



Ensinando o Watson que resultados destacar
Recentemente, o IBM Watson Discovery Service introduziu uma nova capacidade chamada Relevancy Training. Ela permite que você ensine ao Watson quais resultados devem ser exibidos primeiro do que outros para que seus usuários possam obter a resposta correta para sua pergunta mais rapidamente. Você pode treinar suas coleções de pesquisa privadas usando uma abordagem somente para ferramentas ou usando as APIs Discovery. Neste artigo, eu explico como usar a ferramenta para treinar sua coleção de pesquisa privada.
O treinamento de relevância é um processo que permite que você faça uma consulta, veja os resultados da pesquisa retornados dessa consulta e diga ao Watson o que o pedido deve ser. Dessa forma, você está treinando o Watson usando exemplos de consultas que são representativos das consultas que seus usuários inserem e com classificações explícitas dos resultados da pesquisa.
Depois que o Watson tiver informações suficientes, ele começa a aprender sobre os padrões e a estrutura da coleção de pesquisa e as consultas que seus usuários inserem. O Watson usa técnicas de machine learning para encontrar sinais específicos em consultas que podem ser aplicados contra o corpus. Ele identifica quais semelhanças existem entre as aprendizagens e as novas consultas que são inseridas pelo usuário. Ele pode diferenciar entre documentos “bons” e “maus” usando esses sinais e padrões. O Watson então reordena os resultados da pesquisa com base no treinamento que recebeu.
É claro, o Watson é tão bom quanto o seu professor e, portanto, é importante garantir que qualquer treinamento que ele receba seja realizado por alguém que conheça os dados. As perguntas de treinamento também devem ser representativas do que seus usuários irão inserir. Recomendo que você selecione as consultas aleatoriamente de seus registros de consultas de usuários reais. Não escolha exemplos manualmente que parecem “boas” consultas para você. Ao fazê-lo, é provável que você introduza um viés em seus dados de treinamento para lidar com as consultas que você deseja que os usuários perguntem, e não as consultas que os usuários realmente fazem.
Então, como você aborda a obtenção dessas consultas?
Se você está substituindo um sistema de pesquisa existente, há uma boa chance de que você tenha logs de consultas que os usuários reais estão perguntando ao sistema. Forneça suas consultas a partir desses registros para criar o treinamento de relevância para sua solução baseada no Watson Discovery. Digite as consultas dos seus registros, veja os resultados do Watson e, em seguida, diga ao Watson quais resultados são bons e quais são ruins.
Se você está começando com uma nova implementação, aconselho você a implantar o sistema inicialmente sem Relevancy Training, mas certifique-se de que está fazendo consultas de registro. Em seguida, use as consultas que você registrou para treinar o Watson utilizando Relevancy Training.
Situação de exemplo
Como exemplo, você pode procurar por informações em publicações detalhadas como estas da Public Library of Science.
- http://dx.plos.org/10.1371/journal.pcbi.1002199
- http://dx.plos.org/10.1371/journal.pone.0059030
- http://dx.plos.org/10.1371/journal.pone.0077868
- http://dx.plos.org/10.1371/journal.pone.0152725
- http://dx.plos.org/10.1371/journal.pone.0156031
- http://dx.plos.org/10.1371/journal.pone.0144717
Para pesquisar esses documentos, vou fazer o upload deles para uma instância do Watson Discovery Service. Depois de fazer o upload dos documentos, procurarei contra eles. Então, vou iniciar o processo de Relevancy Training ao fazer o upload de consultas. Para cada consulta, eu analisarei os resultados que são retornados e classificá-los como Relevantes ou Não Relevantes. Depois de ter satisfeito os requisitos de aprendizagem para o Watson, deixarei-o aprender com as informações fornecidas. Finalmente, vou tentar algumas dessas pesquisas novamente com um novo Watson treinado.
Começando
Este artigo assume que você tem alguma familiaridade com o Bluemix e o Watson Discovery Service. Você precisará de uma conta Bluemix para começar. Se você não possui uma conta Bluemix, pode solicitar um free trial aqui. Se você já possui uma conta Bluemix e uma instância do Discovery, pode pular para a Etapa 5. Se você já possui uma Coleção, pode pular para a etapa 9.
- Faça login em sua conta Bluemix.
- Clique em Catalog.
- Clique em Discovery sob os serviços do Watson.
- Clique em Create para criar uma instância do Discovery.
- A partir dos detalhes da instância do Discovery, lance a ferramenta Discovery.

6. Clique em Create a data collection para criar uma nova coleção de dados dentro da sua instância. Se você criou um ambiente anteriormente, deve ver a seguinte janela para nomear a coleção. Caso contrário, você verá um prompt para criar um. Você também pode encontrar mais informações sobre ambientes no Discovery docs.
