

Fala, pessoal! Tudo na paz, né?
Neste artigo eu gostaria de falar sobre um problema de performance em consultas que encontramos bastante no nosso dia a dia na Fabrício Lima – Soluções em BD, uma das melhores e mais reconhecidas empresas de Performance Tuning do Brasil.
Estamos falando de algo que, muitas vezes, é terrivelmente simples de resolver e inexplicavelmente e extremamente comum: conversão implícita.
Para os exemplos deste artigo usarei a seguinte estrutura da tabela Pedidos:
CREATE TABLE dbo.Pedidos (
Id_Pedido INT IDENTITY(1,1),
Dt_Pedido DATETIME,
[Status] INT,
Quantidade INT,
Ds_Pedido VARCHAR(10),
Valor NUMERIC(18, 2)
)
CREATE CLUSTERED INDEX SK01_Pedidos ON dbo.Pedidos(Id_Pedido)
CREATE NONCLUSTERED INDEX SK02_Pedidos ON dbo.Pedidos (Ds_Pedido)
GOO que é conversão implícita?
A conversão implícita ocorre quando o SQL Server precisa converter o valor de uma ou mais colunas ou variáveis para outro tipo de dado com a finalidade de possibilitar a comparação, concatenação ou outra operação com outras colunas ou variáveis, já que o SQL Server não consegue comparar uma coluna do tipo varchar com outra, do tipo int, por exemplo, se ele não convertesse uma das colunas para que ambas tenham o mesmo tipo de dado.
Quando falamos de conversão, temos dois tipos:
Explícita: ocorre quando o próprio desenvolvedor da consulta faz a conversão dos dados utilizando funções como CAST, CONVERT, etc.
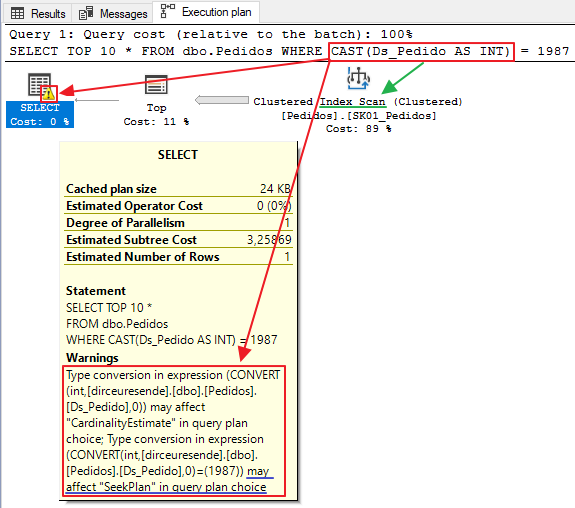
Implícita: ocorre quando o SQL Server é forçado a converter o tipo de dado entre colunas ou variáveis internamente, pois eles foram declarados com tipos diferentes.
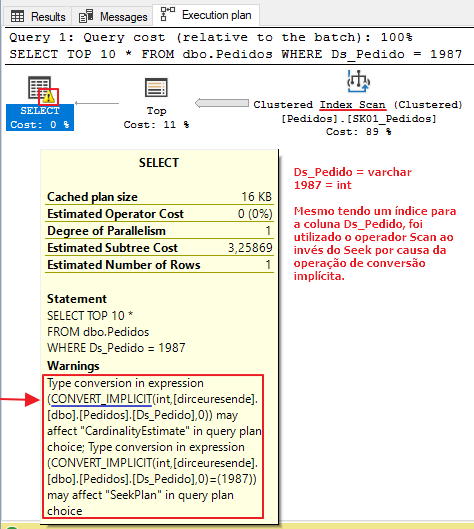
Como essa conversão é aplicada para todos os registros das colunas envolvidas, essa operação pode acabar sendo bem custosa e prejudicar bastante a execução da consulta, uma vez que mesmo que exista um índice para essas colunas, o otimizador de consultas acabará utilizando o operador Scan ao invés do Seek, não utilizando esse índice da melhor forma possível.
