lookup, que “custa” muito para o SQL Server retornar o resultado. Com a nova engine, o Hekaton armazena os dados em slots que chamamos de Buckets e para cada novo registro se aplica a função de hash, que armazena esse registro em Buckets, assim, quando for feita a requisição, a busca é feita pelo hash e é retornada toda a informação, não realizando mais o key Lookup.
Na prática
Bom, depois de alguns conceitos vamos realmente testar tudo isso. Para utilizar o Hekaton, o banco de dados precisa de um FileGroup MEMORY_OPTIMIZED_DATA:
-- Criando Banco de Dados com FileGroup MEMORY_OPTIMIZED_DATA CREATE DATABASE TesteInMemory ON PRIMARY (NAME = N'DBPrimary', FILENAME = N'C:\BaseDados\DBPrimary.mdf', SIZE = 819200KB, MAXSIZE = UNLIMITED, FILEGROWTH = 1024KB ), FILEGROUP DBDisco (NAME = N'DBDisco', FILENAME = N'C:\BaseDados\DBDisco.ndf', SIZE = 819200KB , MAXSIZE = UNLIMITED, FILEGROWTH = 1024KB ), FILEGROUP DBInMemory CONTAINS MEMORY_OPTIMIZED_DATA DEFAULT (NAME = N'DBInMemory', FILENAME = N'C:\BaseDados\DBInMemory', MAXSIZE = UNLIMITED) LOG ON (NAME = N'LogDB', FILENAME = N'C:\BaseDados\LogDB.ldf', SIZE = 512000KB, MAXSIZE = 2048GB, FILEGROWTH = 10%) GO
Agora vamos criar duas tabelas; a primeira será uma tabela padrão em disco.
-- Criando Tabela Padrão em Disco CREATE TABLE dbo.TBDisco ( ID INT PRIMARY KEY NOT NULL, Nome VARCHAR(50) NOT NULL, Valor INT NOT NULL, Data DATETIME NOT NULL ) GO
A segunda tabela será criada em memória. Observe que não existe grandes diferenças entre criar em disco e criar em “memória”. Alguns pontos que devem ser observados é, que no campo ID foi especificado o NONCLUSTERED HASH WITH(BUCKET_COUNT=1000000), onde um índice HASH está sendo criado com o BUCKET de tamanho 1000000.
Também foi informado a opção MEMORY_OPTIMIZED=ON, onde indica que esta tabela será otimizada em memória e o tipo de DURABILITY é SCHEMA_ONLY.
-- Criando Tabela em memória CREATE TABLE dbo.TBinMemory ( ID INT PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT = 1000000) NOT NULL, Nome VARCHAR(50) NOT NULL, Valor INT NOT NULL, Data DATETIME NOT NULL ) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_ONLY); GO
Com as tabelas criadas, iniciei uma carga de 10000000 (dez milhões) de registros via BCP. Com a finalidade de analisar e comparar o poder de escrita entre a tabela em disco e tabela em memória.
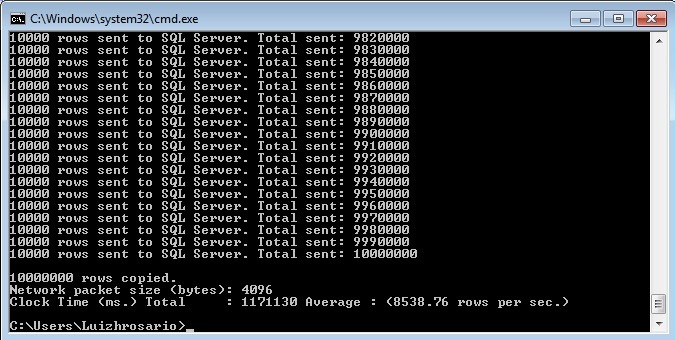
Vamos aos resultados! A imagem abaixo é referente à carga realizada na tabela em disco. Repare que os dez milhões de registros foram inseridos em 1171130 segundos com uma média de 8538.76 inserts por segundo.
Agora observe a imagem abaixo, referente à carga na tabela em memória.
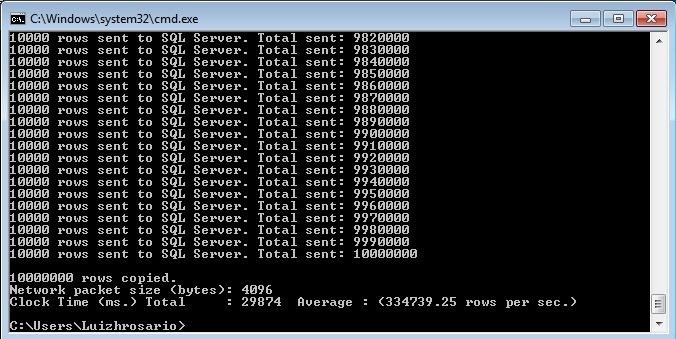
Os dois dez de registros foram inseridos em 29874 segundos com uma média de 334739.25 inserts por segundo, o que significa 39 vezes mais rápido que a anterior.
Conclusão
Como foi dito no início, o Hekaton é uma grande aposta da Microsoft para o SQL Server 2014, e com certeza irá quebrar alguns paradigmas. Esse teste que realizamos foi teoricamente simples, mas já conseguimos ver a força dessa nova engine.
Bom o que podemos concluir, é que o SQL Server 2014 está vindo muito forte e até o lançamento oficial do produto muita coisa irá surgir.
Até a próxima e bons estudos.
Graduado em Ciência da Computação pela Universidade Paulista, possui artigos publicados em grandes eventos na área de Banco de Dados com foco em Alta Disponibilidade e Distribuição Geográfica dos Dados. Apaixonado por Banco de Dados e Motocicletas, é profissional certificado Microsoft e atual como DBA SQL Server e Sybase.


