
A computação na nuvem abriu novos caminhos para utilização de infraestrutura computacional de forma mais eficiente. Em vez de ter que comprar toneladas de servidores para que se aguente pequenos picos de acesso em um e-commerce, por exemplo, podemos provisionar novas máquinas em minutos – ou até mesmo segundos -, de acordo com a necessidade.
Sabemos que não é tão simples assim, pois a maioria das aplicações web existentes são aplicações antigas que não foram feitas para a nuvem; muitas vezes são grandes monolitos que só escalam na vertical. Até mesmo em aplicações que estão nascendo neste momento, muitas vezes por decisões de negócio e de aceleração de entrega, a arquitetura de software deixa a desejar e já nasce não preparada para a nuvem.
Neste artigo mostrarei uma forma simples de como usar o openstack para escalar uma aplicação web. Utilizaremos, além da camada básica de computação (nova) e network (nêutron), duas outras stacks: o Ceilometer (telemetria) e o Heat (orquestração).
Conhecendo o Heat
O Heat é o principal projeto de orquestração do OpenStack, ele possibilita fazer o deploy de aplicações complexas na nuvem utilizando templates no formato YAML. O Heat consegue automatizar a criação de instancias, network, storage, praticamente tudo que o openstack oferece.
No Heat temos alguns componentes:
- heat-engine: faz o papel principal de orquestração através dos templates.
- heat-api-cfn: fornece REST APIs compatíveis com o CloudFormation da AWS.
- heat-api: Fornece REST APIs nativas do openstack para interação com o heat-engine.
- heat: a interface de linha de comando do que comunica com o heat-api.
Estrutura de um template do heat:
heat_template_version: 2015-04-30
description: Simple template to deploy a single compute instance
parameters:
key_name:
type: string
label: Key Name
description: Name of key-pair to be used for compute instance
image_id:
type: string
label: Image ID
description: Image to be used for compute instance
instance_type:
type: string
label: Instance Type
description: Type of instance (flavor) to be used
resources:
my_instance:
type: OS::Nova::Server
properties:
key_name: { get_param: key_name }
image: { get_param: image_id }
flavor: { get_param: instance_type }
output:
server_adress:
str_replace:
template: http://host/
params:
host: { get_attr: [floating_ip_address] }
Temos, basicamente, três seções: os parâmetros de entrada antes da execução do arquivo, os recursos de infraestrutura que serão orquestrados ou recursos que ajudarão no processo de orquestração, como por exemplo, monitoramento de uso de cpu, e ainda uma saída para dar algum feedback ao usuário ou sistema.
Mão na massa
Neste exemplo, criaremos uma infraestrutura escalável horizontalmente conforme mostrado na figura abaixo:
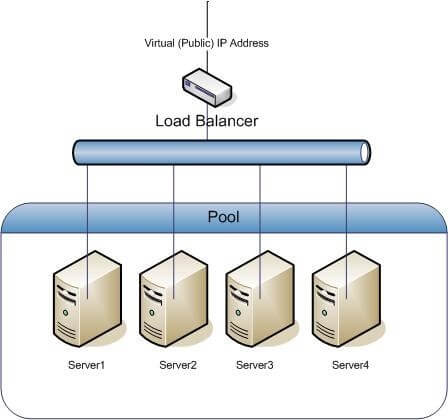
Teremos um Load Balancer recebendo requisições HTTP e distribuindo as requisições via Round Robin para um pool escalável de máquinas virtuais. Para esse exemplo, seremos simplistas e nosso trigger para autoscaling será utilização de CPU, conseguimos mensurá-lo de forma facilitada através do ceilometer, que nos dá diversas informações dos recursos que estão sendo utilizados no openstack. Com ele, criaremos alarmes que serão ativados quando a utilização de CPU chegar em determinado percentual.
Primeiro definimos a versão do template para que o Heat saiba interpretar. Os parâmetros deste exemplo são a imagem com a aplicação a ser escalada, o par de chaves de acesso a instância, o flavor da instância, network, subnet e a rede externa para deixarmos o loadbalancer disponível para a internet. Todos estes itens já estão pré-configurados no openstack.
heat_template_version: 2016-10-14
description: Sample autoscaling with LBAAS
parameters:
image:
type: string
description: Image used for web servers
default: CentOS-7 64Bits
key:
type: string
description: SSH key to connect to the servers
default: Ubuntu Victor
web-flavor:
type: string
description: flavor used by the web servers
default: small.2GB
subnet_id:
type: string
description: subnet on which the load balancer will be located
default: 2a4ddc88-57d3-4b6c-816e-86d2b623eeee
O segundo passo é definir os recursos.
Primeiramente, definimos o autoscaling group. Nesta seção, setamos a quantidade mínima e máxima de instâncias, bem como a configuração da instância propriamente dita; neste caso, deixamos a configuração da máquina em outro arquivo (scaledmachine.yaml). Além disso, apenas para exemplificar o scalling, iniciamos a máquina com um user_data que cria quatro loops infinitos para forçar o uso de cpu e verificarmos o scalling up em funcionamento.
