



Otimizando índices compostos no MongoDB

Como criar o melhor índice para uma query complexa MongoDB? Vou apresentar um método específico para consultas que combinam testes de igualdade, de tipo e de range, e demonstra a melhor ordem para campos em um índice composto. Daremos uma olhada na saída explain() para ver exatamente quão bem ela executa e veremos também como o otimizador de consulta do MongoDB seleciona um índice.
A configuração
Vamos fingir que estou construindo um sistema de comentários, como Disqus no MongoDB. (Eles realmente usam Postgres, mas eu estou pedindo para você usar a sua imaginação.) Pretendo armazenar milhões de comentários, mas vou começar com quatro. Cada um tem um timestamp uma classificação de qualidade, e um deles foi postado por um covarde anônimo:
{ timestamp: 1, anonymous: false, rating: 3 }
{ timestamp: 2, anonymous: false, rating: 5 }
{ timestamp: 3, anonymous: true, rating: 1 }
{ timestamp: 4, anonymous: false, rating: 2 }
Quero consultar comentários que não sejam anônimos com timestamps de 2 a 4, e ordená-los por classificação. Vamos construir a consulta em três etapas e analisar o melhor índice para cada uma, usando explain() do MongoDB.
Consulta de Range
Vamos começar com uma consulta de range simples para comentários com timestamps de 2 a 4:
> db.comments.find( { timestamp: { $gte: 2, $lte: 4 } } )
Existem três obviamente. O explain() mostra como o Mongo os encontrou:
> db.comments.find( { timestamp: { $gte: 2, $lte: 4 } } ).explain()
{
"cursor" : "BasicCursor",
"n" : 3,
"nscannedObjects" : 4,
"nscanned" : 4,
"scanAndOrder" : false
// ... snipped output ...
}
Veja como ler um query plan do MongoDB: primeiro, note o tipo de cursor. “BasicCursor” é um sinal de alerta: significa que o MongoDB teve que fazer uma varredura completa da coleção. Isso não vai funcionar quando eu tiver milhões de comentários, assim que eu adicionar um índice em timestamp:
> db.comments.createIndex( { timestamp: 1 } )
A saída explain() agora é:
> db.comments.find( { timestamp: { $gte: 2, $lte: 4 } } ).explain()
{
"cursor" : "BtreeCursor timestamp_1",
"n" : 3,
"nscannedObjects" : 3,
"nscanned" : 3,
"scanAndOrder" : false
}
Agora, o tipo de cursor é “BtreeCursor” mais o nome do índice que eu fiz. “nscanned” caiu de 4 para 3, porque o Mongo utilizou um índice para ir diretamente aos documentos de que precisava, pulando aquele cujo timestamp está fora de alcance.
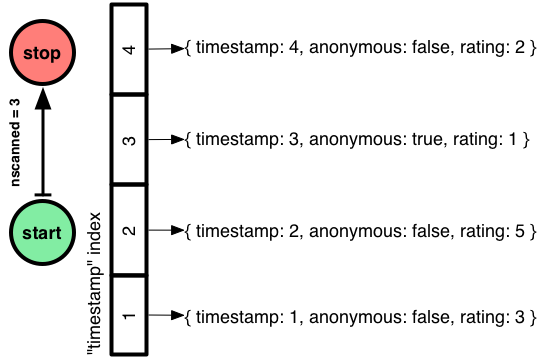
Para queries indexadas, nscanned é o número de chaves de índice no range que o Mongo escaneou, e nscannedObjects é o número de documentos que ele analisou para chegar ao resultado final. nscannedObjects inclui pelo menos todos os documentos devolvidos, mesmo que o Mongo pudesse dizer que o documento era definitivamente uma correspondência só de olhar para o índice. Assim, você sempre pode ver nscanned >= nscannedObjects >= n. (Bem, a menos Mongo usa um covered index). Para queries simples, você quer que os três números sejam iguais. Significa que você criou o índice ideal e que o Mongo o está usando.
