

Olá, pessoal. Neste artigo vou abordar como trabalhar com o MySQL no Raspberry Pi, o pequeno computador que além de baixo custo, possui muitas características interessantes e pode viabilizar diversos projetos.
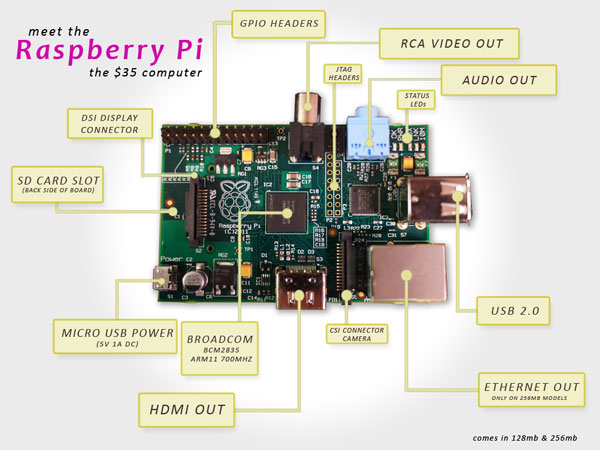
O Raspberry Pi – ou apenas RPi, como é conhecido pela comunidade hacker – é um computador completo com diversas funcionalidades. Inicialmente concebido para fins educacionais, esta plataforma é baseada em um processador ARM que roda Linux e possui diversas características técnicas, como pode ser visto na figura acima. Os seus principais atrativos incluem a possibilidade da criação de projetos de computação embarcada (embedded computing) e, obviamente, o preço de US$35 considerando seus recursos.
Quando eu soube do lançamento deste novo computador, logo me interessei por ser uma alternativa ao Arduíno, no meu ponto de vista. O fato de rodar uma distribuição Linux definitivamente foi um diferencial para que eu adquirisse este produto visando a realização de alguns projetos pessoais. Abaixo mostro o meu RPi (junto com uma caneca do iMasters) que é modelo B de 256 MB. Para quem se interessar, já existe uma distribuidora oficial no Brasil. Mas se apresse, pois os lotes que são importados são vendidos rapidamente.

Para quem acabou de adquirir este pequeno computador, recomendo procurar informações básicas que mostram como instalar o sistema operacional no cartão de memória e fazer o boot inicial. Também recomenda-se a instalação de serviços adicionais, como um VNC para o acesso remoto ao desktop. Dependendo da funcionalidade que se desejardar a este computador, é possível que haja uma distribuição Linux pronta e customizada como, por exemplo, uma versão especial do Linux que já roda automaticamente o player de vídeo XBMC para transformar o RPi em um media center.

Um dos principais objetivos que eu tinha ao adquirir este pequeno computador era testar o seu desempenho de um banco de dados. Inicialmente, escolhi o MySQL rodando a distribuição Raspbian “wheezy”, que é uma versão otimizada do Debian. Atualmente, já existem outras distribuições prontas para o RPi, inclusive com a pilha de aplicações LAMP. A instalação do MySQL foi muito simples, pois a distribuição escolhida contém o gerenciador de pacotes apt-get. Desta maneira, bastou fazer um login remoto via SSH (já instalado por padrão no Raspbian “wheezy”) e utilizar o comando sudo apt-get install mysql-server, como a figura abaixo mostra.
Uma vez instalado, pude acessar o MySQL 5.5 normalmente e realizar as operações como em um servidor. O próximo passo foi testar o desempenho do MySQL nesta plataforma em comparação a um servidor Intel.
Antes de detalhar a comparação vale a pena gastar ao menos um parágrafo para justificar tal tarefa. O RPi certamente não vai ser utilizado como servidor oficial de banco de dados (talvez como um servidor de testes?), porém ele é uma ótima plataforma para aprendizado. Só isso já justifica o teste, porém destaco também que é um desafio importante saber quais são as limitações da plataforma e compartilhar o aprendizado durante este processo. Sem contar que atualmente são poucos os testes de bancos de dados que podem ser encontrados para auxiliar o profissional a ter uma base comparativa técnica de desempenho para auxiliar o seu processo decisório envolvendo tecnologia de banco de dados. E, acima de tudo, é divertido!
