



Nolock + Page Split
Neste artigo, Reginaldo Silva mostra de forma clara o que é um Page Split e como ele pode prejudicar quando estamos utilizando NOLOCK.


Fala, pessoal!
No último artigo expliquei a base sobre o funcionamento dos principais locks e onde o NOLOCK pode atrapalhar sua vida. Falei também sobre casos de page splits e gostaria de mostrar esses fenômenos acontecendo.
Se ainda não leu o último artigo, acesse:
O que é Page Split?
O SQL Server armazena os dados em páginas de 8 Kb. Imagine que sua página de 8 KB tenha apenas 1 KB livre e a sua próxima gravação de dados necessita de 2 KB.
Logo não caberá tudo na mesma página, então o SQL Server irá alocar uma nova página, copiar metade dos dados para essa nova página e então concluir sua gravação.
As páginas de dados são organizadas pela chave do seu índice, seja ele um cluster ou não cluster. Imagine que sua página de dados está ordenada com valores sequencias, porém, possuí buracos na sequência, conforme o exemplo abaixo – meu índice é no campo ID:
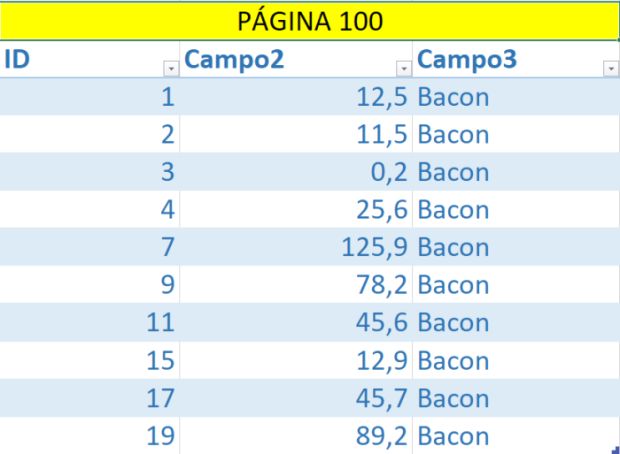
Não entrarei a fundo em índices (logo vem artigos bons sobre isso). O papel do índice é manter seus dados (páginas e registros dentro das páginas) organizados pela chave escolhida.
Levando em consideração que nossa chave é o campo ID, eu preciso inserir um novo registro com ID igual a 5 – ele precisa ser inserido entre os registros ID 4 e 7, certo?
Porém, nesse momento a página de dados está cheia. O que o SQL Server precisa fazer é criar uma nova página, transferir metade dos dados dessa página para a nova, liberando, assim, espaço na página anterior, onde o registro 5 será inserido para manter a sequência.
Todo esse processo é diretamente impactado pela configuração do Fill factor nos seus índices. Em poucas palavras, é a porcentagem que você irá preencher a página de 8 KB com dados, ou seja, se você deixar 100% (default), toda a página será preenchida com dados; se você deixar 95, quer dizer que a página será preenchida 95% com dados e 5 % com espaço livre para futuras inserções\atualizações – isso evitará algumas ocorrências de Page Splits.
Entenda que o inverso disso (fill factor 5) te trará problemas graves. Se você precisar baixar muito o valor do fill factor, você provavelmente tem problemas na sua modelagem, como a escolha de campos ruins para as chaves dos índices.
De forma resumida, Page Split é a divisão de dados entre páginas para manter a ordenação do índice. Tenha em mente que essa página nova tem uma grande chance de estar totalmente afastada da sua sequência física dentro do disco, gerando um overhead grande para suas operações IO, famosa fragmentação física de dados.