Como consequência, o tempo de execução e a quantidade de leituras lógicas (logical reads) pode acabar aumentando bastante.
Qual o impacto da conversão na minha consulta?
Como eu comentei acima, quando é necessário comparar dados com tipos diferentes, ou o desenvolvedor da query precisa fazer a conversão explícita utilizando CAST/CONVERT, ou o SQL Server terá que fazer a conversão implícita internamente para equalizar os tipos de dados.
Mas será que isso realmente vai fazer alguma diferença significativa na minha consulta? Vamos analisar.
Teste 1 – Utilizando o mesmo tipo de dado entre a coluna e a variável
Neste primeiro teste vamos utilizar a forma correta de se escrever as consultas. O tipo de dado da coluna (varchar) é o mesmo da variável literal (varchar) e não ocorre conversão de dados. Como resultado disso, a consulta será executada em 0ms, com apenas seis leituras lógicas no disco.

Teste 2 – Conversão implícita
No segundo teste, vou utilizar uma consulta simples, sem conversões de tipo de dados. Como a coluna Ds_Pedido é do tipo varchar e o valor literal 19870 é do tipo inteiro, o SQL Server terá que se encarregar de fazer a conversão (implícita) desses dados.

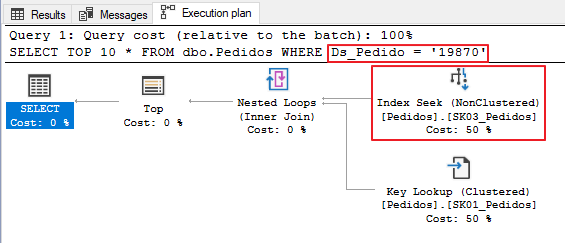
Teste 3 – Convertendo os tipos de dados (Conversão explícita)
Já nesse último teste, vou utilizar uma função de CAST para aplicar a conversão explícita e avaliar como a consulta de comportou em relação às outras duas consultas.

Conversão implícita só ocorre entre string e números?
Na verdade, não. Vou demonstrar alguns exemplos de conversão entre strings e strings, mas pode ocorrer entre strings e datas, uniqueidentifier e strings, etc.
VARCHAR e NVARCHAR
Um erro muito comum que vemos no dia a dia, é a ocorrência de conversão implícita entre valores/colunas varchar e nvarchar. Isso ocorre bastante em aplicações que utilizam ORMs, como o Entity Framework.
