



Realizando o processo de análise de sentimento do Twitter em Go
Neste artigo, iremos tratar de algo muito interessante que é analisar o live stream data do Twitter.

Go é uma linguagem que se adequa muito bem as necessidades de backend, tais como processamento concorrente, tarefas agendadas, processamento de arquivos, análise de dados e muito mais.
Neste artigo, iremos tratar de algo muito interessante que é analisar o live stream data do Twitter.
Nosso objetivo é descobrir qual sentimento, positivo ou negativo, que um tweet representa. Para isso, nossa implementação deve ser capaz de classificar automaticamente um tweet com um sentimento positivo ou negativo, de acordo com os termos contidos nele. Desta forma, o nosso classificador precisa ser treinado para tal missão.
Vamos, então, montar uma lista de tweets manualmente classificados por nós.
Vamos começar com 5 tweets positivos e 5 tweets negativos:
Tweets positivos:
- I love this car.
- This view is amazing.
- I feel great this morning.
- I am so excited about the concert.
- He is my best friend.
Tweets negativos:
- I do not like this car.
- I crash my car.
- I feel tired this morning.
- I am not looking forward to the concert.
- He is my enemy.
Em uma implementação mais completa, deve ser utilizado um número bem maior de tweets para treinar o classificador. Quanto mais bem treinado, melhor é o resultado apresentado.
Então, mãos a obra…
Este será nosso JSON contendo nossa base de treinamento:
twittersentimentclassifier.json
[
{
"Tweet": "I love this car",
"Classifier": "positive"
},
{
"Tweet": "This view is amazing",
"Classifier": "positive"
},
{
"Tweet": "I feel great this morning",
"Classifier": "positive"
},
{
"Tweet": "I am so excited about the concert",
"Classifier": "positive"
},
{
"Tweet": "He is my best friend",
"Classifier": "positive"
},
{
"Tweet": "I do not like this car",
"Classifier": "negative"
},
{
"Tweet": "I crash my car",
"Classifier": "negative"
},
{
"Tweet": "I feel tired this morning",
"Classifier": "negative"
},
{
"Tweet": "I am not looking forward to the concert",
"Classifier": "negative"
},
{
"Tweet": "He is my enemy",
"Classifier": "negative"
}
]
Para armazenar este JSON, precisamos da seguinte struct:
//TwitterSentimentClassifier : Tweets para treinar o classificador.
type TwitterSentimentClassifier struct {
Tweet string
Classifier string
}
E para realizar a leitura do arquivo JSON, teremos a seguinte rotina:
func getTwitterSentimentClassifier(file string) []TwitterSentimentClassifier {
//Realiza a leitura do arquivo json
raw, err := ioutil.ReadFile(file)
//Tratamento de erros padrão.
if err != nil {
fmt.Println(err.Error())
os.Exit(1)
}
var twitterSentimentClassifier []TwitterSentimentClassifier
//Unmarshal do conteúdo do arquivo json para um tipo struct TwitterSentimentClassifier
json.Unmarshal(raw, &twitterSentimentClassifier)
return twitterSentimentClassifier
}
Devemos ter a seguinte leitura do arquivo JSON:
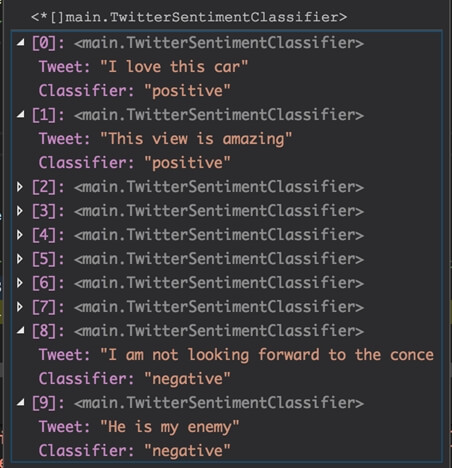
Agora que temos nossa lista, iremos transformá-la em tuplas contendo dois elementos. O primeiro elemento é um array contendo os termos de cada tweet e segundo elemento é o tipo classificação, ou seja, nossa classificação positiva e negativa.
