

Um importante passo, que faz parte do projeto de um banco de dados, é decidir a melhor maneira de como forçar e garantir a integridade dos dados. A integridade pode ser forçada completa e unicamente na camada de aplicação, ou exclusivamente no nível da camada de dados (leia-se banco de dados), ou, ainda, através de uma abordagem híbrida (esta é a abordagem mais comumente utilizada). Discussões e polêmicas à parte, existe um mínimo de “coisas” que você deveria implementar na camada de banco, visando garantir a integridade. Iremos falar sobre isso no decorrer deste artigo.
Tipos de integridade de dados
Conceitualmente, existem três tipos de integridade de dados, conforme ilustra a figura abaixo.
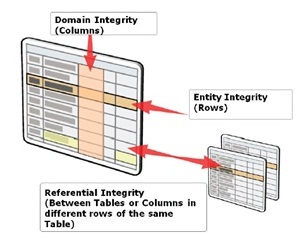
- Integridade de domínio (coluna): especifica o conjunto de valores válidos para uma determinada coluna, bem como se a coluna aceita nulo ou não.
- Integridade de entidade (linha): requer que cada linha seja identificada de forma única na tabela, ou seja, cada linha possui uma identificação exclusiva. Isso é normalmente chamado de chave primária (primary key).
- Integridade referencial (entre tabelas): mantém um relacionamento consistente entre a Tabela A e a Tabela B. A chave primária da Tabela A existe como uma coluna na Tabela B, onde é conceitualmente chamada de chave-estrangeira. Dessa forma, não será possível inserir um valor na coluna chave-estrangeira da Tabela B que não exista na coluna chave-primária da Tabela A. Por exemplo, não será possível inserir na tabela de Vendas o código de um cliente que não exista na tabela de Clientes.
Dentro do SQL Server, temos as seguintes opções para forçar e garantir a integridade de dados:
| Tipo de dados | Define o tipo de dados que a coluna pode armazenar. Exemplo: DATETIME2 |
| Nulidade | Determina se ou não um valor deve estar presente em uma coluna |
| Constraints | Define regras que limitam o conjunto de valores que podem ser armazenados em uma coluna ou, no nível da tabela, como os valores em diferentes colunas estão relacionados |
| Triggers | Define um código que é executado automaticamente quando uma tabela é modificada. Através disso, podemos aplicar restrições de valores e, inclusive, regras de negócio, dentre outras coisas. |
Nulidade de Coluna (NULL / NOT NULL)
Este mecanismo permite forçar a integridade de domínio. Ele define se uma coluna é obrigatória. Existem muitas bases de dados legadas por aí cuja questão da nulidade fica completamente a cargo da aplicação, enquanto que nas tabelas todas as colunas estão setadas para aceitar nulo. Este tipo de design é um risco!
Vejamos como implementar a nulidade em tabelas utilizando as opções NULL e NOT NULL. Neste ponto, estou destruindo e recriando o banco DBExame70461.
usemaster
GO
ifdb_id('DBExame70461')ISNOTNULL
BEGIN
alterdatabaseDBExame70461setsingle_userwithrollbackimmediate;
dropDATABASEDBExame70461;
END;
CREATEDATABASEDBExame70461;
GO
USE DBExame70461;
CREATETABLEdbo.Produto
( IdINTPRIMARYKEY,
NumeroINT,
NomeVARCHAR(50)NOTNULL,
DescricaoVARCHAR(500)NULL
);
INSERTdbo.Produto(Id,Nome)VALUES (1,'Melancia');
Explicitamente defini a coluna NOME como obrigatória e a coluna DESCRICAO como opcional. E a coluna NUMERO, é obrigatória? Por padrão, quando não explicitamos NULL ou NOT NULL, a coluna será nulável. E a coluna ID? Nesse caso, a coluna foi definida como chave-primária e, por consequência, ela será implicitamente criada como NOT NULL. Por fim, na instrução INSERT, eu especifiquei apenas as colunas não nuláveis (obrigatórias).