Muitas pessoas acabam achando que não há necessidade de conversão entre varchar e nvarchar, mas vamos observar no exemplo abaixo que isso ocorre, sim:
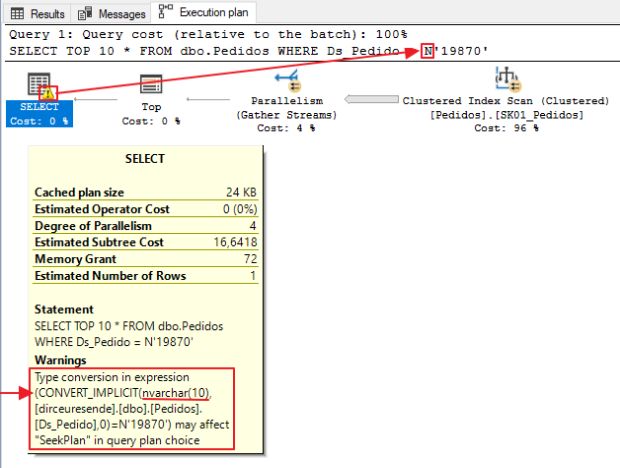
Outro exemplo, utilizando uma variável do tipo NVARCHAR(10):
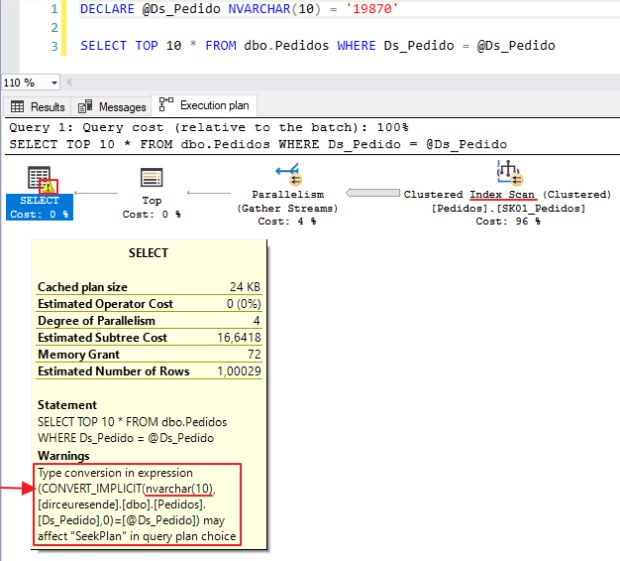
Conversão implícita não ocorre entre números com tipos diferentes?
Mais ou menos. Pode ocorrer a conversão implícita no operador Compute Scalar, mas não impede o uso do operador Seek.
Pelo fato dos números serem todos da mesma família, o SQL Server consegue comparar nativamente números com tipos de dados diferentes, como INT vs BIGINT, ou BIGINT vs SMALLINT, por exemplo.
Após uma dica do grande José Diz, acabei me atentando ao fato de que, ao utilizar algumas expressão com números de tipos de dados diferentes, não vemos um warning no plano de execução demonstrando a conversão implícita, e nem o operador Scan é utilizado ao invés do Seek, mas a conversão implícita ocorre, sim, no operador Compute Scalar, como vou demonstrar abaixo:
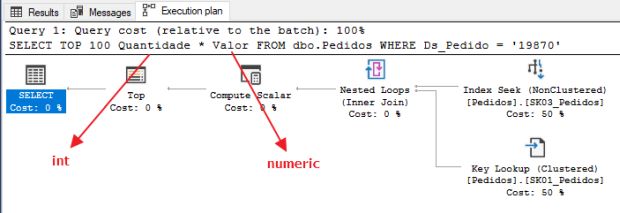
Antes de analisar a conversão implícita, criaremos um novo índice pra evitar esse operador de Key Lookup, numa técnica conhecida como “Cobrir o índice” (Covering index):
CREATE NONCLUSTERED INDEX SK05_Pedidos ON dbo.Pedidos (Ds_Pedido) INCLUDE(Quantidade, Valor)Para saber mais sobre o Covering Index e entender porque criei o índice dessa forma, dê uma lida no artigo abaixo:
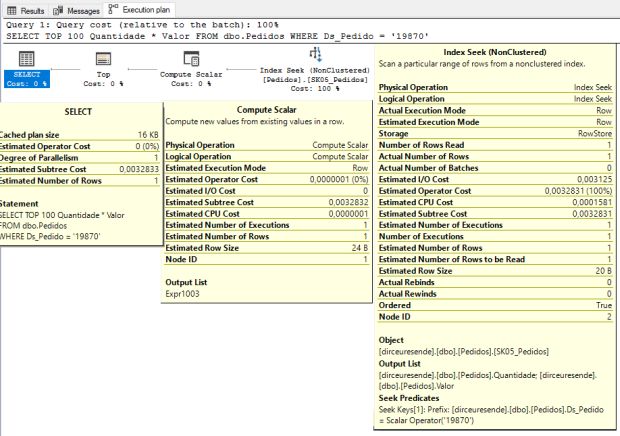
Analisando novamente o plano de execução, vemos que o operador Key Lookup saiu do plano, o índice novo está sendo utilizado com o operador Seek e não tem Warning de conversão implícita. Onde ela está ?