Para isso precisaremos destas duas struct:
//TermClassified : Termos classificados.
type TermClassified struct {
Term string
FreqDist int
}
//TermClassifier : Classificador dos Termos dos tweets para treinar o classificador
type TermClassifier struct {
Term []string
Classifier string
}
Vamos criar agora nossa rotina responsável por transformar os tweets em nossa lista de termos classificados:
func getTermClassifier(twitterSentimentClassifier []TwitterSentimentClassifier) (int, []TermClassifier) {
termClassifier := make([]TermClassifier, len(twitterSentimentClassifier))
var generalCount int
for i, item := range twitterSentimentClassifier {
//Primeiro vamos fazer através da função Fields o split da sentença por espaços
tweet := strings.Fields(item.Tweet)
//Criamos um slice do tipo Term do tamanho máximo dos splits do nosso tweet.
term2Classifier := make([]string, len(tweet))
var count int
for j, termTweet := range tweet {
//Estamos considerando apenas palavras maiores que três caracteres para serem consideradas como termos válidos
//Utilizamos rune para prevenir caracteres especiais, acentos, caracteres asiáticos e também emogis
if len([]rune(termTweet)) >= 3 {
term2Classifier[j] = strings.ToLower(termTweet)
count++
}
}
termClassifier[i].Term = make([]string, count)
count = 0
for k, termTweetClassifier := range term2Classifier {
//Realizamos um ajuste do tamanho da slice final de termos
if term2Classifier[k] != "" {
termClassifier[i].Term[count] = termTweetClassifier
count++
generalCount++
}
}
termClassifier[i].Classifier = item.Classifier
}
return generalCount, termClassifier
}
O resultado deverá ser este:
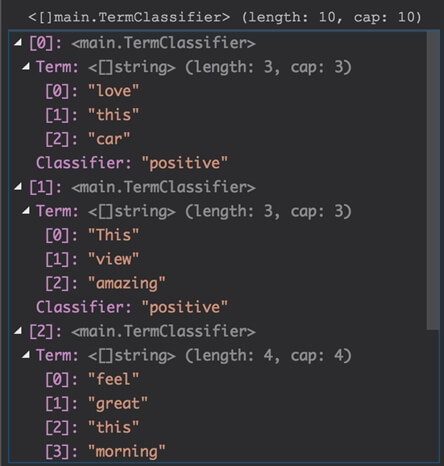
Agora iremos verificar quantas vezes cada termo aparece em nossos tweets de treinamento, ou seja, frequência de distribuição ou simplesmente score.
Vamos convencionar que os termos encontrados em tweets que classificamos com o sentimento positivo recebem + 1 e que os termos encontrados em tweets que classificamos com o sentimento negativo recebem -1.
func afterClassifier(generalCount int, termClassifier []TermClassifier) []TermClassified {
//Esta slice receberá todos os termos identificados na slice anterior
termClassified := make([]TermClassified, generalCount)
var count int
var countTermAfterClassifier int
for _, item := range termClassifier {
for _, itemTerm := range item.Term {
//Antes de aplicar o score em um termo verificamos se ele já não fora identificado anteriormente.
//Caso este termo já tenha sido identificado apenas contabilizamos a frequência de distribuição (score)
var found bool
for _, itemTermForCompareBeforeInsert := range termClassified {
if itemTermForCompareBeforeInsert.Term == itemTerm {
found = true
break
}
}
if !found {
termClassified[count].Term = itemTerm
countTermAfterClassifier++
//Agora iremos aplicar a frequência de distribuição (score) de cada termo em relação ao sentimento que demos em cada um dos tweets
for _, itemForCompare := range termClassifier {
for _, itemTermToCompare := range itemForCompare.Term {
if itemTerm == itemTermToCompare {
if itemForCompare.Classifier == "positive" {
termClassified[count].FreqDist = termClassified[count].FreqDist + 1
} else if itemForCompare.Classifier == "negative" {
termClassified[count].FreqDist = termClassified[count].FreqDist - 1
}
}
}
}
}
count++
}
}
// Removendo registros vazios
termAfterClassifierClassified := make([]TermClassified, countTermAfterClassifier)
var countAfterClassifierClassified int
for _, itemTermClassified := range termClassified {
if itemTermClassified.Term != "" {
termAfterClassifierClassified[countAfterClassifierClassified] = itemTermClassified
countAfterClassifierClassified++
}
}
return termAfterClassifierClassified
}
O resultado deve ser este:
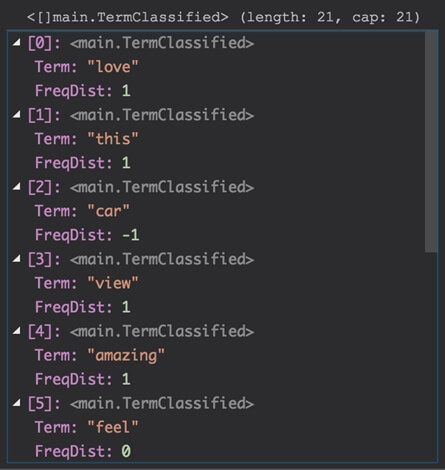
Como exemplo, percebam que o termo “car” está com score -1, pois aparece em um tweet que classificamos como sendo positivo e em dois tweets que classificamos como sendo negativo, logo (+1)(-1)(-1) = -1
Lista completa:
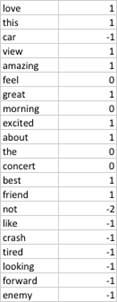
Nosso próximo passo será criarmos uma lista JSON com tweets livres de classificação e submetê-los a uma classificação de termos onde nosso classificador irá determinar o sentimento de cada tweet com base no score de seus termos.