Nulo não é valor, pelo contrário, nulo indica ausência de valor.
Constraints
Como já foi mencionado, constraint é um mecanismo que permite restringir o conjunto de valores para uma dada coluna ou, no nível da tabela, como os valores de diferentes colunas estão relacionados (relacionamento entre colunas da mesma tabela ou entre colunas de tabelas diferentes). Os tipos de constraints são:
|
Default Values (Valor Padrão) |
Integridade de domínio (coluna) |
|
Check (Checagem / Verificação) |
Integridade de domínio (coluna) |
|
Primary Key (chave-primária) |
Integridade de entidade (linha) |
|
UNIQUE KEY (chave-única) |
Integridade de entidade (linha) |
|
Foreign Key (chave-estrangeira) |
Integridade referencial (entre colunas ou tabelas) |
DEFAULT Constraints
Este tipo de constraint fornece um valor padrão para uma coluna. Ter um valor padrão é um recurso útil nas instruções de INSERT. Vejamos abaixo.
USEDBExame70461; DROPTABLEdbo.Produto; CREATETABLEdbo.Produto ( IdINTPRIMARYKEYDEFAULT 1, NumeroINTDEFAULT 77, NomeVARCHAR(50)NOTNULLDEFAULT'Produto geral', DescricaoVARCHAR(500)NULLDEFAULT'Descrição geral' ); GO INSERTdbo.Produto(Id,Numero,Nome,Descricao) VALUES (DEFAULT,DEFAULT,DEFAULT,DEFAULT); INSERTdbo.Produto(Id,Numero,Nome,Descricao) VALUES (2, 88,'Batata',DEFAULT); INSERTdbo.Produto(Id) VALUES (3);
Note que destruí e recriei a tabela. Para criar a constraint, bastou adicionar a palavra reservada DEFAULT na instrução CREATE TABLE. No comando INSERT, usei a palavra DEFAULT para que seja gravado o valor padrão na respectiva coluna. Na terceira instrução INSERT, eu especifiquei apenas a coluna ID, omitindo as demais. Isso é válido quando as colunas omitidas são nuláveis ou possuem constraint default.
CHECK Constraints
Este tipo de constraint limita os valores que são permitidos em uma coluna. Vamos explorar algumas possibilidades.
CREATETABLEdbo.Vendedores
( IdINTNOTNULLPRIMARYKEY,
Nomevarchar(50)NOTNULL,
Sexochar(1)NULLCHECK (Sexoin('M','F'))DEFAULT'M',
ComissaointNOTNULL
constraintCk_Vendedores_Comissao
CHECK (ComissaoBETWEEN 1 AND 5),
TipoDeSalariovarchar(10)NOTNULL
CHECK (TipoDeSalarioin('Hora','Semana','Mes')),
Telefonevarchar(9)NULLCHECK (LEN(Telefone)>= 8)
);
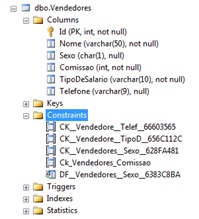
Para criar a constraint, bastou utilizar a palavra reservada CHECK na instrução CREATE TABLE. Na coluna COMISSAO, de forma explícita, informei o nome para a constraint: CK_Vendedores_Comissao. O benefício de criar uma constraint check com nome customizado é a facilidade em futuras alterações usando o comando ALTER TABLE. Note que para a coluna TELEFONE foi definida uma constraint que obriga o usuário a informar um número de telefone com pelo menos oito dígitos. Perceba, ainda, que para a coluna SEXO criei duas constraints: uma CHECK e outra DEFAULT. A figura abaixo mostra como ficou a tabela após a sua criação.
Vejamos o que acontece quando se tenta inserir, por exemplo, um registro de vendedor com uma comissão maior que 5% e com um número de telefone de 3 dígitos.
