


Neste artigo, apresento algumas análises dos textos dos discursos depois de algumas semanas da histórica votação do impeachment da presidente na câmara dos deputados. Diferente da maioria das análises apresentadas pela imprensa, aqui vou fugir dos gráficos tradicionais e mostrar algo um pouco mais avançado, incluindo ferramentas não muito conhecidas.
Antes de começar, gostaria de indicar alguns trabalhos que já foram feitos com os dados dos discursos. Atualmente, a imprensa brasileira está produzindo gráficos, análises, infográficos e visualizações interativas interessantes, porém ainda muito básicas. Esse é o caso dos gráficos e informações apresentadas por vários veículos de mídia e pessoas que se interessaram pelos dados, como este e este.
Eu gosto muito de ver essas iniciativas, porém em praticamente todos os casos não há emprego de técnicas mais avançadas, tais como o uso de algoritmos de mineração de dados. Portanto, neste artigo vou comentar algumas análises que eu fiz com algumas ferramentas e técnicas pouco conhecidas por jornalistas e outros entusiastas da análise de dados. Vou enumerar as análises, destacando algumas descobertas relevantes. Todos os scripts, dados e demais recursos são disponibilizados neste repositório do GitHub.
Destaco que essas análises têm o objetivo de mostrar alguns técnicas e recursos pouco conhecidos e que elas são básicas. Isso quer dizer que é possível se aprofundar ainda mais e explorar outras maneiras para descobrir novos padrões ‘escondidos’ nos dados.
1) Tratamento de dados
Em primeiro lugar, gostaria de agradecer à Patricia Cornils, que fez o trabalho de organizar os dados gerados pelos profissionais da câmara que utilizaram a técnica de taquigrafia. Descobri esses dados em um post do Facebook e indico que eles foram colocados em uma planilha disponível aqui.
A propósito, quando comecei a fazer a importação de dados, notei alguns problemas com os quais tive que lidar. Pela técnica de coleta de dados utilizada (taquigrafia), ocorreram alguns problemas no texto, tal como a junção de palavras e uso de parênteses para indicar eventos. Por exemplo, em alguns casos, o verbo “é” ficou junto com a palavra “não” formando um “énão” que teve que ser separado. Já o uso do parênteses levou a casos como “(pausa)”, que tiverem que ser eliminados. Também tive que lidar com caracteres especiais (! , . ? char(9)) em algumas partes do texto.
Eu utilizei um script SQL executado no SQL Server para fazer a importação com o comando BULK INSERT. As demais manipulações foram feitas com a linguagem SQL, uma vez que ela é linguagem mais utilizada para manipular dados e que me faz ser muito produtivo.
Para finalizar a limpeza, eu fiz a remoção de algumas “stop words” e dígitos numéricos do texto do discurso. A lista das palavras que removi foi:
- ‘a,as,às,ao,ai,com,como,da,de,do,dos,e,em,esse,esta,isso,ja,mais,mas,minha,o,O
- ,à,é,os,ou,para,por,Por,Pelo,Pelos,pelo,pela,pouca,pouco,pra,que,um,uma,ha,pois,vou,ta
- ,com,na,no,nas,nos,há,Lá,se,já,foi,sem,com,dar,me,só,meu,vai,tem,tal,meus,aos,sou,ser,seus
- ,está,são,sou,porque,ser,deste,pelas,nem,seu,seus,tão,muito,muita,muitos,muitas,vez,cada,dessa
- ,desse,dessas,destes,deste,estar,têm,quer,quero,querer,faz,era,aí,aquela,aquilo,vi,tinha
- ,qual,eu,sr,aqui,nosso,nós’
No total, acabei com 16.036 palavras utilizadas em 511 discursos. Destas, apenas 3.443 foram palavras únicas.
2) Análise LCS
O algoritmo LCS (Longest Common Subsequence) indica qual é a sequência de caracteres mais comum entre dois conjuntos de caracteres (strings). No caso dos discursos, a sequência mais comum foi “vot”, pois a palavra “voto” apareceu em praticamente todos os discursos. Nada muito interessante aqui, mas eu também fiz uma análises LCS considerando cada palavra como um elemento do string. Dessa vez, o algoritmo LCS retornou a palavra “voto”.
É interessante destacar que o LCS não gerou algo interessante porque as falas foram bem diferentes, pelo menos do ponto de vista da ordem e da variedades das palavras. Esse resultado já era meio que esperado, pois estudos da análise de discurso indicam que raramente vai haver muita semelhança na ordem de uso das palavras quando há um conjunto grande de discursos. Contudo, essa análise foi interessante e justificou outras técnicas para enxergar melhor a distribuição das palavras.
Eu realizei a análise LCS utilizando este script em Python, que pode ser executado diretamente no navegador pela plataforma Repl.it.