7. Nomeie a coleção. Você pode continuar usando a configuração padrão, que fornece todas as configurações necessárias para Relevancy Training.
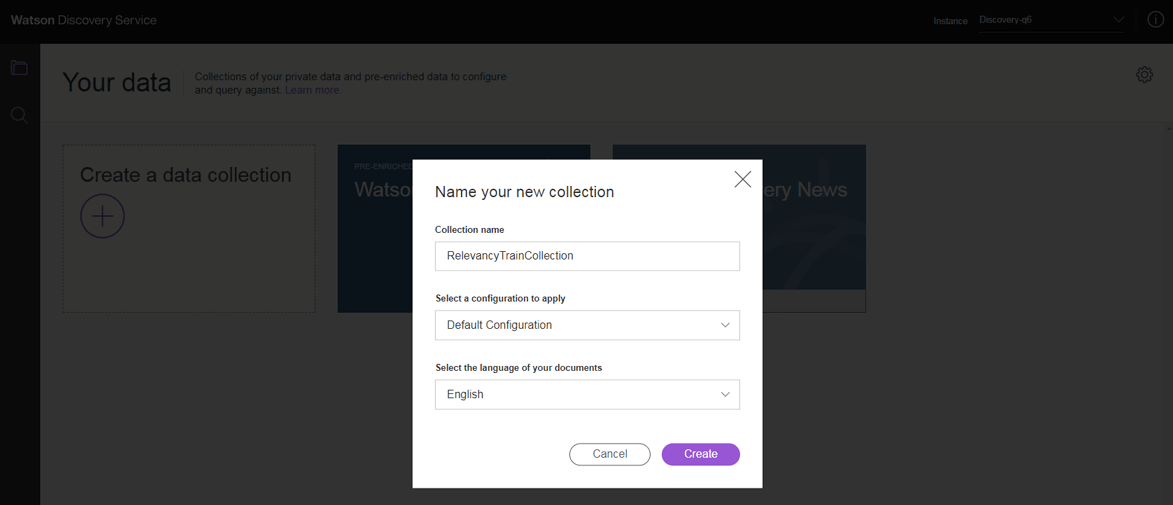
8. Após a criação da coleção, a página de detalhes das coleções é aberta. Nessa página, você pode fazer o upload dos documentos em que deseja realizar treinamento de relevância. O Discovery Service suporta documentos em formatos PDF, Microsoft Word, HTML ou JSON. Você pode facilmente arrastar documentos do seu sistema de arquivos local para o Discovery Service.