-- Tentando inserir registro com comissão acima de 5% INSERTdbo.Vendedores(Id,Nome,Sexo,Comissao,TipoDeSalario,Telefone) VALUES (1,'Antonio Silva','M', 7,'Mes', 123456789);

-- Tentando inserir registro com telefone de 3 dígitos INSERTdbo.Vendedores(Id,Nome,Sexo,Comissao,TipoDeSalario,Telefone) VALUES (1,'Antonio Silva','M', 5,'Mes', 123);
![]()
Agora, vamos falar de algo perigoso. Veja que definimos a coluna SEXO como nulável. Contudo, a constraint CHECK nessa coluna obriga informar apenas os valores M e F. Mas, o que acontecerá se tentarmos inserir um NULL nessa coluna? Devido ao fato de a coluna aceitar NULL, a constraint não considera um NULL como falso, ou, em outras palavras, o NULL é simplesmente ignorado.
-- Inserindocom sucesso um NULL na coluna SEXO INSERTdbo.Vendedores(Id,Nome,Sexo,Comissao,TipoDeSalario,Telefone) VALUES (1,'Antonio Silva',NULL, 1,'Mes', 123456789);
Imaginemos um cenário em que tenhamos de importar um arquivo texto contendo um cadastro de vendedores. Ao abrir o arquivo texto, notamos que foram informados valores de comissão fora da faixa de 1 a 5 (existem comissões zeradas e comissões maiores que 5). Para fazer a importação, será necessário desabilitar a constraint na coluna COMISSAO e, após a importação, reabilitá-la.
-- Desabilitando a constraint check da coluna COMISSAO ALTERTABLEdbo.Vendedores NOCHECKCONSTRAINTCK_Vendedores_Comissao; -- Inserindo valores fora da faixa de 1 a 5 INSERTdbo.Vendedores(Id,Nome,Sexo,Comissao,TipoDeSalario,Telefone) VALUES (2,'Jose','M', 7,'Mes', 123456789), (3,'Pedro','M', 0,'Mes', 123456789); -- Habilitando a constraint check da coluna COMISSAO ALTERTABLEdbo.Vendedores CHECKCONSTRAINTCK_Vendedores_Comissao;
Para eliminar uma constraint, independentemente do seu tipo (seja CHECK, DEFAULT, PRIMARY KEY, etc), faça conforme abaixo.
ALTERTABLEdbo.Vendedores
DROPCONSTRAINTCK_Vendedores_Comissao;
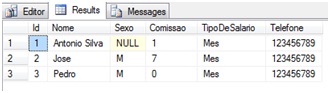
Imaginemos agora o seguinte cenário (absurdo diga-se de passagem): alterar a tabela e adicionar uma constraint que não permita cadastrar, para novas inserções, nomes de vendedores contendo a palavra SILVA. Atente para o fato de que a nossa tabela de VENDEDORES já contém uma pessoa com o sobrenome SILVA. Veja:
Vamos tentar criar essa constraint e ver o que acontece.
-- Tentando criar uma constraint na coluna NOME ALTERTABLEdbo.Vendedores ADDCONSTRAINTCK_Vendedores_NomeCHECK (NomeNOTLIKE'%Silva%');
O SQL Server retorna o seguinte erro:
Msg 547, Level 16, State 0, Line 1 The ALTER TABLE statement conflicted with the CHECK constraint "CK_Vendedores_Nome". The conflict occurred in database "DBExame70461", table "dbo.Vendedores", column 'Nome'.
Isso acontece porque no momento da criação da constraint o SQL Server verifica, por padrão, se existe algum valor na coluna que não atenda à regra especificada. Como o nosso cenário diz que essa regra deva ser aplicada apenas para “novas inserções”, vejamos como contornar tal situação.
ALTERTABLEdbo.VendedoresWITHNOCHECK
ADDCONSTRAINTCK_Vendedores_NomeCHECK (NomeNOTLIKE'%Silva%');
Usamos a opção WITH NOCHECK, a qual instrui o SQL Server a criar a constraint sem fazer qualquer verificação. Dessa forma, a constraint terá efeito somente para novas inserções. Exemplo:
INSERTdbo.Vendedores(Id,Nome,Sexo,Comissao,TipoDeSalario,Telefone) VALUES (4,'Bruno Silva','M', 2,'Mes', 123456789);

Table-Level CHECK Constraints
Além de checar valores para uma coluna em particular, uma constraint CHECK pode ser aplicada no nível da tabela para checar valores relacionados em mais de uma coluna (desde que sejam da mesma tabela). Segue exemplo.