Para facilitar nossa experiência, iremos utilizar a mesma listagem de tweets que utilizamos para balizar o classificador; apenas criaremos um novo arquivo JSON e remover a classificação “positive” e “negative”. Veja o exemplo:
twitter.json
{
"Tweet": "I love this car",
"Classifier": ""
},
{
"Tweet": "This view is amazing",
"Classifier": ""
}, …
Iremos reaproveitar os mesmos métodos que utilizamos até agora para trabalhar com os tweets.
getTermClassifier(getTwitterSentimentClassifier("./twitter.json"))
Devemos ter um resultado assim:
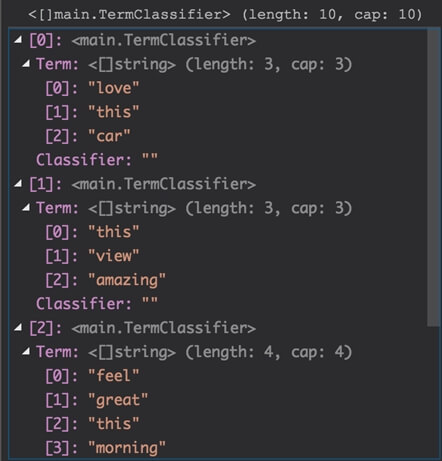
Notem que a classificação de todos os tweets estão vazias.
Nosso classificador deverá, então, analisar cada tweet e baseado no score de cada termo e classificar este tweet como sendo positivo ou negativo.
func main() {
lst1 := afterClassifier(getTermClassifier(getTwitterSentimentClassifier("./twittersentimentclassifier.json")))
_, lst2 := getTermClassifier(getTwitterSentimentClassifier("./twitter.json"))
for i, item := range lst2 {
var count = 0
for _, itemTerm := range item.Term {
for _, itemClassifier := range lst1 {
if itemTerm == itemClassifier.Term {
//Aqui definimos qual frequência de distribuição (score) será considerado como um sentimento positivo ou negativo
if itemClassifier.FreqDist >= 0 {
count++
} else {
count--
}
}
}
}
if count >= 0 {
lst2[i].Classifier = "positive"
} else {
lst2[i].Classifier = "negative"
}
}
_, originalTweetList := getTermClassifier(getTwitterSentimentClassifier("./twittersentimentclassifier.json"))
outLine("Tweets originais:", originalTweetList)
outLine("Tweets reclassificados:", lst2)
}
E o resultado da classificação dos tweets gerada pelo nosso classificador será este:
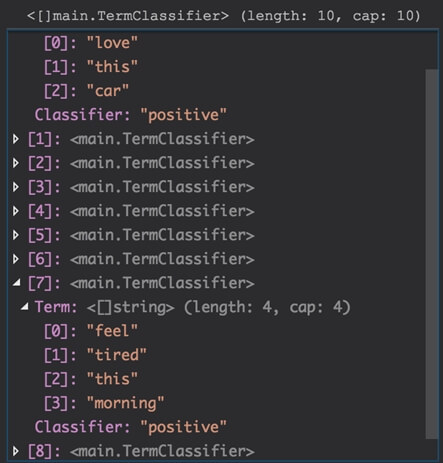
Notem que mesmo utilizando exatamente a mesma lista, algumas classificações se mantiveram, enquanto outras ganharam outro valor com base no que nosso classificador aprendeu em seu treinamento.
Tweets originais:
- love this car – positive
- this view amazing – positive
- feel great this morning – positive
- excited about the concert – positive
- best friend – positive
- not like this car – negative
- crash car – negative
- feel tired this morning – negative
- not looking forward the concert – negative
- enemy – negative
Tweets reclassificados:
- love this car – positive
- this view amazing – positive
- feel great this morning – positive
- excited about the concert – positive
- best friend – positive
- not like this car – negative
- crash car – negative
- feel tired this morning – positive
- not looking forward the concert – negative
- enemy – negative
Onde nossa divergência apresenta os seguintes scores em cada termo:
![]()
Logo, o nosso classificador atribuiu score 0 para este tweet e, pela nossa regra, score 0 é igual a sentimento positivo.
PLUS…
Agora, vamos trabalhar com tweets reais!