Igualdade mais consultas de Range
Em qual situação o nscanned seria superior a n? A resposta é simples: quando o Mongo precisou examinar algumas chaves de índice que apontam para documentos que não correspondem à query. Por exemplo, vou filtrar comentários anônimos:
> db.comments.find(
... { timestamp: { $gte: 2, $lte: 4 }, anonymous: false }
... ).explain()
{
"cursor" : "BtreeCursor timestamp_1",
"n" : 2,
"nscannedObjects" : 3,
"nscanned" : 3,
"scanAndOrder" : false
}
Embora n tenha caído para 2, nscanned e nscannedObjects continuaram em 3. O Mongo escaneou o índice timestamp de 2 e 4, que inclui tanto os comentários assinados quanto os do anônimo, e não podia filtrar este último até que ele mesmo tivesse examinado o documento.
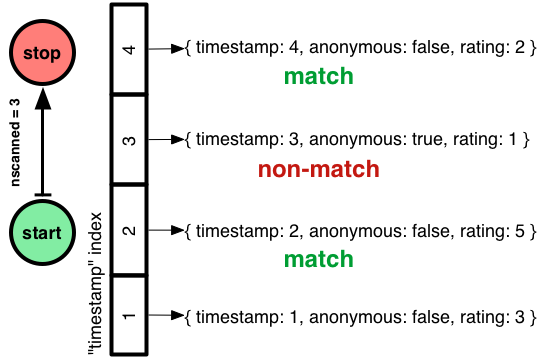
Como faço para que meu query plan ideal volte, onde nscanned = nscannedObjects = n? Eu poderia tentar um índice composto em timestamp e anônimo:
> db.comments.createIndex( { timestamp:1, anonymous:1 } )
> db.comments.find(
... { timestamp: { $gte: 2, $lte: 4 }, anonymous: false }
... ).explain()
{
"cursor" : "BtreeCursor timestamp_1_anonymous_1",
"n" : 2,
"nscannedObjects" : 2,
"nscanned" : 3,
"scanAndOrder" : false
}
Isto é ainda melhor: nscannedObjects diminuiu de 3 para 2. Mas nscanned ainda é 3! O Mongo teve que escanear o range do índice de (timestamp 2, anonymous false) a (timestamp 4, anonymous false), incluindo a entrada (timestamp 3, anonymous true). Quando ele escaneou aquela entrada do meio, o Mongo a viu apontando para um comentário anônimo e pulando-a, sem inspecionar o próprio documento. Assim, o comentário incógnito é cobrado contra nscanned, mas não contra nscannedObjects, e nscannedObjects é apenas 2.
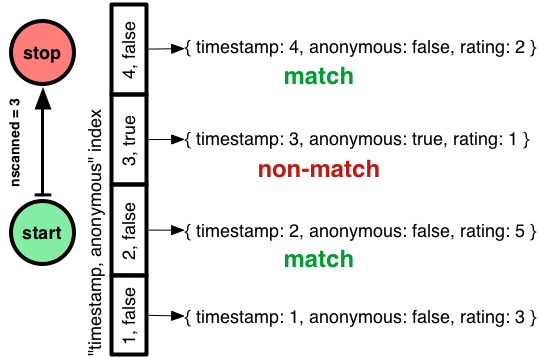
Posso melhorar esse plano? Posso baixar nscanned para 2 também? Você provavelmente sabe disto: a ordem em que declarei os campos do meu índice composto estava errada. Não deveria ser “timestamp, anonymous”, mas “anonymous, timestamp”:
> db.comments.createIndex( { anonymous:1, timestamp:1 } )
> db.comments.find(
... { timestamp: { $gte: 2, $lte: 4 }, anonymous: false }
... ).explain()
{
"cursor" : "BtreeCursor anonymous_1_timestamp_1",
"n" : 2,
"nscannedObjects" : 2,
"nscanned" : 2,
"scanAndOrder" : false
}
A ordem é importante em índices compostos do MongoDB, como com qualquer banco de dados. Se eu fizer um índice com “anonymous” primeiro, o Mongo pode ir direto para a seção do índice com comentários assinados, em seguida, fazer uma série de digitalização de timestamp 2 a 4.