Bom, sabemos que o page split gera novas páginas de dados, e aqui entra o NOLOCK. Imagine sua consulta sem nolock rodando no intervalo de uma operação de page split – vamos simular isso logo abaixo:
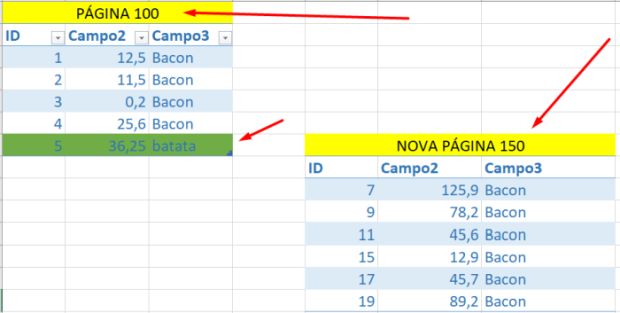
Eis o que acontece durante o evento de page split: seus dados foram separados em páginas diferentes e em locais diferentes – até aí tudo normal.
Mas onde entra o NOLOCK nisso tudo? Sabe o artigo anterior, onde mencionei que, além de não requisitar locks, as transações com NOLOCK também ignoram os locks ativos?
Imagine que sua query já leu a informação da página 100, no entanto, ela foi dividida no meio da sua leitura, e uma nova página (150) com valores já lidos anteriormente foi criada. Sua query lerá essa nova página ainda, fazendo uma leitura duplicada da informação e gerando um valor incorreto.
Sem o NOLOCK isso não ocorreria, pois locks estão protegendo essas páginas e sua query seria bloqueada.
Preparando ambiente:
create table tb_testesplit(
id uniqueidentifier primary key default (NEWID()),
campo2 decimal(18,2) default (RAND() * 100.00),
campo3 char (4000) default ‘bacon’
)
insert into tb_testesplit default values
go 1000
–Tabela para monitorar divergências
create table tb_divergente(campo2 decimal(18,2), dt_log datetime)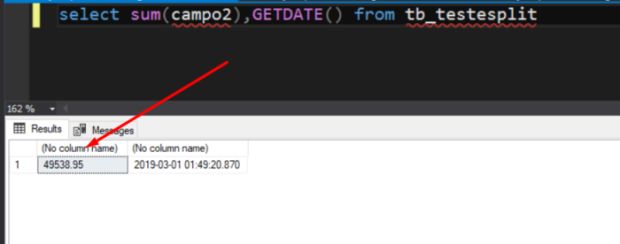
Valor inicial inserido é de 49538,95 para a soma da coluna ‘campo2’; Guarde bem esse valor.
Observação: se você está simulando no seu ambiente, os valores serão diferentes dos apresentados aqui, pois estou utilizando a função RAND() para gerar valores aleatórios, e talvez você precise executar os testes mais de uma vez para simular o mesmo evento apresentado.
Tabela com um índice cluster, porém sua chave não é uma boa escolha, concorda? O tipo Uniqueidentifier receberá valores aleatórios da função NEWID (veja nas referências uma forma de melhorar esse problema).
Sendo assim, para cada registro novo você precisa encaixá-lo na posição correta e ordenada dentro do índice – bem trabalhoso nesse caso.
Irei rodar mais alguns INSERTs, perceba que o ‘campo2’ estou inserindo o valor ‘0’ (zero) mil vezes. Teoricamente, se eu rodar o mesmo SUM em paralelo, o valor não deverá mudar. Vamos lá!
–Sessão nova
insert into tb_testesplit(campo2,campo3) values (0,’açai’)
go 1000
–Outra sessão em paralelo
Insert into tb_divergente
select sum(campo2),GETDATE() from tb_testesplit
go 1000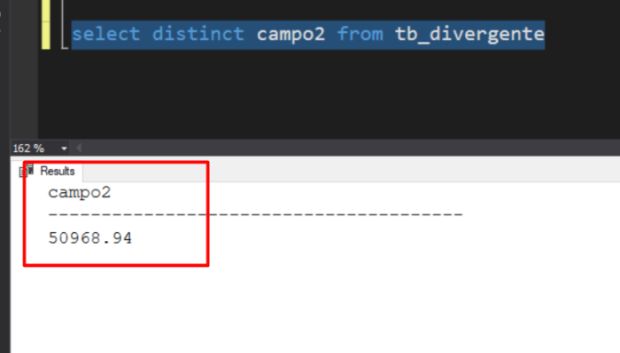
Resultado de acordo com o esperado – não modificamos e nem inserimos nenhum valor novo.