9. Depois de inserir alguns arquivos, você deve ver a contagem de documentos disponíveis atualizada. Agora você está pronto para consultar.
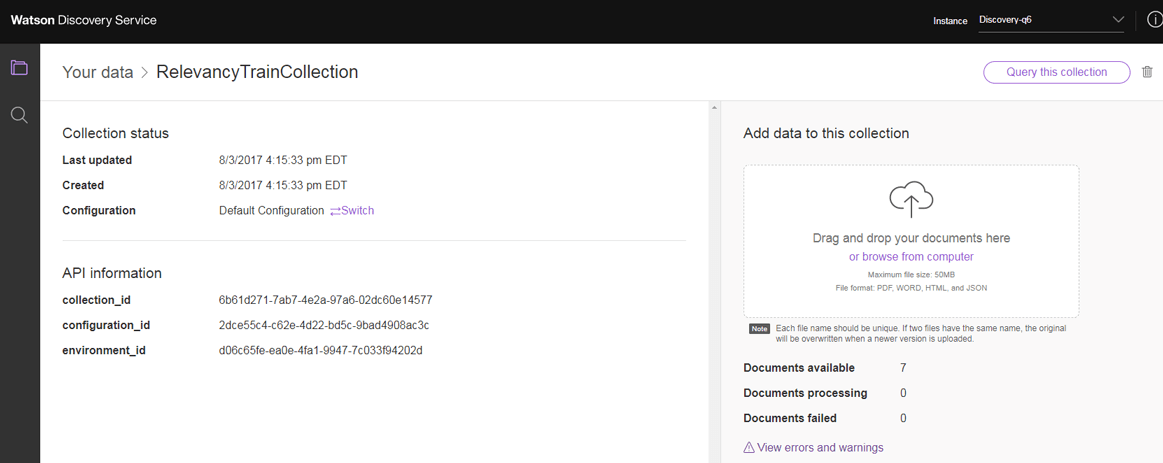
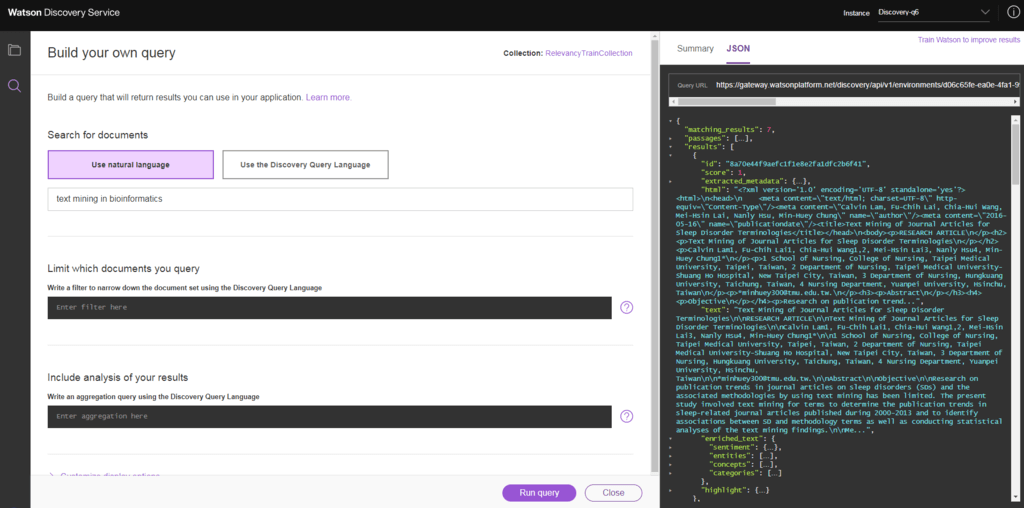
10. Selecione Query this collection. Isso abre a página de insights de dados, que fornece uma visão geral dos dados em sua coleção com base nos enriquecimentos de linguagem natural que são aplicados ao conteúdo. Para ver seus resultados de pesquisa, selecione Build your own query.
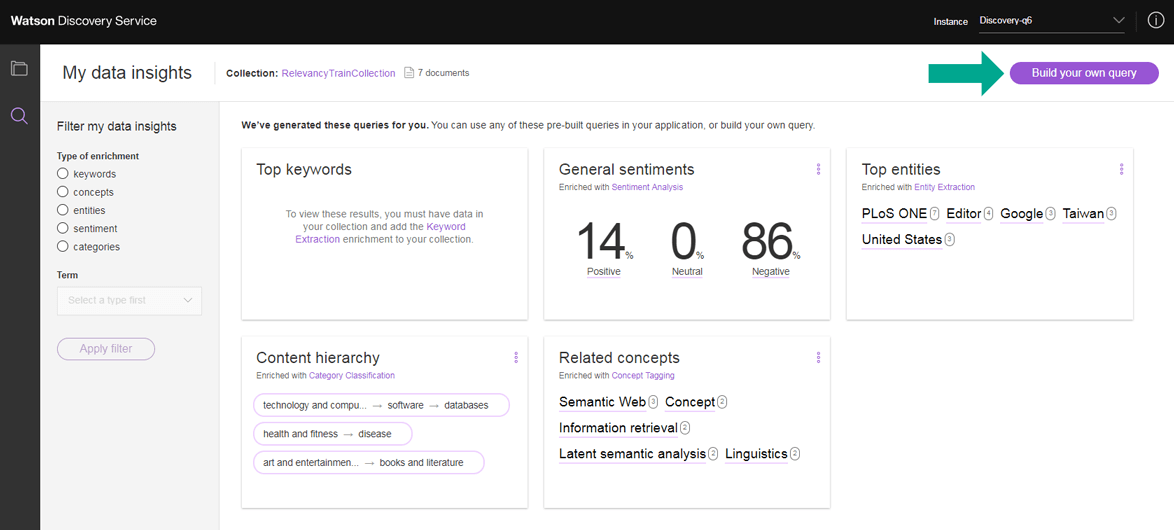
11. Na interface do construtor de consultas, selecione Use natural language por padrão nas entradas de consulta e filtro.