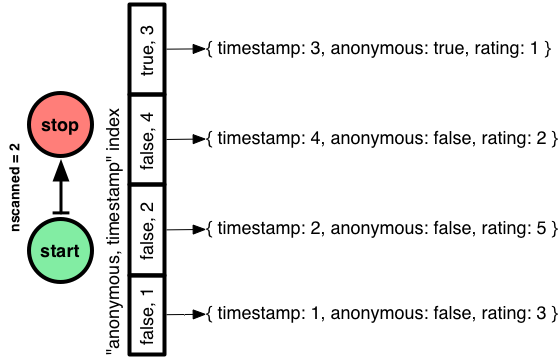
Então eu mostrei a primeira parte da minha heurística: testes de igualdade antes de filtros range!
Vamos considerar se a inclusão de “anonymous” no índice valeu a pena. Em um sistema com milhões de comentários e milhões de queries por dia, reduzir o nscanned pode melhorar consideravelmente o rendimento. Além disso, se a seção anônima do índice for raramente usada, ela pode ser excluída do disco e abrir espaço para as seções mais intensas. Por outro lado, um índice de dois campos é maior do que um índice de um e precisa de mais RAM, de modo que o ganho possa ser compensado pelos custos. Provavelmente, o índice composto é uma vitória, se uma proporção significativa dos comentários é anônima, caso contrário, não.
Digressão: como MongoDB escolhe um índice
Não vamos ignorar uma pergunta interessante. No exemplo anterior, eu criei primeiro um índice em “timestamp”, depois em “timestamp, anonymous”, e finalmente em “anonymous, timestamp”. O Mongo escolheu o índice final e superior para a minha consulta. Como?
O otimizador do MongoDB escolhe um índice para uma query em duas fases. Na primeira, ele procura uma evidência de um “índice ideal” para a consulta. Já na segunda, se nenhum índice desse tipo existir, ele executa uma experiência para ver qual índice realmente funciona melhor. O otimizador se lembra de sua escolha para todas as queries semelhantes. (Até mil documentos são modificados ou um índice for adicionado ou removido.).
O que faz o otimizador considerar um “índice ideal” para uma query? O índice ideal deve incluir todos os campos da query filtrados e campos de classificação. Além disso, os campos de range filtrados ou tipo da consulta devem vir após os campos de igualdade. (Se houver vários índices ideais, o Mongo escolhe um de forma arbitrária.) No meu exemplo, o índice “anonymous, timestamp” é visivelmente melhor, então o MongoDB o escolhe imediatamente.
Essa não é uma explicação super estimulante, por isso vou descrever como a segunda fase funcionaria. Quando o otimizador precisa escolher um índice e nenhum é obviamente o melhor, ele reúne todos os índices relevantes para a query e coloca-os uns contra os outros em uma corrida para ver quem termina, ou encontra 101 documentos, primeiro.
Aqui está a minha query novamente:
db.comments.find({ timestamp: { $gte: 2, $lte: 4 }, anonymous: false })
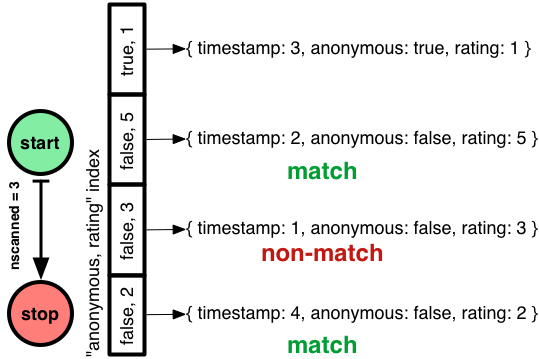
Todos os três índices são relevantes, então o MongoDB alinha-os em uma ordem arbitrária e avança cada índice uma entrada de cada vez:

(Omiti a classificação para abreviar, estou apenas mostrando timestamps e anonymosity dos documentos.)