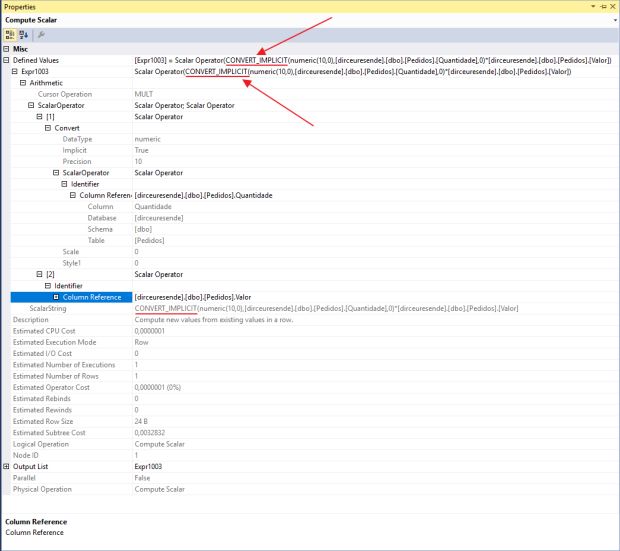
Ao visualizar as propriedades do operador Compute Scalar, conseguimos identificar que o SQL Server fez a conversão implícita para realizar a multiplicação da coluna Valor (numeric) pela coluna Quantidade (int):
No artigo “Implicit Conversions that cause Index Scans“, de Jonathan Kehayias, ele fez uma série de testes entre vários tipos de dados e o resultado desse estudo é a tabela abaixo, que demonstra quais cruzamentos entre tipos de dados causam o evento de Scan ao invés do Seek ao serem comparados:
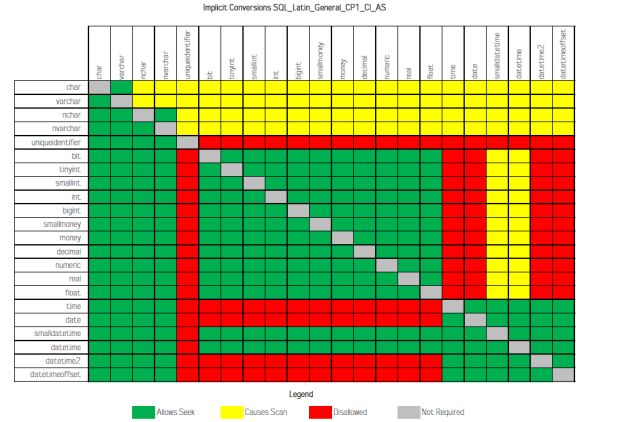
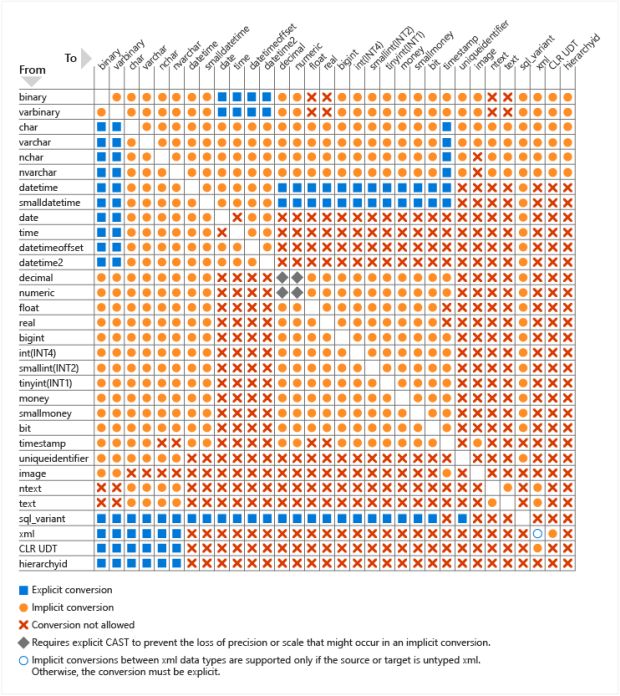
Na documentação oficial do SQL Server, podemos encontrar a tabela abaixo, que ilustra quais os cruzamentos entre tipos de dados que geram conversão implícita, quais precisam utilizar conversão explícita e quais conversões não são possíveis:
Ocorre conversão implícita em JOIN também?