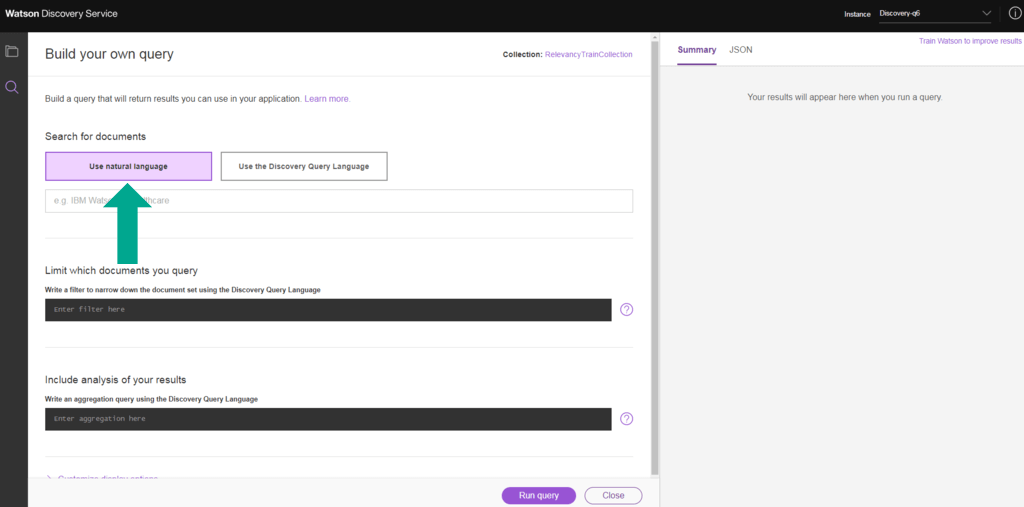
12. Selecione Run query para obter resultados que contenham passagens, bem como resultados de documentos. O resumo mostra as melhores passagens e os melhores resultados para a consulta. A resposta JSON tem uma parte top-level separada da resposta que contém as passagens que foram recuperadas, mais os resultados do documento.

13. Os resultados são ordenados com base na sua relevância para a consulta de pesquisa do usuário. Mude para a visualização JSON para ver os resultados do documento em sua forma bruta. Você pode colapsar a seção de passagens para obter uma visão melhor da seção de resultados (quais são os documentos retornados nos resultados da pesquisa).

14. Se os resultados não são ótimos para sua consulta ou outras consultas que você está testando, clique em Train Watson to improve results.
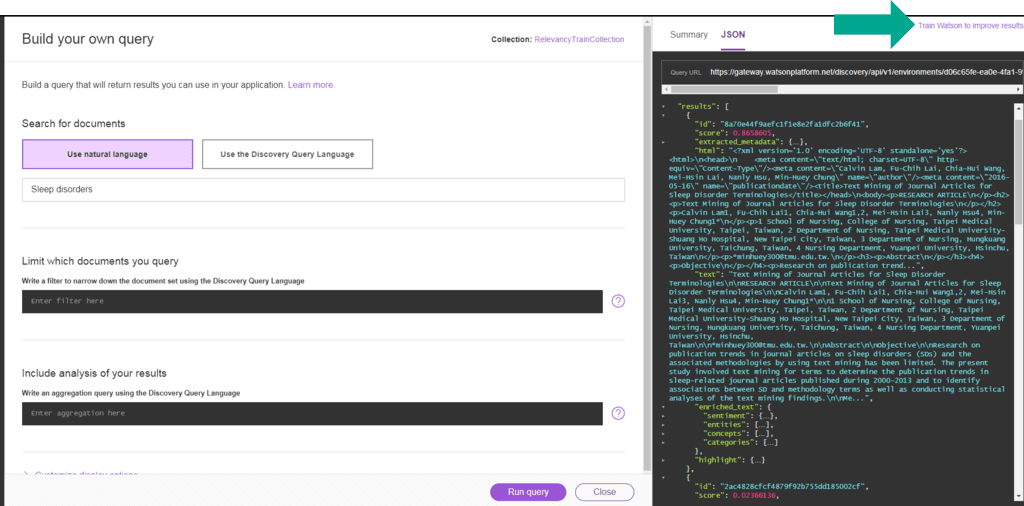
O Watson precisa que você diga quais documentos são os melhores resultados para suas consultas. Depois de treinar o Watson com consultas suficientes (uma boa representação das consultas do seu usuário) e respostas associadas, o Watson começa a reordenar seus resultados com base nesse aprendizado. A adição de consultas fornece consultas representativas para o Watson. Avaliar os resultados permite que o Watson compreenda o que traz bons resultados com base na consulta. Adicionar mais variedade aos seus resultados ajuda o Watson a diferenciar entre bons resultados e ótimos resultados.