Todos os índices retornam
{ timestamp: 2, anonymous: false, rating: 5 }
primeiro. Na segunda passagem através dos índices, os da esquerda e do meio retornam
{ timestamp: 3, anonymous: true, rating: 1 }
que não é uma correspondência, e o nosso índice campeão na direita retorna
{ timestamp: 4, anonymous: false, rating: 2 }
que é uma correspondência. Agora, o índice à direita é concluído antes dos outros, por isso é declarado o vencedor e usado até a próxima corrida.
Em suma: se existem vários índices úteis, o MongoDB escolhe aquele que dá o menor nscanned.
Igualdade, consulta Range e classificação
Agora tenho o índice perfeito para encontrar comentários assinados com timestamps entre 2 e 4. O último passo é classificá-los, com a melhor classificação primeiro:
> db.comments.find(
... { timestamp: { $gte: 2, $lte: 4 }, anonymous: false }
... ).sort( { rating: -1 } ).explain()
{
"cursor" : "BtreeCursor anonymous_1_timestamp_1",
"n" : 2,
"nscannedObjects" : 2,
"nscanned" : 2,
"scanAndOrder" : true
}
Esse é o mesmo plano de acesso de antes, e ainda sim é bom: nscanned = nscannedObjects = n. Mas agora “scanAndOrder” é verdadeiro. Isso significa que o MongoDB teve que processar em lote todos os resultados na memória, classificá-los e, em seguida, retorná-los. Muitas coisas ruins aparecem. Em primeiro lugar, isso custa RAM e CPU no servidor. Além disso, em vez fazer streaming de meus resultados em lotes, o Mongo apenas despeja-os todos para a rede de uma só vez, sobrecarregando a RAM em meus servidores de aplicativos. E, finalmente, o Mongo impõe um limite de 32 MB de dados que irá classificar na memória. Nós estamos lidando apenas com quatro comentários agora, mas estamos projetando um sistema para lidar com milhões!
Como posso evitar scanAndOrder? Eu quero um índice no qual o Mongo possa ir para a seção não anônima e verificá-la na ordem classificação de cima para baixo:
> db.comments.createIndex( { anonymous: 1, rating: 1 } )
O Mongo vai usar esse índice? Não, porque ele não vence a corrida para o menor nscanned. O otimizador não considera se o índice contribui com a classificação. (1)
Vou usar uma dica para forçar a escolha do Mongo:
> db.comments.find(
... { timestamp: { $gte: 2, $lte: 4 }, anonymous: false }
... ).sort( { rating: -1 }
... ).hint( { anonymous: 1, rating: 1 } ).explain()
{
"cursor" : "BtreeCursor anonymous_1_rating_1 reverse",
"n" : 2,
"nscannedObjects" : 3,
"nscanned" : 3,
"scanAndOrder" : false
}
O argumento para hint é o mesmo que createIndex. Agora nscanned subiu para 3, mas scanAndOrder é falsa. O Mongo caminha pelo índice “anonimous, rating” no sentido inverso, recebendo comentários na ordem correta, e então verifica cada documento para ver se o seu timestamp está no range.
É por isso que o otimizador não vai escolher esse índice, mas prefere ir com o velho índice “anonymous, timestamp”, que requer um tipo de memória, mas que possui um nscanned menor.