Primeiro, vamos criar um serviço de streaming do Twitter e depois deixar nosso classificador trabalhar em cima de dados reais…
Para criar ID, chaves e token do aplicativo Twiiter:
- Entre no aplicativo do Twitter e clique no link Sign in ou Sign up now se você não tem uma conta do Twitter;
- Clique em Criar Novo Aplicativo;
- Insira um Nome, Descrição e Site. O nome do aplicativo Twitter deve ser um nome exclusivo. O campo site da Web na verdade não é usado. Ele não precisa ser uma URL válida;
- Marque sim, eu li e concordo com o Developer Agreement. Em seguida, clique em Criar seu aplicativo do Twitter;
- Clique na guia Permissões. A permissão padrão é somente leitura. Isso é suficiente para este artigo;
- Clique na guia Chaves e Tokens de acesso;
- Clique em Criar meu token de acesso;
- Copie os valores-chave do consumidor, segredo do consumidor, token de acesso e segredo do token de acesso.
Agora que já temos as chaves necessárias, iremos utilizar uma biblioteca chamada anaconda “https://github.com/ChimeraCoder/anaconda”. Anaconda é uma biblioteca cliente para a API 1.1 do Twitter.
Para tal, iremos adicionar os seguintes pacotes ao nosso programa:
import ( "encoding/json" "fmt" "io/ioutil" "os" "strings" "anaconda" "net/url" )
Lembrem-se de clonar a biblioteca “git clone https://github.com/ChimeraCoder/anaconda.git” para o src do seu %GOPATH% e depois disso dê o comando “go get” dentro da sua clonagem para poder seguir com o consumo desta biblioteca.
![]()
Com os pacotes adicionados, vamos criar a seguinte função:
func twitterStreamingAPI() []TwitterSentimentClassifier {
//Mais sobre: https://github.com/ChimeraCoder/anaconda
anaconda.SetConsumerKey("xxx") //Consumer Key
anaconda.SetConsumerSecret("xxx") //Consumer Secret
client := anaconda.NewTwitterApi("xxx", "xxx") //Access Token, Access Token Secret
// setando os parametros utilizando url.Values
v := url.Values{}
v.Set("count", "30") // ou v.Set("locations", "<Locations>")
result, err := client.GetSearch("golang", nil)//buscar por tweets que contenham o termo “golang”
if err != nil {
fmt.Println(err.Error())
os.Exit(1)
}
// Ao menos que exista algo estranho, devemos ter ao menos 2 tweets
if len(result.Statuses) < 2 {
fmt.Printf("Esperado 2 ou mais tweets, foram encontrados %d", len(result.Statuses))
os.Exit(1)
}
twitterSentimentClassifier := make([]TwitterSentimentClassifier, len(result.Statuses))
// verificar a existência de tweet vazio
for i, tweet := range result.Statuses {
twitterSentimentClassifier[i].Tweet = tweet.Text
}
return twitterSentimentClassifier
}
E para finalizar, vamos simplesmente enviar para a rotina getTermClassifier os tweets que coletamos da stream.
_, lst2 := getTermClassifier(twitterStreamingAPI())
Sem mudanças adicionais no processamento que criamos teremos classificações reais como estas:
@turnoff_us: the depressed developer #comic #golang #depresseddeveloper @golang https://t.co/7rwtf3ylus https://t.co/1ppyi5fzol - positive @turnoff_us: the depressed developer #comic #golang #depresseddeveloper @golang https://t.co/7rwtf3ylus https://t.co/1ppyi5fzol - positive @andychilton: true. said this *so* *many* *times* about #nodejs, specifically express. was one reason broke. still happy swi… - positive @srcgraph: new "used by" badges from @srcgraph you can see how many people use your @golang library https://t.co/kvgi4pynej - positive @turnoff_us: the depressed developer #comic #golang #depresseddeveloper @golang https://t.co/7rwtf3ylus https://t.co/1ppyi5fzol - positive
Legal, né?
Então, a ideia aqui foi mostrar que com as funções básicas de Go e de maneira bastante simples, podemos construir coisas incríveis.
Também deve ter ficado claro que quanto maior a nossa base de dados utilizada no treinamento, melhor será a analise feita pelo nosso classificador.
Certamente podemos ter inúmeras melhorias neste código, tal como o uso de goroutines, e com base nas classificações, identificar o sentimento sobre o termo de pesquisa, evolução nos ranges de classificação, melhorias nas iterações etc… Mas isso é com vocês!
Conclusão: Go é muito divertido!
Obs.: Git: https://github.com/edwardmartinsjr/iMasters-Go/tree/master/twittersentiment
É desenvolvedor C# por experiência e Gopher por entusiasmo. Bacharel em Ciência da Computação gosta de passar horas como piloto virtual. No dia-a-dia trabalha como tech lead dedicado as questões de backend e mobile.