15. Clique em Add a natural language query.
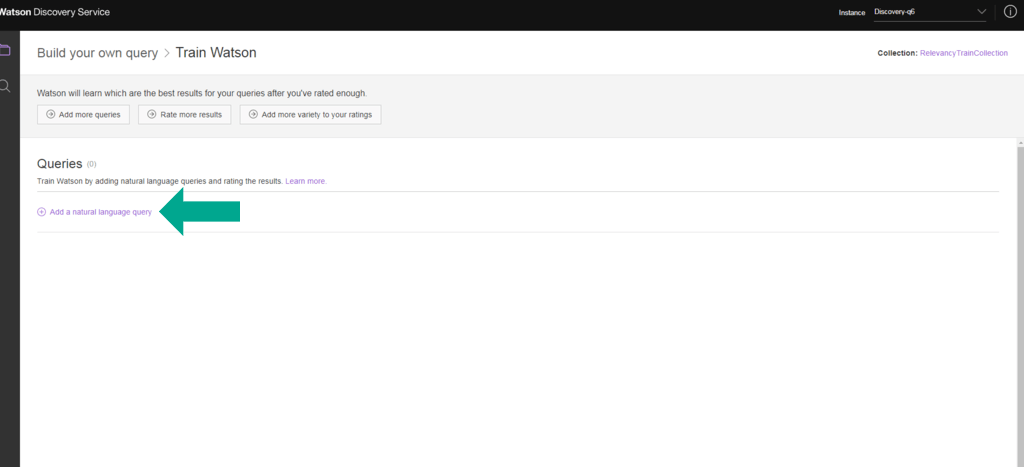
16. Digite uma consulta de linguagem natural na caixa e clique em Add. Tenha em mente que isso precisa ser representativo em relação ao que os usuários irão inserir.
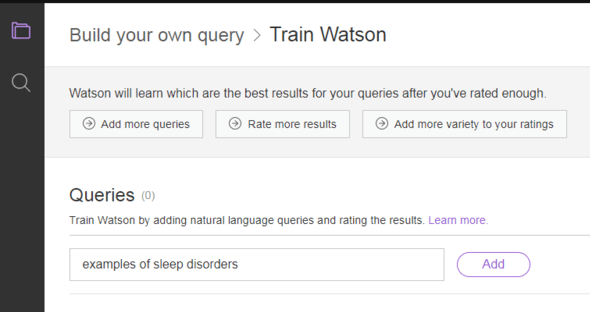
17. Clique em Rate more results para a consulta que você digitou. Agora você pode visualizar os resultados da pesquisa retornados para essa consulta. Você pode ver o título do documento e as passagens de texto, e você também pode ver o texto completo do documento clicando em View document.
Se você não vir o melhor documento na primeira página de resultados, clique na próxima página usando a navegação da página na parte inferior da tela.
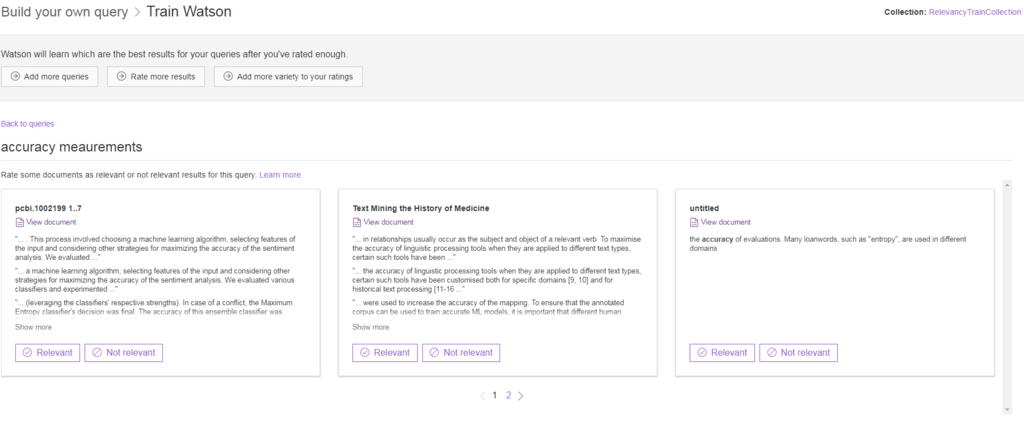
18. Clique em Relevant se um documento for relevante para sua consulta. Clique em Not relevant se o documento não for relevante para sua consulta. Depois de avaliar alguns documentos relevantes e alguns que não são, clique em Back to queries para retornar à lista de consultas.