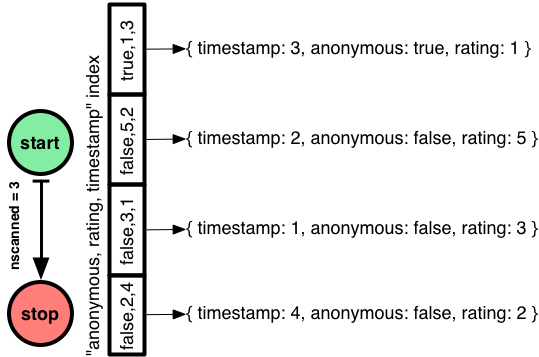
Então, resolvi o problema scanAndOrder, ao custo de um nscanned superior. Eu não posso reduzir nscanned, mas posso reduzir nscannedObjects? Vou colocar o timestamp no índice, então o Mongo não tem que começar a partir de cada documento:
> db.comments.createIndex( { anonymous: 1, rating: 1, timestamp: 1 } )
Mais uma vez, o otimizador não vai preferir esse índice, por isso tenho que forçá-lo:
> db.comments.find(
... { timestamp: { $gte: 2, $lte: 4 }, anonymous: false }
... ).sort( { rating: -1 }
... ).hint( { anonymous: 1, rating: 1, timestamp: 1 } ).explain()
{
"cursor" : "BtreeCursor anonymous_1_rating_1_timestamp_1 reverse",
"n" : 2,
"nscannedObjects" : 2,
"nscanned" : 3,
"scanAndOrder" : false,
}
Isso é o melhor que conseguimos. O Mongo segue um plano semelhante ao de antes, caminhando por todo o índice “anonymous, rating, timestamp”, então ele encontra comentários na ordem certa. Mas, agora, nscannedObjects é apenas 2, porque o Mongo pode responder apenas com a entrada de índice que o comentário com um timestamp não é uma correspondência.
Se o meu filtro range no timestamp for seletivo, acrescentar o timestamp ao índice vale a pena; caso contrário, o tamanho adicional do índice não vai valer a pena.
Método final
Então, aqui está o meu método para a criação de um índice composto para uma combinação de testes de igualdade de consulta, campos de classificação, e filtros range:
- Testes de igualdade: Adicionar todos os campos igualdade testados para o índice composto, em qualquer ordem
- Campos de classificação (ascendente/descendente só importam se existirem vários campos de classificação): Adicionar campos de classificação ao índice na mesma ordem e sentido da sua consulta
- Filtros Range: Primeiro, adicione o filtro range ao campo com a menor cardinalidade (menor número de valores distintos na coleção); depois, o próximo filtro range de baixa cardinalidade, e assim por diante, para a maior cardinalidade
Você pode omitir alguns campos de teste de igualdade ou campos de filtro range se eles não forem seletivos, para diminuir o tamanho do índice – um princípio básico é: se o campo não filtra pelo menos 90% dos documentos possíveis em sua coleção, é provável que seja melhor omiti-lo do índice. Lembre-se de que se você possui vários índices em uma coleção, é possível que precise sugerir que o Mongo use o indicador correto.
É isso! Para queries complexas em vários campos, existe um monte de índices possíveis a considerar. Se utilizar este método, você vai estreitar suas escolhas radicalmente e ir direto para um bom índice.
(1) detalhes terríveis: o plano de consulta scanAndOrder “anonymous, timestamp” ganha do plano pré-ordenado “anonymous, rating” porque ele fica até o fim do meu pequeno resultado definido primeiro. Mas se eu tivesse um conjunto maior de resultado, então o plano pré-ordenado poderia ganhar. Primeiro, porque ele retorna dados na ordem correta, de modo que cruza a linha de chegada quando encontra 101 documentos, enquanto um query plan scanAndOrder não é declarado encerrado até que todos os resultados sejam encontrados. Segundo, porque um plano de scanAndOrder sai da corrida se atinge 32 MB de dados, deixando os planos pré-ordenados terminar. Eu disse que esses detalhes seriam horríveis.
***
Texto original disponível em http://emptysquare.net/blog/optimizing-mongodb-compound-indexes/
Matérias especiais e reportagens conduzidas internamente pela Redação iMasters. Acompanhe no Twitter @imasters e no Instagram/Threads @portalimasters