CREATETABLEdbo.Ferias ( IdINTNOTNULLPRIMARYKEY, FuncionarioVARCHAR(50)NOTNULL, DataDeInicioDATETIME2NOTNULL, DataDeFimDATETIME2NOTNULL, CONSTRAINTCK_Ferias_PeriodoCHECK (DataDeInicio<DataDeFim) );
-- Tentando inserir uma Data de Início inválida INSERTdbo.Ferias(Id,Funcionario,DataDeInicio,DataDeFim) VALUES (1,'Mariana Souza','2012-10-31','2012-10-30');

Veja que a constraint check força a integridade, garantindo que a data de início não seja igual ou maior que a data de fim.
Integridade de entidade: Primary Key e Unique Key
ConstraintsPrimary Key (PK) e Unique Key (UK) são utilizadas para identificar unicamente uma linha em uma tabela. Tanto PKs quanto UKs podem envolver mais de uma coluna. Dessa forma, quando uma chave-primária é, por exemplo, constituída por mais de uma coluna, é dito que a chave-primária é composta. O mesmo se aplica às UKs.
Mas quais são as diferenças entre primary key e unique key?
Primary Key:
- Uma coluna que é envolvida em uma PK não pode ser nula;
- Só é possível existir uma chave-primária por tabela.
Unique Key:
- Uma coluna que é envolvida em uma UK pode ser nula;
- É possível existirem várias UK’s numa mesma tabela.
Primary Key
Mesmo estando fora do escopo deste artigo, bem como da pauta de conteúdos do exame 70-461, vale a pena mencionar os acalorados debates na comunidade acerca da melhor escolha de colunas para a formação de uma PK. Há quem defende o uso de Natural Key, que é a estratégia de utilizar uma ou mais colunas existentes na tabela. Outros defendem a adoção de Surrogate Key, que é a estratégia de utilizar um valor que não é natural ao dado, como, por exemplo, a geração automática de um número ou código. Deixo este tema, Natural Key versus Surrogate Key, como uma dica de pesquisa para você, amigo leitor.
Vejamos agora como criar chaves-primárias utilizando o bom e velho T-SQL.
useDBExame70461 go -- Criando diretamente na coluna CREATETABLEdbo.Pessoa ( IDINTNOTNULLPRIMARYKEY, Nomevarchar(50)NOTNULL);
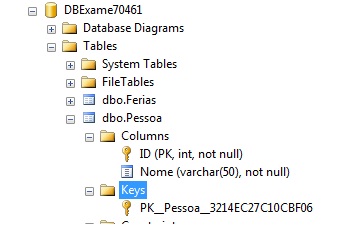
Note que o nome da constraint foi gerado automaticamente pelo SQL Server. Particularmente, prefiro explicitar um nome para a constraint, conforme a seguir.
-- Atribuindo nome customizado à constraint CREATETABLEdbo.Pessoa ( IDINTNOTNULLCONSTRAINTPK_PessoaPRIMARYKEY, Nomevarchar(50)NOTNULL);
Atente para o fato de que a coluna ID não pode aceitar NULL. Mas o que acontecerá se eu declarar uma constraint primary key, omitindo a questão da nulidade?
-- Criando sem explicitar a nulidade da coluna CREATETABLEdbo.Pessoa ( IDINTCONSTRAINTPK_PessoaPRIMARYKEY, Nomevarchar(50)NOTNULL);
Conforme já mencionamos em artigo anterior, quando não explicitamos se uma coluna é NULL ou NOT NULL, o SQL Server, por padrão, definirá como NULL. Contudo, se estivermos criando uma PK na coluna então o SQL Server irá, automaticamente, definir a coluna como NOT NULL. Lembre-se: uma coluna envolvida numa PK não pode ser nulável.