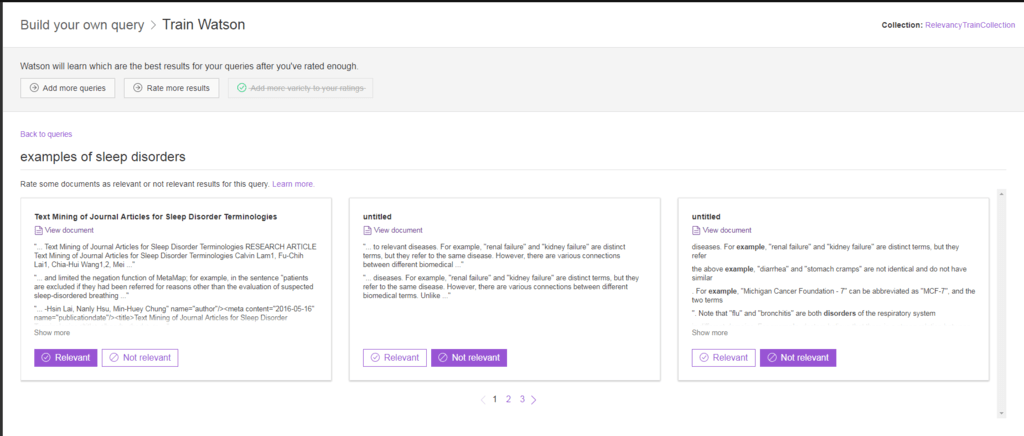
Você notará que alguns aspectos da tela mudaram depois de você avaliar os resultados. Primeiro, para cada consulta que você avaliou, verá que o Watson atualizou a quantidade de documentos que você classificou como relevantes e aqueles que foram marcados como não relevantes.
19. Repita o processo para adicionar e avaliar mais consultas. Se você precisar excluir uma consulta, clique na lixeira no lado direito da consulta.
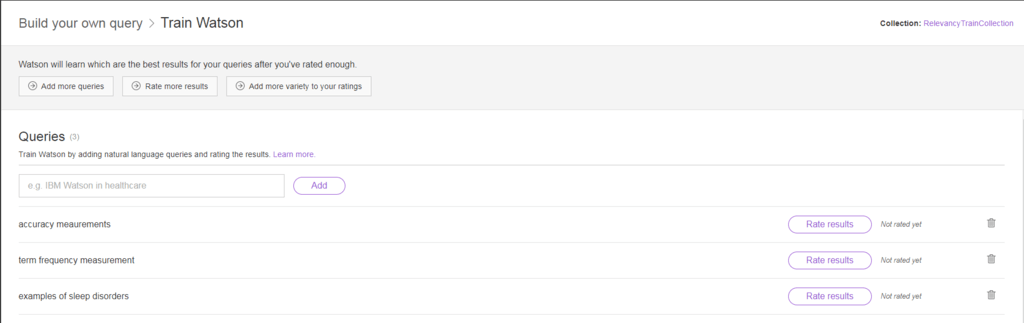
À medida que você classifica mais consultas, também notará que os requisitos de treinamento no topo também mudam. Com cada requisito cumprido, o Watson cruza isso para que você saiba que tem informações suficientes. Você precisará de aproximadamente 50 consultas exclusivas para satisfazer o requisito de treinamento.
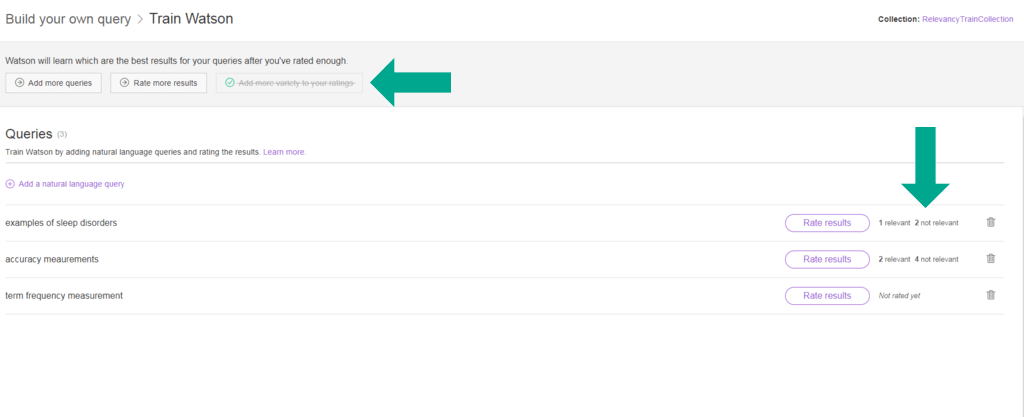
Quando o Watson tiver atendido todos os requisitos, ele inicia os preparativos para começar a aprender.