No entanto, achei minha query com SUM um pouco lenta, então aplicarei um tuning com NOLOCK.
–Sessão nova
insert into tb_testesplit(campo2,campo3) values (0,’açai’)
go 1000
–Outra sessão em paralelo
Insert into tb_divergente
select sum(campo2),GETDATE() from tb_testesplit with (nolock)
go 1000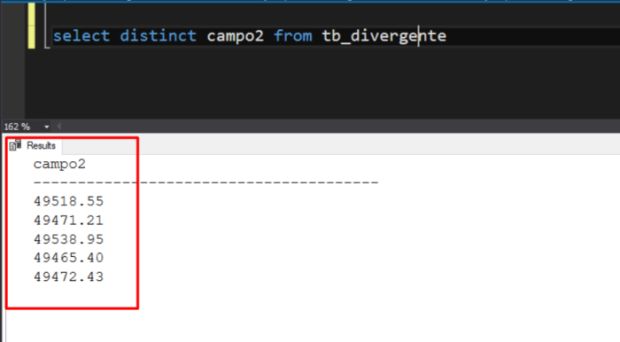
Não inseri nenhum valor a mais, porém, gerou cinco valores diferentes no resultado do SUM. Como explicar isso para quatro usuários que eles deram um pouco de azar?
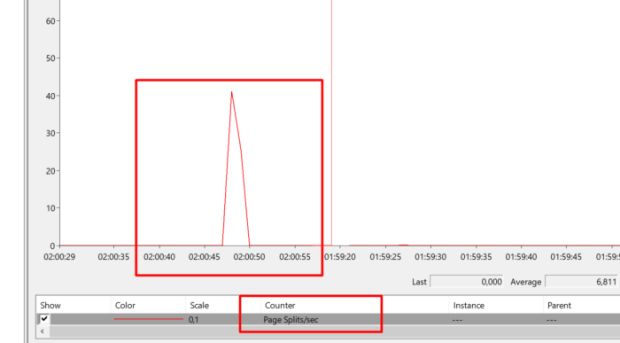
Page split, é você? Bom, o vilão está aí. Com a ajuda do Perfmon identifiquei que estava ocorrendo eventos de Page Split naquele momento. Como mencionei no artigo anterior, casos de ROLLBACK são mais raros, no entanto, casos de page split são comuns no dia a dia.
- Ah, Reginaldo, você fez uma péssima escolha de chave primaria. Não seria esse o problema?
Exato. Foi uma péssima escolha para a chave, então vamos melhorar. Adicionei um campo sequencial, e agora tenho uma chave composta por dois campos, sendo que o ‘campo2’ ainda aceita valores aleatórios.
–Recriando a tabela com novos campos
Drop Table tb_testesplit
go
create table tb_testesplit(
id int identity,
campo2 int default (RAND() * 100000),
campo3 decimal(18,2) default (RAND() * 1000.00),
campo4 char (3800) default ‘bacon’,
primary key (id,campo2)
)
go
— limpando a tabela para monitoramento das divergências
Truncate table tb_divergenteVamos simular os dados.
–Carga inicial da Tabela
insert into tb_testesplit default values
go 1000
— Apagando 10 registros para gerar um buraco na nossa sequência.
delete tb_testesplit where id < 10
–Valor inicial sem NOLOCK
select sum(campo3) from tb_testesplit
— 498330.84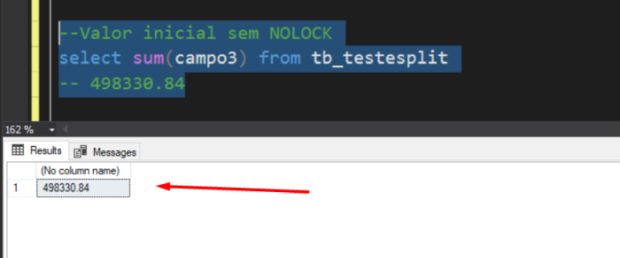
Valor total sem NOLOCK é de 498330,84.