Em qualquer operação ou comparação de expressão com tipos de dados diferentes, pode ocorrer a conversão implícita (de acordo com as regras vistas acima), seja no SELECT, WHERE, JOIN, CROSS APPLY, etc, conforme vou demonstrar abaixo.
Criei uma tabela chamada Pedidos2, com a mesma estrutura e dados da tabela Pedidos. Em seguida, efetuei uma operação de ALTER TABLE para modificar o tipo de dado da coluna Ds_Pedido para NVARCHAR(10) e com isso, temos o seguinte exemplo:
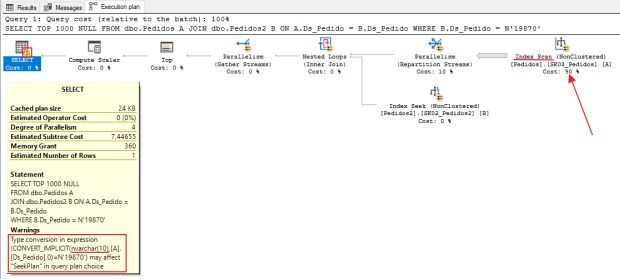
Reparem que houve uma conversão implícita entre as colunas Ds_Pedido, já que na tabela Pedidos ela é do tipo VARCHAR e na tabela Pedidos2 ela é do tipo NVARCHAR.
Por conta disso, ao invés de utilizar a operação de Index Seek, foi utilizada a Index Scan para ler os dados da tabela Pedidos.
Se analisarmos a quantidade de leituras das duas tabelas, vemos uma diferença gritante por conta da conversão implícita:

Neste caso, podemos observar um erro grave de modelagem dos dados, que permitiu que duas tabelas que tenham relacionamentos entre si utilizem tipos de dados diferentes.
Para resolver esse problema de performance nesse cenário e obter o máximo de desempenho dessa consulta, vamos alterar o tipo da coluna Ds_Pedido na tabela Pedidos para nvarchar(10), o mesmo tipo da tabela Pedidos2, já que o filtro utilizado no WHERE é do tipo NVARCHAR:
ALTER TABLE Pedidos ALTER COLUMN Ds_Pedido nvarchar(10)Mas aí encontramos esse erro durante a tentativa de alterar o tipo de dado da coluna:
Msg 5074, Level 16, State 1, Line 8
The index ‘SK03_Pedidos’ is dependent on column ‘Ds_Pedido’.
Msg 4922, Level 16, State 9, Line 8
ALTER TABLE ALTER COLUMN Ds_Pedido failed because one or more objects access this column.
Aviso: como essa coluna é indexada, não podemos alterar o tipo. Isso vai exigir que a gente apague o índice, apague possíveis chaves de foreign keys, faça a alteração da coluna e depois recrie o índice e/ou foreign key.
Ou seja, não é tão simples assim resolver esse tipo de problema, especialmente quando estamos falando de ambiente de produção, onde alterar o tipo de uma coluna ou a criação de um índice pode gerar vários locks.
Isso sem falar que podem existir outros relacionamentos entre essa tabela e outras utilizando essa coluna, que hoje funcionam bem, e que podem começar a ter problema de conversão implícita ao alterar o tipo de dado. Como tudo em performance, fazer esse tipo de correção exige validações, análises e muitos testes!