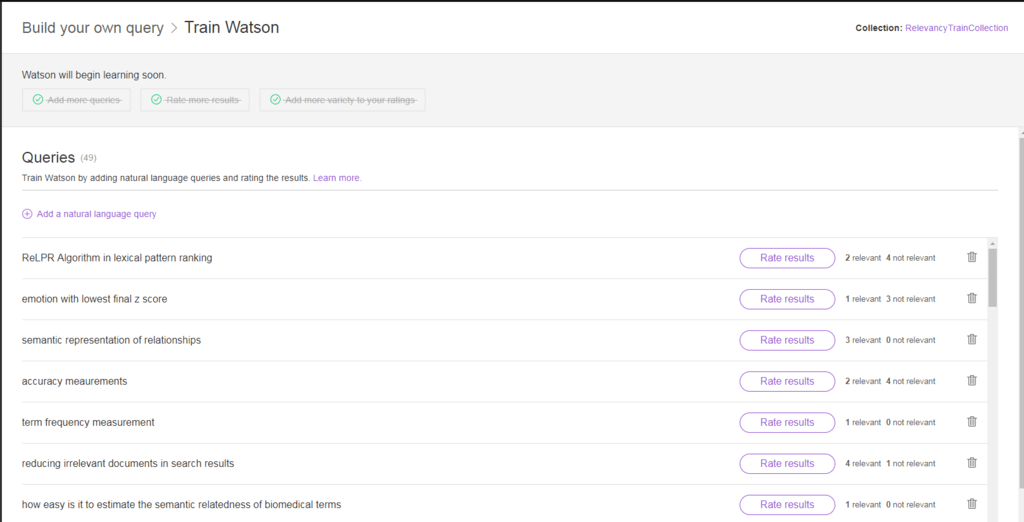
Depois que o Watson estiver pronto, ele inicia o processo de aprendizagem. Esse processo pode demorar algum tempo (geralmente, não mais de 30 minutos, dependendo da quantidade de dados presentes).
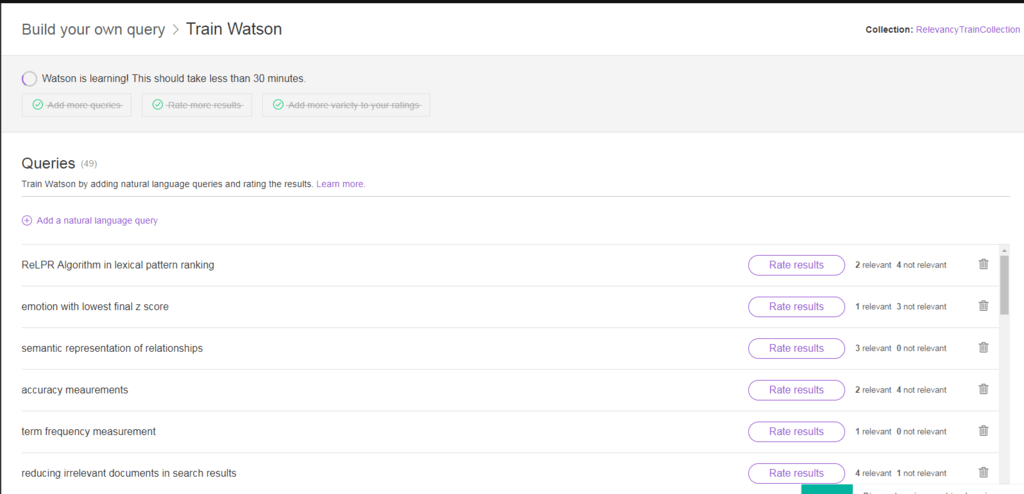
Pronto! O Watson aprendeu usando as informações de treinamento que você forneceu. Você deve continuar adicionando consultas representativas e classificações ao longo do tempo para ajudar o Watson a aprender. Além disso, você deve reciclar o Watson sempre que adicionar ou excluir documentos que possam alterar as classificações das consultas que você já classificou. Você também deve revisar o treinamento sempre que os tipos de documentos ou consultas mudarem drasticamente.
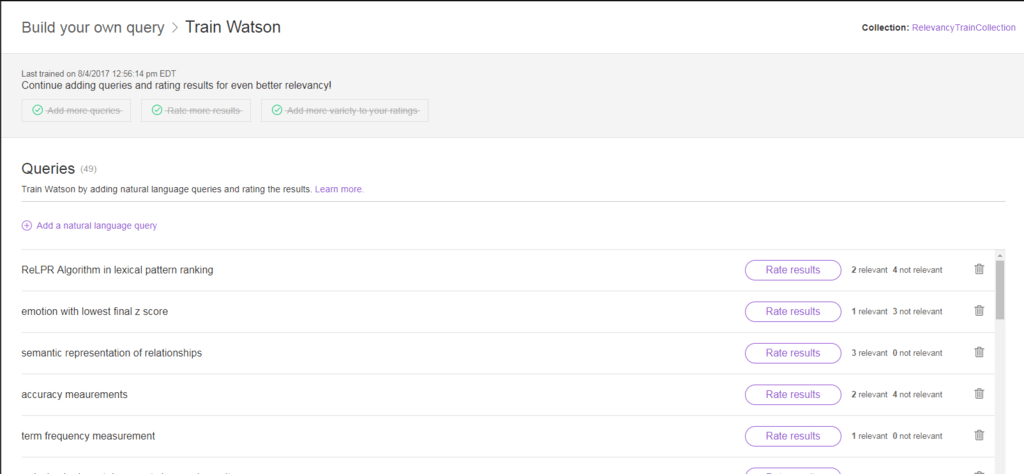
Agora, você deve tentar novamente algumas das consultas que você inseriu anteriormente para ver os ajustes que o Watson faz.