O ambiente de testes escolhido para comparar os tempos de execução de instruções SQL no RPi e em um servidor contou com um computador desktop equipado com o processador Intel Core i7 modelo 950 que contém quatro núcleos (oito núcleos vistos pelo sistema operacional, devido à tecnologia Hyper Threading da Intel) com clock de 3.06 GHZ cada (sem overclock), 12 GB de memória RAM DDR3, 64 KB de memória cache L1, 256 KB de cache L2 e 8 MB de cache L3. Esse computador contou ainda com 1 TB de HD SATA 2 e o sistema operacional Windows Server 2008 R2. Utilizando o virtualizador VMWare Workstation 8.0 uma máquinas virtuais idênticas foram criadas com 4 processadores virtuais, 4 GB de memória RAM e 50 GB de espaço em disco. Esta configuração foi adequada para suportar os testes no sistema operacional Red Hat Enterprise Linux 6 edição 64 bits. Esta distribuição do Linux foi escolhida por ser recomendada pela documentação do do MySQL 5.5.25 cuja edição instalada para a plataforma foi a de 64 bits. Utilizou-se o sistema de arquivos ext4 no Red Hat Linux 6, que teve 1 GB de memória alocado para a partição de swap. Cabe ressaltar ainda que durante os testes cada banco de dados foi executado de forma dedicada, ou seja, apenas este serviço estava sendo executado no servidor.
Já o RPi é uma plataforma com o processador 32 bits ARM1176JZF-S com um único núcleo rodando com o clock de 700 MHz com 16KB de memória L1 e 128KB de memória cache L2. O computador contém 256 MB de memória RAM e foi utilizado um cartão de memória de SD de 32GB classe 10. O Linux foi instalado com as configurações padrões do Raspbian “wheezy” e utilizou o sistema de arquivos ext4.
Para realizar os testes de desempenho de instruções INSERT, SELECT, UPDATE e DELETE foi preciso utilizar uma massa de dados de testes que permita uma comparação que represente o tipo de operação realizada no dia a dia das empresas. Neste artigo, optei por escolher apenas dados numéricos com precisão decimal, uma vez que eles fornecem uma boa aproximação das principais tarefas realizadas nos bancos de dados. Isso quer dizer que eles ocupam a mesma quantidade de bytes na memória, podem ser manipulados de forma semelhante e fazem parte da maioria dos modelos de dados encontrada em diversos tipos de sistemas que acessam dados.
Em situações reais é provável que os valores comparativos possam ser diferentes dependendo de diversos fatores como hardware, carga do servidor, configurações específicas e tipos de dados. De qualquer maneira, os testes realizados podem servir como ponto de partida para a avaliação do MySQL no RPi.
A massa de testes foi criada a partir de uma tabela simples com uma coluna do tipo INT numerada sequencialmente e com uma chave primária nesta coluna, que criou um índice clustered na tabela. Também foram criadas outras dez colunas do tipo FLOAT preenchidas com valores aleatórios entre 1,0 e 100.000,00. Cada operação foi realizada dez vezes e os tempos de execução apresentados nas próximas seções correspondem à média entre estas dez execuções. Para simplificar, os demais detalhes dos testes (desvio padrão, distribuição dos dados, margem de erro e outros) foram omitidos. A medição de tempo no MySQL foi realizada através do tempo de execução retornado pela ferramenta de console mysql.
Para a tarefa de importação de dados, foi necessário utilizar uma ferramenta externa ao banco de dados. Nestes casos, o tempo de execução foi coletado diretamente no console do sistema operacional. A obtenção dos tempos de execução gastos pelas ferramentas foi realizada por meio do arquivo binário time fornecido pelo próprio Sistema Operacional. Apesar de alguns dados comparativos serem apresentados em unidades de tempo diferentes, todos os valores foram convertidos para a unidade de tempo segundo.