Se você precisar de um script para identificar e recriar Foreign Keys que referenciam uma tabela, dê uma lida no meu artigo “Como identificar, apagar e recriar Foreign Keys (FK) de uma tabela no SQL Server“.
No caso acima vamos considerar que o fato dessa coluna ser do tipo VARCHAR foi um erro de modelagem e vamos corrigir o problema.
Para isso, vou utilizar os comandos T-SQL abaixo, para apagar o índice, realizar a alteração do tipo e criar o índice novamente:
DROP INDEX SK03_Pedidos ON dbo.Pedidos
GO
ALTER TABLE Pedidos ALTER COLUMN Ds_Pedido nvarchar(10)
GO
CREATE NONCLUSTERED INDEX [SK03_Pedidos] ON [dbo].[Pedidos] ([Ds_Pedido])
GOApós igualar o tipo dos dados entre as duas colunas, vamos repetir a consulta feita anteriormente e analisar os resultados:
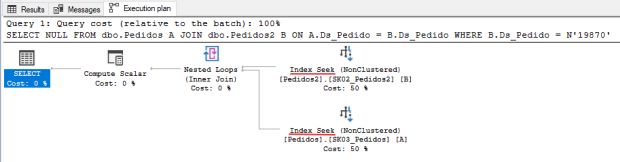
Agora o plano de execução ficou excelente. Eliminamos a conversão implícita e estamos utilizando operadores Seek nos índices. Vamos ver como ficou o tempo de execução e as leituras lógicas:

Tempo de execução 0ms e apenas três leituras lógicas. Excelente! Consulta otimizada.
Mas e nos casos onde não podemos realizar o comando ALTER TABLE devido a outros relacionamentos que já existem? Quais alternativas temos para isso?
Existem várias soluções, mas uma que gosto muito é a utilização de colunas calculadas e indexadas, que possuem baixo impacto para a aplicação (embora possa ter impacto, sim, especialmente em operações de INSERT) e costumam ser bem eficazes e práticas, já que sempre que a coluna original for alterada, a coluna calculada é atualizada automaticamente também (assim como índices que referenciam a coluna calculada, se existirem). Mas lembrem-se:
- Testem antes de implementar!
Vou demonstrar como você pode implementar essa solução no exemplo acima:
ALTER TABLE dbo.Pedidos ADD Ds_Pedido_NVARCHAR AS (CONVERT(NVARCHAR(10), Ds_Pedido))
GO
CREATE NONCLUSTERED INDEX SK04_Pedidos ON dbo.Pedidos(Ds_Pedido_NVARCHAR)
GOAo criar essa coluna calculada, ela não vai ocupar nada de espaço no seu banco, pois ela é calculada em tempo real. Apenas o índice criado que ocupará espaço, e ele que irá trazer o ganho de performance para essa solução:
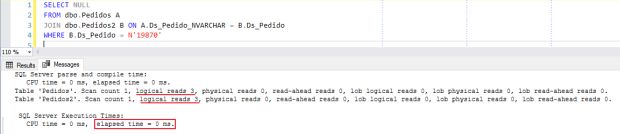
Se analisarmos o nosso plano de execução utilizando a nova coluna calculada, vemos que ele está sem conversão implícita e fazendo operação de Seek, igualzinho quando eu demonstrei como seria se as colunas fossem do mesmo tipo:
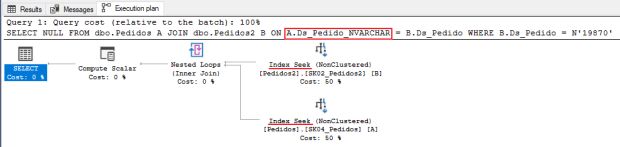
Como o SQL Server escolhe qual tipo que será convertido?