Todo autoscaling deve ser regido por uma política; criamos duas, a de scale up (web_server_scaleup_policy) e scale down (web_server_scaledown_policy). Cada política tem um alarme como trigger; configuramos dois deles (cpu_alarm_high e cpu_alarm_low). Como podem ver, o alarme que escala para cima, ou seja, incrementa uma instância no pool, é ativado caso o uso de CPU seja maior que 60% no intervalo de tempo de um minuto. Caso o uso de CPU seja menor que 30% por 6 minutos, o alarme cpu_alarm_low é ativado, desescalando uma máquina.
O Recurso lb especifica a criação do load balancer na porta 80, o pool tem a informação dos recursos que estão atrelados ao loadbalancer, o monitor por sua vez é um Health Check do Load Balancer.
resources:
autoscaling-gp:
type: OS::Heat::AutoScalingGroup
properties:
min_size: 1
max_size: 6
resource:
type: scaledmachine.yaml
properties:
flavor: {get_param: flavor}
image: {get_param: image}
key_name: {get_param: key}
network: {get_param: network}
pool_id: {get_resource: pool}
metadata: {"metering.stack": {get_param: "OS::stack_id"}}
user_data: |
#!/bin/bash -v
for i in 1 2 3 4; do while : ; do : ; done & done
web_server_scaleup_policy:
type: OS::Heat::ScalingPolicy
properties:
adjustment_type: change_in_capacity
auto_scaling_group_id: {get_resource: autoscaling-gp}
cooldown: 60
scaling_adjustment: 1
web_server_scaledown_policy:
type: OS::Heat::ScalingPolicy
properties:
adjustment_type: change_in_capacity
auto_scaling_group_id: {get_resource: autoscaling-gp}
cooldown: 360
scaling_adjustment: -1
cpu_alarm_high:
type: OS::Ceilometer::Alarm
properties:
description: Scale-up if the average CPU > 60% for 1 minute
meter_name: cpu_util
statistic: avg
period: 60
evaluation_periods: 1
threshold: 60
alarm_actions:
- {get_attr: [web_server_scaleup_policy, alarm_url]}
matching_metadata: {'metadata.user_metadata.stack': {get_param: "OS::stack_id"}}
comparison_operator: gt
cpu_alarm_low:
type: OS::Ceilometer::Alarm
properties:
description: Scale-down if the average CPU < 15% for 360 seconds
meter_name: cpu_util
statistic: avg
period: 360
evaluation_periods: 1
threshold: 15
alarm_actions:
- {get_attr: [web_server_scaledown_policy, alarm_url]}
matching_metadata: {'metadata.user_metadata.stack': {get_param: "OS::stack_id"}}
comparison_operator: lt
monitor:
type: OS::Neutron::HealthMonitor
properties:
type: TCP
delay: 5
max_retries: 5
timeout: 5
pool:
type: OS::Neutron::Pool
properties:
protocol: HTTP
monitors: [{get_resource: monitor}]
subnet_id: {get_param: subnet_id}
lb_method: ROUND_ROBIN
vip:
protocol_port: 80
lb:
type: OS::Neutron::LoadBalancer
properties:
protocol_port: 80
pool_id: {get_resource: pool}
# assign a floating ip address to the load balancer
lb_floating:
type: OS::Neutron::FloatingIP
properties:
floating_network_id: {get_param: external_network_id}
port_id: {get_attr: [pool, vip, port_id]}
Template de descrição da máquina virtual a ser escalada (scaledmachine.yaml):
heat_template_version: 2016-10-14
description: A load-balancer server
parameters:
image:
type: string
description: Image used for servers
key_name:
type: string
description: SSH key to connect to the servers
flavor:
type: string
description: flavor used by the servers
pool_id:
type: string
description: Pool to contact
user_data:
type: string
description: Server user_data
metadata:
type: json
network:
type: string
description: Network used by the server
resources:
server:
type: OS::Nova::Server
properties:
flavor: {get_param: flavor}
image: {get_param: image}
key_name: {get_param: key_name}
metadata: {get_param: metadata}
user_data: {get_param: user_data}
user_data_format: RAW
networks: [{network: {get_param: network} }]
member:
type: OS::Neutron::PoolMember
properties:
pool_id: {get_param: pool_id}
address: {get_attr: [server, first_address]}
protocol_port: 80
outputs:
server_ip:
description: IP Address of the load-balanced server.
value: { get_attr: [server, first_address] }
lb_member:
description: LB member details.
value: { get_attr: [member, show] }
Nesse exemplo, como já iniciamos a instância com grande uso de CPU, a cada minuto uma máquina deveria ser escalada. Contudo isso vai depender das configurações do OpenStack. Por padrão, o período de pooling do ceilometer é de 10 minutos, logo, em um caso como este, a cada 10 minutos uma máquina iria escalar.

De 0 a 10, o quanto você recomendaria este artigo para um amigo?