20. Clique na lupa no lado esquerdo da tela e selecione a coleção que você acabou de treinar.
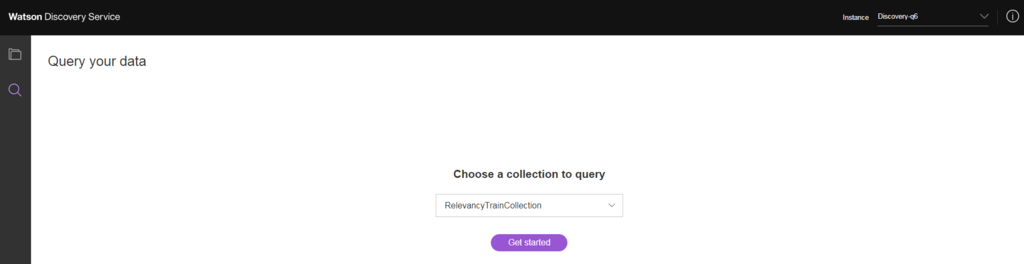
21. Selecione Build your own query para ir para página de consultas.
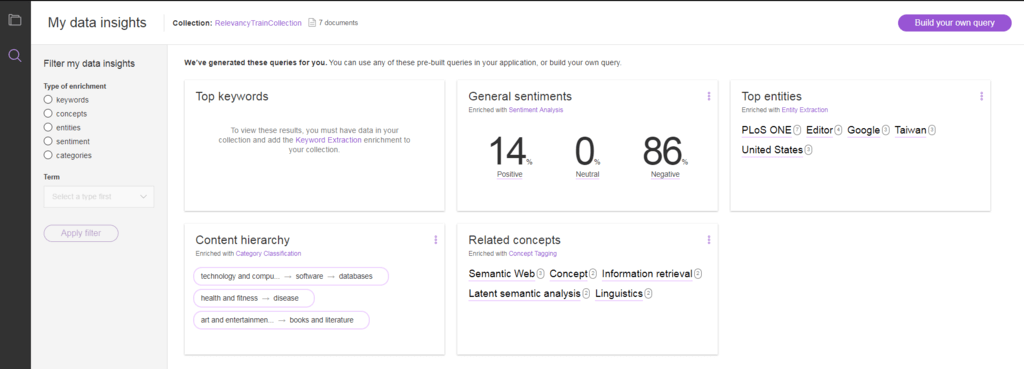
22. Digite uma consulta de linguagem natural e veja os resultados. Eles devem ser melhorados com base no feedback que você usou para ensinar o Watson.
Conclusão
Este artigo demonstrou como você pode usar Relevancy Training no Watson Discovery Service para ensinar o Watson a fazer melhores julgamentos ao solicitar resultados de pesquisa. Isso, por sua vez, dá aos seus usuários as respostas às suas perguntas mais rapidamente. Agora que você sabe como usar o Relevancy Training, pode começar a aplicar essa técnica a outras aplicações comerciais.
Use o Relevancy Training em qualquer aplicativo que esteja fornecendo documentos como resultados de pesquisa. Você pode usar essa capacidade em casos de suporte para o produto para ajudar os agentes a encontrarem respostas rápidas para as perguntas dos clientes, pesquisar cenários para escanear as publicações mais recentes, aplicações de treinamento para ajudar os pesquisadores a se atualizarem, aplicações corporativas para abordar as respostas mais relevantes às perguntas frequentes e muitos outros potenciais casos de uso.
Consulte a documentação para obter detalhes sobre como experimentar o Relevancy Training no IBM Watson Discovery Service.
Para obter mais informações, você pode assistir a um webinar sobre Relevancy Training ou ver quais outros webinars são oferecidos na série de webinars Building with Watson.
Recursos que podem ser baixados
Tópicos relacionados
***
Will Chaparro faz parte do time de colunistas internacionais do iMasters. A tradução do artigo é feita pela Redação iMasters, com autorização do autor, e você pode acompanhar o artigo em inglês no link: https://www.ibm.com/developerworks/library/cc-cognitive-watson-relevancy-training/
Matérias especiais e reportagens conduzidas internamente pela Redação iMasters. Acompanhe no Twitter @imasters e no Instagram/Threads @portalimasters