Outra alternativa para a criação de uma primary key é escrever conforme a seguir:
-- Criando uma PK no final da instrução CREATETABLEdbo.Pessoa ( IDINTNOTNULL, Nomevarchar(50)NOTNULL, CONSTRAINTPK_Pessoa PRIMARYKEY (ID) );
A grande vantagem da utilização dessa alternativa é a possibilidade da criação de PKs compostas de várias colunas. Veja:
CREATETABLEdbo.Orcamentos ( DataDATE, Cliente_IdINT, ValorDECIMAL(15,2)NOTNULL, ObsVARCHAR(500)NULL, CONSTRAINTPK_Orcamentos PRIMARYKEY (Data,Cliente_Id) );
Unique Key
Esta é uma constraint às vezes desprezada pelos projetistas de bancos. Por exemplo, o valor da coluna “LOGIN” da tabela “USUARIOS” deve ser exclusivo (sem duplicidade), pois não é permitido existir usuários com logins idênticos. Para satisfazermos essa regra, bastará a criação de uma UNIQUE KEY na coluna LOGIN.
Vejamos um exemplo:
CREATETABLEdbo.Material ( IDINTNOTNULL CONSTRAINTPK_MaterialPRIMARYKEY, NomeVARCHAR(50)NOTNULL, NumeroDoFabricanteINTNULL CONSTRAINTUK_Material_NumeroUNIQUE, );
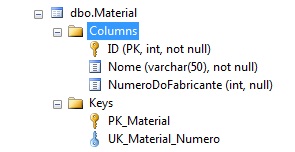
Perceba que a coluna “NumeroDoFabricante” é nulável. Conforme já comentado, isso é permitido, mas com a seguinte limitação: a quantidade de nulos não pode ser maior que 1. Vamos nos divertir explorando um exemplo.
-- Insere um registro com número do fabricante INSERTdbo.Material(ID,Nome,NumeroDoFabricante) VALUES (1,'Mesa 4x4', 100); -- Insere um registro setando NULL no número do fabricante INSERTdbo.Material(ID,Nome,NumeroDoFabricante) VALUES (2,'Mesa 5x6',NULL);
Até aqui temos as seguintes linhas na tabela:
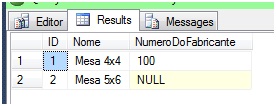
O que acontecerá se tentarmos inserir mais um registro contendo NULL na coluna “NumeroDoFabricante”?
-- Tentando inserir mais um registro com NULL no nº fabricante INSERTdbo.Material(ID,Nome,NumeroDoFabricante) VALUES (3,'Janela 2x2',NULL); Msg 2627, Level 14, State 1, Line 2 Violation of UNIQUE KEY constraint 'UK_Material_Numero'. Cannot insert duplicate key in object 'dbo.Material'. The duplicate key value is (<NULL>).
A lógica é simples: já existe um nulo na coluna e, portanto, um novo nulo representa duplicação.
Integridade referencial: Foreign Key
Uma constraint Foreign Key é usada para estabelecer uma ligação entre dados em tabelas, forçando um relacionamento consistente. Por exemplo, você pode querer se certificar de que existe um cliente antes de permitir que um pedido de vendas seja lançado para o cliente.
Uma Foreign Key, criada na tabela A, deve referenciar uma Primary Key ou uma Unique Key existente na tabela B. Além disso, uma foreign key pode ser criada referenciando uma PK ou UK da mesma tabela, produzindo, assim, um auto-relacionamento. É o caso do exemplo clássico da tabela EMPREGADO: um empregado é gerenciado por outro empregado, o qual tem papel de gerente.