–Habilitando insert em em colunas com Identity
set identity_insert tb_testesplit on
–Loop para gerar Inserts com range de 0 a 100
DECLARE @ID INT = 0
WHILE @ID < 100
BEGIN
insert into tb_testesplit(id,campo3,campo4) values (@ID,0,’açai’)
WAITFOR DELAY ’00:00:00.100′
set @ID = @ID + 1
ENDNovamente, inserindo o valor 0 para o campo3, ou seja, não deverá afetar o resultado do SUM. Em paralelo rodarei um SUM com NOLOCK:
–Sessão em paralelo ao Loop
Insert into tb_divergente
select sum(campo3),GETDATE() from tb_testesplit with (nolock)
go 5000
–Conferindo se houveram divergências
select distinct campo2 from tb_divergente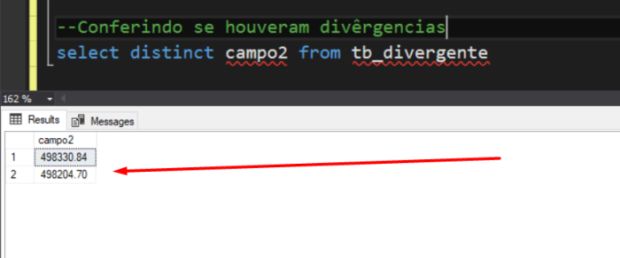
Para nossa surpresa, ainda continua ocorrendo alguns eventos de Page Split, apesar da ocorrência ser menor. Devido a nossa chave ser sequencial, ainda ocorreram divergências de valores.
Neste caso, foi devido ao reuso dos valores do campo ID que foram apagados ou pulados. Para esse caso tive que realizar várias vezes o mesmo teste.
Até ocorrer o evento de leitura duplicada, a ocorrência de page split melhorou bastante em relação ao primeiro exemplo, no entanto, o risco ainda existe e você estará contando com a sorte.
Para diminuir a possibilidade desses eventos, você pode, primeiramente, escolher uma boa chave para o seu índice. Considere sempre utilizar um valor sequencial como uma coluna Identity e alterar o parâmetro fill factor para um valor menor que 100 – isso irá minimizar a ocorrência de Page Split
Porém, tome cuidado para não baixar muito esse valor, pois isso pode gerar outros problemas, como inflar muito o seu banco de dados com espaço em branco, gerando um desperdício de disco, processamento e memória RAM.
Monitore a ocorrência de page split e diminua o valor gradativamente – não altere, de início, para um valor 70, por exemplo – isso pode até resolver seu problema de page split, porém talvez 95 já seria um valor suficiente e você estará desperdiçando 25% a mais do que o necessário.
Bom, é isso aí, pessoal! Neste artigo mostrei de forma mais clara o que é um page split e como ele pode te prejudicar quando você está utilizando NOLOCK.
Mais uma vez, revise seus códigos com NOLOCK e valide a necessidade dele. Abraços!
Referências
Co-Chapter Leader do local group SQL Vale, MTAC - Multi-Platform Audience Contributor, palestrante em eventos pelo Brasil como SQL Saturday, Zero to Hero, TDC e Azure Bootcamp, possuí certificações Microsoft MCP, MCSA e MCSE. Atualmente possuí o cargo de Sênior Data Platform Consultant na Dataside, atuando em projetos de missão crítica com as principais tecnologias de alta disponibilidade e recuperação de desastre, performance tuning e Power BI. Entusiasta de tecnologia, tem como foco principal SQL Server, MongoDB, Cassandra, PowerBI e C# em sua carreira de atuação.