Essa é uma excelente dúvida. Como podemos consultar da página Precedência de tipo de dados, pertencente à documentação da Microsoft, quando um operador combina duas expressões de tipos de dados diferentes, as regras para precedência de tipo de dados especificam que o tipo de dados com a precedência inferior é convertido para o tipo de dados com a precedência mais alta. Se a conversão não for uma conversão implícita com suporte, será retornado um erro.
O SQL Server usa a seguinte ordem de precedência para tipos de dados:
- 1. tipos de dados personalizados do usuário (maior nível)
- 2. sql_variant
- 3. xml
- 4. datetimeoffset
- 5. datetime2
- 6. datetime
- 7. smalldatetime
- 8. date
- 9. time
- 10. float
- 11. real
- 12. decimal
- 13. money
- 14. smallmoney
- 15. bigint
- 16. int
- 17. smallint
- 18. tinyint
- 19. bit
- 20. ntext
- 21. text
- 22. image
- 23. timestamp
- 24. uniqueidentifier
- 25. nvarchar (incluindo nvarchar(max) )
- 26. nchar
- 27. varchar (incluindo varchar(max) )
- 28. char
- 29. varbinary (incluindo varbinary(max) )
- 30. binary (menor nível)
Ou seja, por isso que no exemplo acima, quando comparamos uma coluna varchar com uma expressão nvarchar, a coluna foi convertida para nvarchar, e não o contrário (que até fazia mais sentido converter um valor fixo do que uma coluna inteira).
Como identificar as conversões implícitas no seu ambiente
Como eu falei anteriormente, operações de conversão implícita são muito comuns em ambientes SQL Server e, por isso, vou compartilhar duas formas de identificar a ocorrência desses eventos no seu ambiente.
Método 1 – DMVs do Plan cache
Utilizando o script abaixo, você poderá identificar as consultas que mais consumiram CPU e possuem conversão implícita através de DMV’s do SQL Server. Não é necessário ativar nenhuma opção ou criar nenhum objeto, pois essas consultas são nativas e coletadas automaticamente, por padrão.
Resultado:
![]()
Método 2 – Extended Events (XE)
Utilizando o script abaixo, você poderá capturar os eventos de conversão implícitas gerados através de eventos do Extended Events.
A vantagem dessa solução sobre a consulta ao plancache, é que os dados ficam armazenados de forma definitiva, já que a plan cache é “truncada” sempre que o serviço do SQL Server é reiniciado. Nem todas as consultas ficam armazenadas lá, e quando são, o armazenamento é temporário.
Além disso, se você iniciar o serviço utilizando o parâmetro -x, várias DMVs, como a dm_exec_query_stats, não são populadas.
A desvantagem é que você precisa criar objetos no banco (Job, XE, tabela), gerando um trabalho bem maior para obter essa informação, que só será coletada a partir da criação desses controles. Os eventos que ocorreram no passado, não serão identificados.
Script do XE:
IF (EXISTS(SELECT NULL FROM sys.dm_xe_sessions WHERE [name] = 'Conversão Implícita')) DROP EVENT SESSION [Conversão Implícita] ON SERVER
GO
CREATE EVENT SESSION [Conversão Implícita]
ON SERVER
ADD EVENT sqlserver.plan_affecting_convert (
ACTION (
sqlserver.client_app_name,
sqlserver.client_hostname,
sqlserver.database_name,
sqlserver.username,
sqlserver.sql_text
)
WHERE (
[convert_issue] = 2 -- 1 = Cardinality Estimate / 2 = Seek Plan
)
)
ADD TARGET package0.event_file (
SET filename = N'C:\Traces\Conversão Implícita',
max_file_size = ( 50 ),
max_rollover_files = ( 16 )
)
GO
ALTER EVENT SESSION [Conversão implícita] ON SERVER STATE = START
GOApós criar esse XE, você pode utilizar o script abaixo para coletar os dados e gravá-los numa tabela de histórico.