Em todos os testes realizados, a quantidade de linhas começou com 100.000 e foi crescendo em incrementos de 100.000 linhas (N=100.000, N=200.000, N=300.000, etc.) até o valor máximo de N=1.000.000 linhas. As instruções enviadas manipularam todas as linhas da tabela em cada conjunto de testes. No MySQL os dados de teste foram armazenados em tabelas criadas com o engine InnoDB (que permite o uso de transações implícitas). Para evitar algum tipo de interferência na medição do tempo de execução devido à lentidão na alocação de espaço em disco durante os testes, o banco de dados no MySQL foi criado com espaço de alocação em disco 50% acima da quantidade máxima necessária para o maior dos testes (N=1.000.000). Além disso, a quantidade de espaço em disco e o volume de memória gasto pelo banco de dados para armazenar os dados durante todos os testes não foram levados em consideração, uma vez que o principal objetivo da comparação foi avaliar apenas o tempo de execução das operações realizadas por instruções SQL.
Nos bancos de dados SQL há um fator que potencialmente poderia influenciar o tempo de execução das instruções: a geração de locks e outros recursos para o controle de concorrência. Nos testes iniciais verificou-se que a diferença entre os mecanismos empregados para o controle de concorrência não afetaram de maneira significativa o tempo de execução e, sendo assim, os testes foram executados sem nenhum controle de concorrência específico. O fator cache de banco de dados não foi levado em consideração, pois cada instrução em cada quantidade de dados foi realizada 10 vezes e o valor obtido para a comparação foi a média do tempo de execução. Portanto, o cache interno (de instruções e de dados) foi considerado um fator pertencente a cada produto e não algo que deveria ser desconsiderado na avaliação.
Os gráficos apresentados na próxima seção têm como objetivo evidenciar a diferença entre os tempos de execução de instruções SQL no servidor Intel e no RPi. O leitor não deve se concentrar nas pequenas variações dos gráficos e sim focar nas diferenças entre os tempos de execução para cada quantidade diferente de linhas. Também vale a pena destacar que nem sempre é possível prever o tempo de execução, pois existem diversos fatores externos que podem influenciar no tempo de execução, por mais cuidadoso que seja o ambiente de testes.
- Testes de INSERT
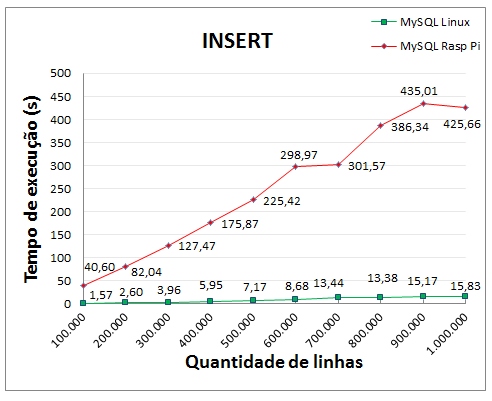
Partindo do princípio que no nível mais básico o banco de dados somente aceita a inserção de dados por meio da instrução INSERT, a importação de dados foi realizada a partir de arquivos texto puro com os dados organizados em arquivos CSV (Comma Separated Values), ou seja, os dados foram separados por linhas e as colunas separadas por vírgulas. No MySQL o comando utilizado para a importação de dados foi o LOAD DATA LOCAL INFILE …INTO TABLE … dentro do utilitário de consultas mysql. Os gráficos da abaixo mostram a comparação dos tempos de execução entre as instruções do MySQL no computador desktop e no RPi.
- Testes de DELETE
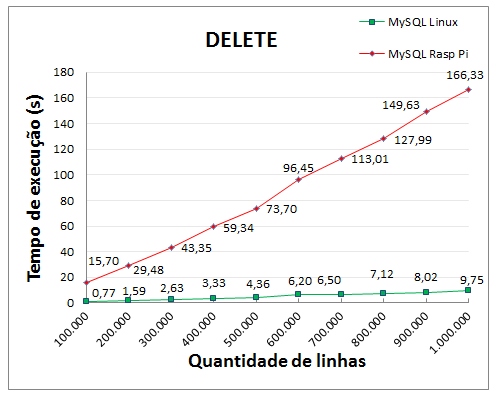
Os testes de remoção de dados consideraram a exclusão de todos os dados da tabela através do comando DELETE <nome_tabela>. Apesar de ser possível utilizar a instrução DROP TABLE ou TRUNCATE TABLE para excluir todos os dados da tabela de forma instantânea (evitando o log de transações), os testes realizados com a instrução DELETE servem para uma base de comparação da execução em instruções que contenham filtros. O gráfico da figura abaixo mostra a comparação para a remoção de linhas.