CREATETABLEdbo.Clientes ( Idintnotnullprimarykey, Nomevarchar(50)notnull ); INSERTdbo.ClientesVALUES (1,'José'),(2,'Maria'); CREATETABLEdbo.Pedidos ( Idintnotnullprimarykey, Cliente_IdINTNOTNULL CONSTRAINTFK_Pedidos_x_ClienteFOREIGNKEYREFERENCESdbo.Clientes(Id), Datadatetime2notnull, Valordecimal(15,2)notnull, ); INSERTdbo.PedidosVALUES (1, 1,GETDATE(), 122.45);
O exemplo cria as tabelas CLIENTES e PEDIDOS, bem como uma foreign key na tabela PEDIDOS. Veja que explicitei um nome para a FK (FK_Pedidos_x_Clientes), o que é uma boa prática, já que facilita uma futura leitura e interpretação do modelo. Uma alternativa para a criação de uma foreign key é fazer conforme a seguir:
CREATETABLEdbo.Pedidos ( Idintnotnullprimarykey, Cliente_IdINTNOTNULL, Datadatetime2notnull, Valordecimal(15,2)notnull, CONSTRAINTFK_Pedidos_x_ClienteFOREIGNKEY (Cliente_Id) REFERENCESdbo.Clientes(Id) );
Mas o que acontecerá se tentarmos inserir um PEDIDO utilizando um ID inválido de cliente?
Declare@Cliente_IdINT= 3; INSERTdbo.Pedidos(Id,Cliente_Id,Data,Valor) VALUES (2,@Cliente_Id,GETDATE(), 122.45); Msg 547, Level 16, State 0, Line 2 The INSERT statement conflicted with the FOREIGN KEY constraint "FK_Pedidos_x_Cliente". The conflict occurred in database "DBExame70461", table "dbo.Clientes", column 'Id'.
Uma FK inclui uma opção chamada CASCADE, a qual permite que qualquer mudança de valor na PK ou UK da tabela referenciada, seja propagada, de forma automática, nas FKs. Quando não explicitamos a opção CASCADE, o padrão para o comportamento é NO ACTION. Veja a tabela abaixo para mais detalhes:
| Opção | Comportamento para o comando UPDATE | Comportamento para o comando DELETE |
| NO ACTION (default) | Não ocorre propagação. Um erro é retornado e um ROLLBACK é disparado. Por exemplo, se tentarmos deletar um cliente que possua pedidos, a exclusão falhará. Nesse caso, será necessário primeiro excluir os pedidos para então excluir o cliente. | |
| CASCADE | Propaga o valor modificado nas colunas das tabelas que fazem referência (FKs). | Deleta as linhas nas tabelas que fazem referência (FKs). |
| SET NULL | Seta NULL nas colunas das tabelas que fazem referência (FKs). | |
| SET DEFAULT | Seta para o valor default nas colunas das tabelas que fazem referência (FKs). | |
Particularmente, acho a opção CASCADE bastante perigosa. Por isso, recomendo cautela ao utilizá-la.
-- Dropa as tabelas de CLIENTES e PEDIDOS para recriá-las DROPTABLEdbo.Pedidos; DROPTABLEdbo.Clientes; go CREATETABLEdbo.Clientes ( Idintnotnullprimarykey, Nomevarchar(50)notnull ); INSERTdbo.ClientesVALUES (1,'José'),(2,'Maria'); CREATETABLEdbo.Pedidos ( Idintnotnullprimarykey, Cliente_IdINTNOTNULL, Datadatetime2notnull, Valordecimal(15,2)notnull, CONSTRAINTFK_Pedidos_x_Cliente FOREIGNKEY (Cliente_Id) REFERENCESdbo.Clientes(Id) ONDELETECASCADE ONUPDATECASCADE ); Declare@Cliente_IdINT= 1; INSERTdbo.Pedidos(Id,Cliente_Id,Data,Valor) VALUES (1,@Cliente_Id,GETDATE(), 122.45);
Até aqui, recriamos as tabelas usando uma foreign key com a opção cascade para as operações de DELETE e também de UPDATE. Agora, vamos excluir o cliente de ID = 1 e verificar o que acontece.
deletedbo.ClienteswhereId= 1; select*fromdbo.Pedidos;
Veja que a exclusão foi propagada e os pedidos do Cliente de ID = 1 também foram excluídos.

De 0 a 10, o quanto você recomendaria este artigo para um amigo?