IF (OBJECT_ID('dbo.Historico_Conversao_Implicita') IS NULL)
BEGIN
-- DROP TABLE dbo.Historico_Conversao_Implicita
CREATE TABLE dbo.Historico_Conversao_Implicita (
Dt_Evento DATETIME,
[database_name] VARCHAR(100),
username VARCHAR(100),
client_hostname VARCHAR(100),
client_app_name VARCHAR(100),
[convert_issue] VARCHAR(50),
[expression] VARCHAR(MAX),
sql_text XML
)
CREATE CLUSTERED INDEX SK01_Historico_Erros ON dbo.Historico_Conversao_Implicita(Dt_Evento)
END
DECLARE @TimeZone INT = DATEDIFF(HOUR, GETUTCDATE(), GETDATE())
DECLARE @Dt_Ultimo_Evento DATETIME = ISNULL((SELECT MAX(Dt_Evento) FROM dbo.Historico_Conversao_Implicita WITH(NOLOCK)), '1990-01-01')
IF (OBJECT_ID('tempdb..#Eventos') IS NOT NULL) DROP TABLE #Eventos
;WITH CTE AS (
SELECT CONVERT(XML, event_data) AS event_data
FROM sys.fn_xe_file_target_read_file(N'C:\Traces\Conversão Implícita*.xel', NULL, NULL, NULL)
)
SELECT
DATEADD(HOUR, @TimeZone, CTE.event_data.value('(//event/@timestamp)[1]', 'datetime')) AS Dt_Evento,
CTE.event_data
INTO
#Eventos
FROM
CTE
WHERE
DATEADD(HOUR, @TimeZone, CTE.event_data.value('(//event/@timestamp)[1]', 'datetime')) > @Dt_Ultimo_Evento
SET QUOTED_IDENTIFIER ON
INSERT INTO dbo.Historico_Conversao_Implicita
SELECT
A.Dt_Evento,
A.[database_name],
A.username,
A.client_hostname,
A.client_app_name,
A.convert_issue,
A.expression,
TRY_CAST(A.sql_text AS XML) AS sql_text
FROM (
SELECT DISTINCT
A.Dt_Evento,
xed.event_data.value('(action[@name="database_name"]/value)[1]', 'varchar(100)') AS [database_name],
xed.event_data.value('(action[@name="username"]/value)[1]', 'varchar(100)') AS [username],
xed.event_data.value('(action[@name="client_hostname"]/value)[1]', 'varchar(100)') AS [client_hostname],
xed.event_data.value('(action[@name="client_app_name"]/value)[1]', 'varchar(100)') AS [client_app_name],
xed.event_data.value('(data[@name="convert_issue"]/text)[1]', 'varchar(100)') AS [convert_issue],
xed.event_data.value('(data[@name="expression"]/value)[1]', 'varchar(max)') AS [expression],
xed.event_data.value('(action[@name="sql_text"]/value)[1]', 'varchar(max)') AS [sql_text]
FROM
#Eventos A
CROSS APPLY A.event_data.nodes('//event') AS xed (event_data)
) AE agora é só criar 1 job para coletar esses dados de forma periódica. Para acessar os dados coletados, basta consultar a tabela recém criada para analisar as ocorrências de conversão implícitas no seu ambiente:

Outros artigos sobre Conversão Implícita
Quer outros pontos de vista e exemplos sobre esse tema? Vejam alguns artigos de outros autores que separei para vocês:
- Os perigos da conversão implícita – Parte 01
- Os perigos da conversão implícita – Parte 02
- Join Performance, Implicit Conversions, and Residuals
- Implicit Conversions that cause Index Scans
- Are Implicit Conversions Killing Your SQL Query Performance?
- Data type conversion (Database Engine)
Bom, pessoal, espero que tenham gostado deste artigo e compreendido os perigos da conversão explícita e implícita. Não deixem isso acontecer mais nas suas consultas – o DBA agradece.
Forte abraço e até a próxima!

De 0 a 10, o quanto você recomendaria este artigo para um amigo?