

Fala, pessoal!
Neste artigo eu vou mostrar pra vocês quando devemos utilizar ORDER BY e quando não devemos utilizar de jeito nenhum, porque não produz efeito nenhum na prática e apenas deixa nossa consulta mais demorada e consumindo mais recursos.
O intuito deste artigo é quebrar o mito de que os dados são ordenados fisicamente na tabela quando você faz o INSERT… FROM SELECT e ORDER BY, fazendo com que muitos programadores insistam em utilizar ORDER BY em operações de INSERT, um cenário que eu encontro bastante nos clientes de consultoria e é bem mais comum do que eu gostaria.
Para começar, vou fazer um teste muito simples com isso, criando uma nova tabela e inserindo os dados na tabela a partir de uma consulta na sys.objects:
CREATE TABLE dbo.Post_OrderBy (
Id INT IDENTITY(1,1) NOT NULL,
Nome VARCHAR(900) NOT NULL
)
INSERT INTO dbo.Post_OrderBy
SELECT [name]
FROM sys.objects
ORDER BY name
SELECT * FROM dbo.Post_OrderByE quando analisamos os resultados, vemos que mesmo utilizando ORDER BY no INSERT, os registros não estão sendo ordenados:
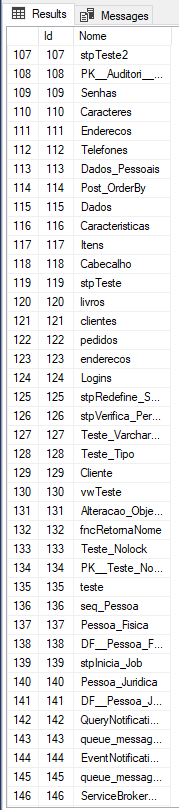
Bom, o mito foi desmistificado. Caiu por terra essa teoria que vale a pena ordenar os dados no INSERT para que não precise utilizar ORDER BY no SELECT.
Ou seja, nesse tipo de cenário você NUNCA deve utilizar o ORDER BY para inserir dados numa tabela, a não ser que tenha alguma cláusula de TOP no SELECT.
Agora vou explicar o porquê disso acontecer. Conforme já havia explicado no meu artigo “Entendendo o funcionamento dos índices no SQL Server“, quem é responsável por ordenar esses registros é o índice, uma vez que índices geralmente utilizam algoritmos como o QuickSort, que exigem que os dados estejam ordenados para obter o máximo de performance em operações de Seek.
Para demonstrar como o índice ordena os dados, vou criar um índice clustered e outro nonclustered na tabela e depois consultar os dados:
CREATE CLUSTERED INDEX SK01_Post_OrderBy ON dbo.Post_OrderBy(Id) WITH(FILLFACTOR=100)
CREATE NONCLUSTERED INDEX SK02_Post_OrderBy ON dbo.Post_OrderBy(Nome) WITH(FILLFACTOR=100)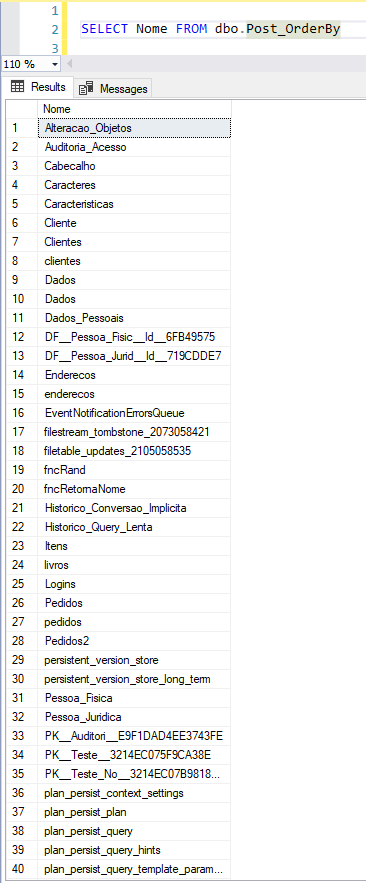
Viram como os dados ficaram ordenados? Bem legal, né?
Então podemos confiar que os índices vão manter os dados da minha tabela sempre ordenados e não preciso mais utilizar ORDER BY nem nas consultas? Não!
Os índices estão sujeitos a fragmentação dos dados, a medida em que os mesmos são inseridos/apagados/atualizados, perdendo a ordenação nas páginas dos índices.
No exemplo do índice que criei acima, especifiquei o FILLFACTOR do índice como 100%, ou seja, o índice vai ordenar todos os dados durante a criação e vai armazená-los de forma ordenada, tentando ocupar todas as páginas do índice (cada página contém 8 KB, entre dados e cabeçalhos), sem deixar nenhum espaço vago para eventuais novos dados que sejam inseridos/atualizados na tabela.
Ou seja, como o SQL Server não tem espaço livre no índice, se eu inserir um registro novo nessa tabela, esse registro não será inserido na ordem, e sim no final da última página (ou será criada uma nova página para ele, caso todas já estejam cheias).
Após a criação do meu índice, onde ele ordenou os registros, a fragmentação dos meus índices deve ser bem próxima de zero:
SELECT
OBJECT_NAME(B.object_id) AS TableName,
B.name AS IndexName,
A.index_type_desc AS IndexType,
A.avg_fragmentation_in_percent
FROM
sys.dm_db_index_physical_stats(DB_ID(), NULL, NULL, NULL, 'LIMITED') A
INNER JOIN sys.indexes B WITH(NOLOCK) ON B.object_id = A.object_id AND B.index_id = A.index_id
WHERE
OBJECT_NAME(B.object_id) = 'Post_OrderBy'
ORDER BY
A.avg_fragmentation_in_percent DESCResultado:

E agora forçaremos uma fragmentação dos dados utilizando o comando T-SQL abaixo:
-- Força a fragmentação do índice
DECLARE @Contador INT = 1, @Total INT = (SELECT COUNT(*) FROM dbo.Post_OrderBy)
WHILE(@Contador <= @Total)
BEGIN
UPDATE dbo.Post_OrderBy
SET Nome = REPLICATE(CHAR(65 + (ABS(CHECKSUM(PWDENCRYPT(N''))) / 2147483647.0) * 57), (ABS(CHECKSUM(PWDENCRYPT(N''))) / 2147483647.0) * 10)
WHERE Id = @Contador
INSERT INTO dbo.Post_OrderBy
SELECT [name]
FROM sys.objects
WHERE SUBSTRING([name], 1, 1) NOT IN ('D', 'H', 'M', 'T', 'S')
SET @Contador += 1
ENDAnalisando o nível de fragmentação do índice:

Será que meus dados continuaram ordenados com esse nível de fragmentação?
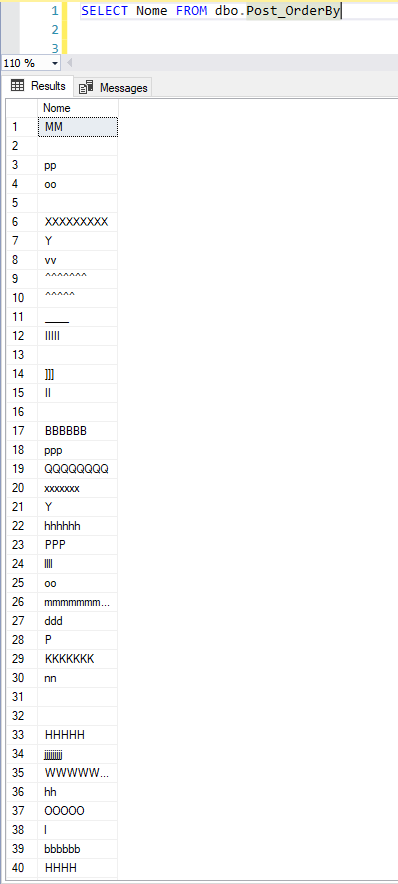
Agora bagunçou tudo. Para corrigir esse problema de fragmentação causado pelo script que utilizei acima, podemos utilizar as operações de REORGANIZE (recomendação: 5 a 30% de fragmentação) e REBUILD (recomendação: acima de 30% de fragmentação) para reordenar os dados no índice:
ALTER INDEX ALL ON dbo.Post_OrderBy REBUILDOu também pode ser feito o REBUILD/REORGANIZE em índices individuais:
ALTER INDEX SK01_Post_OrderBy ON dbo.Post_OrderBy REBUILD
ALTER INDEX SK02_Post_OrderBy ON dbo.Post_OrderBy REBUILDCom isso, a nossa fragmentação diminuiu:

E os dados estão ordenados novamente, mas será que podemos confiar apenas na ordenação dos índices para retornar dados ordenados? A resposta é: não! A única forma confiável de retornar dados de forma ordenada é através do ORDER BY.
Mas aí vem a pergunta chave: você precisa mesmo ordenar esses dados no banco? Em muitos cenários (para não dizer a maioria), a resposta é não.
Os dados podem ser perfeitamente consultados no banco sem ordenação, retornados para a aplicação e ordenados lá, na interface do usuário.
O problema dessa abordagem é que “dá mais trabalho” pro desenvolvedor e, por isso, dificilmente vemos esse cenário acontecer no dia a dia, o que é uma pena, pois é o cenário ideal, pois não muda nada para o usuário final e o banco não fica sobrecarregado com várias operações de ordenação em consultas “pesadas”.
Existem cenários em que o ORDER BY na consulta do banco é justificável? Sim, com certeza! Especialmente em cenários onde existe o operador TOP para retornar os TOP N maiores/menores registros de acordo com algum critério de ordenação.
Nesse caso, o ORDER BY é indicado, pois é melhor ordenar uma tabela de 10 milhões de registros no banco e retornar os 10 maiores, do que retornar todos os 10 milhões de registros e filtrar/ordenar isso na aplicação.
Bom, pessoal, espero que tenham gostado desse artigo e que tenham conseguido esclarecer algumas dúvidas sobre índices, fragmentação, fillfactor (depois vou criar um artigo mais detalhado sobre isso), quando o ORDER BY deve ser utilizado e quando nunca deve ser utilizado.
Se você é Desenvolvedor, peço encarecidamente que passe a considerar remover os ORDER BY das consultas e comece a ordenar esses registros na camada de aplicação ao invés do banco. O DBA e o banco de dados agradecem.
Você gosta de estudar sobre Performance Tuning? Não perca tempo e comece a ler meus artigos da série “Performance Tuning” e espero que termine essas leituras tendo uma outra visão do seu banco de dados.
Um grande abraço pra vocês e até o próximo artigo!

De 0 a 10, o quanto você recomendaria este artigo para um amigo?