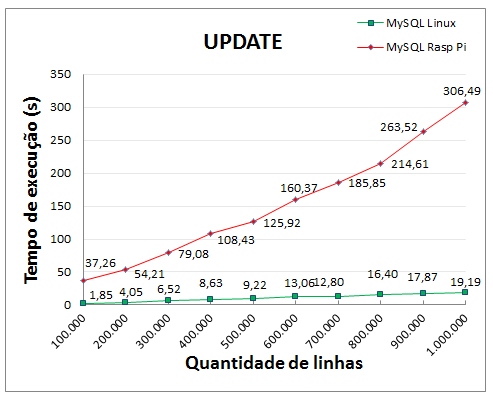
- Testes de UPDATE
Os testes realizados com as instruções UPDATE foram projetados de modo que cada uma das colunas de cada linha da tabela fosse modificada da seguinte maneira: incrementar o valor da coluna em uma unidade. Desta maneira cada coluna de cada linha foi modificada. A instrução UPDATE utilizada no MySQL foi:
UPDATE <nome_tabela> SET C1 = C1 + 1,C2 = C2 + 1,C3 = C3 + 1,C4 = C4 + 1,C5 = C5 + 1,C6 = C6 + 1 ,C7 = C7 + 1,C8 = C8 + 1 ,C9 = C9 + 1,C10 = C10 + 1;
A figura abaixo mostra a comparação do tempo de execução para a alteração de dados.
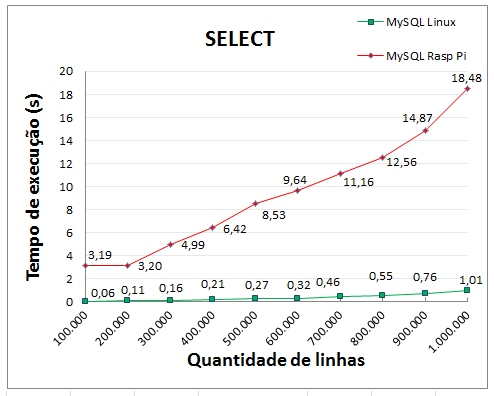
- Testes de SELECT
O teste de consulta de dados fez a soma dos valores de cada uma das dez colunas do tipo FLOAT através da função de agregação SUM(), porém sem nenhuma cláusula GROUP BY. O comando utilizado no MySQL foi:
select sum(c1), sum(c2),sum(c3),sum(c4),sum(c5),sum(c6),sum(c7),sum(c8),sum(c9),sum(c10) from <nome_tabela>;
Em todos os casos as somas retornaram os mesmos valores agregados para a soma de cada uma das colunas armazenadas na tabela, comprovando que a comparação foi realizada através de comandos que produziram o mesmo resultado. Como a execução das consultas apenas lê dados e não gera modificações, notou-se que ela apresentou os melhores tempos dentre todas as comparações, vide a escala do eixo das coordenadas apresentada nos gráficos da figura abaixo.
Conclusão
Apesar da metodologia básica de comparação, obtive dados para comprovar o que já era claro: o desempenho do RPi é muito inferior ao desempenho de um servidor desktop de acordo com o contexto do teste de banco de dados realizado. Contudo, devemos encarar esta comparação com cautela, pois existem diversos outros fatores que ficara de fora. Por exemplo, temos o curso de um servidor desktop x custo do RPi, a quantidade de energia consumida (algo em torno de 900W x 5W) e o propósito de uso de cada uma destas plataformas. Mas, como disse em um parágrafo anterior, este pequeno estudo comparativo serve para indicar que a plataforma é muito robusta e aceita trabalhar com uma carga de dados considerável.

De 0 a 10, o quanto você recomendaria este artigo para um amigo?