3) Regras de associação
O uso de regras de associação é comum em sites de e-commerce e outros, pois elas permitem identificar que tipo de item é “comprado” em conjunto com outro a partir de certos parâmetros. Em geral, utilizam-se os parâmetros suporte (a frequência em que a palavra acontece) e confiança (o quão forte é a associação entre as palavras).
Para esta análise de regras de associação entre as palavras, eu utilizei o ótimo framework em Java chamado SPMF, que já expliquei como utilizá-lo em uma Pocket Video. Como algoritmo, eu rodei o FPGrowth_association_rules, e as regras mais interessantes foram obtidas com 60% mínimo para o suporte e para a confiança. Sem muita surpresa, encontrei a regra indicando a associação recíproca entre as palavras SIM ==> VOTO. Baixando o suporte mínimo para 50%, temos a associação recíproca PRESIDENTE ==> SIM.
Dado a característica dos discursos (muitas palavras com ordem variada), é de se esperar que as principais palavras utilizadas estejam presentes nas regras de associação. De fato, as top 10 palavras mais empregadas por quem votou a favor do impeachment foram: BRASIL ESTADO FAMÍLIA NÃO NOME PAÍS POVO PRESIDENTE SIM VOTO.
Já as top 10 palavras mais empregadas por quem votou contra o impeachment foram: BRASIL CONTRA DEFESA DEMOCRACIA DILMA GOLPE NÃO POVO PRESIDENTE VOTO
Pode-se notar que existem algumas diferenças entre as listas, como as palavras CONTRA e PAÍS, mas em geral não houve regras de associação diferentes com base no tipo de voto.
4) Associação visual de palavras
A próxima etapa da análise foi estudar visualmente algumas associações de palavras. Existem várias ferramentas para fazer isso, mas aqui eu optei por uma que é pouco conhecida: o JigSaw. Uma vez que dados estejam de acordo com o formato que ela requer, é possível fazer várias explorações visuais. Por exemplo, eu montei uma análise considerando algumas palavras que iniciam as frases, como pode ser visto pela figuras abaixo (clique sobre elas para aumentar).

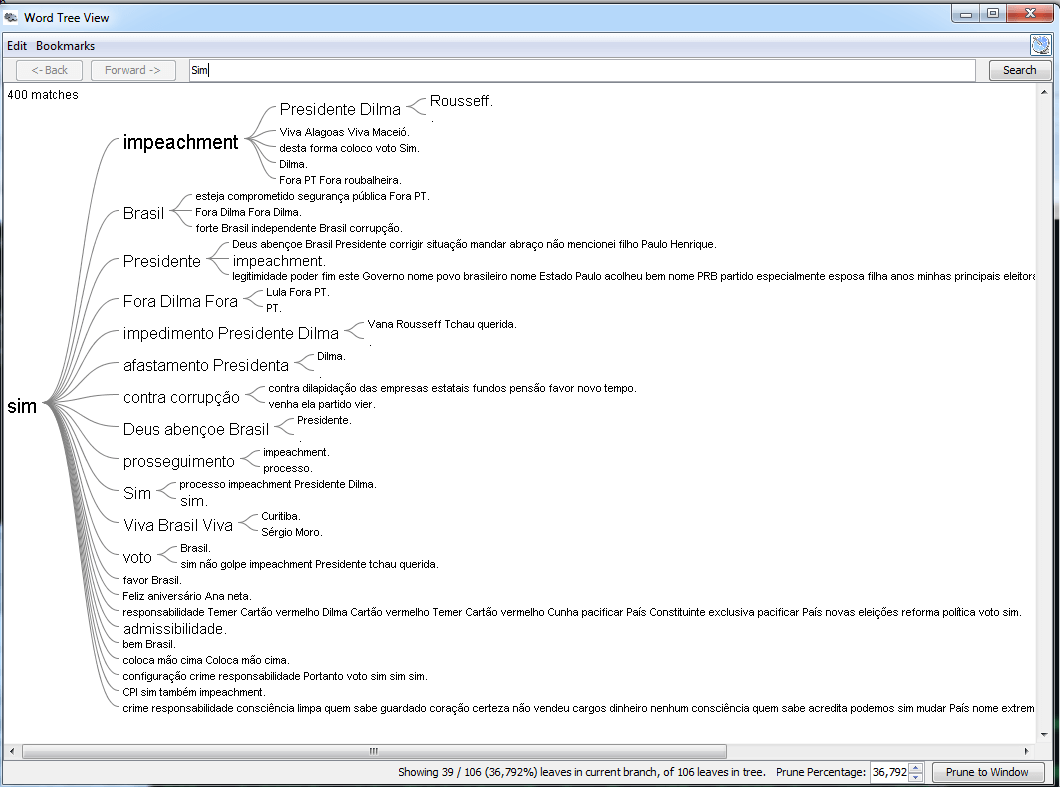
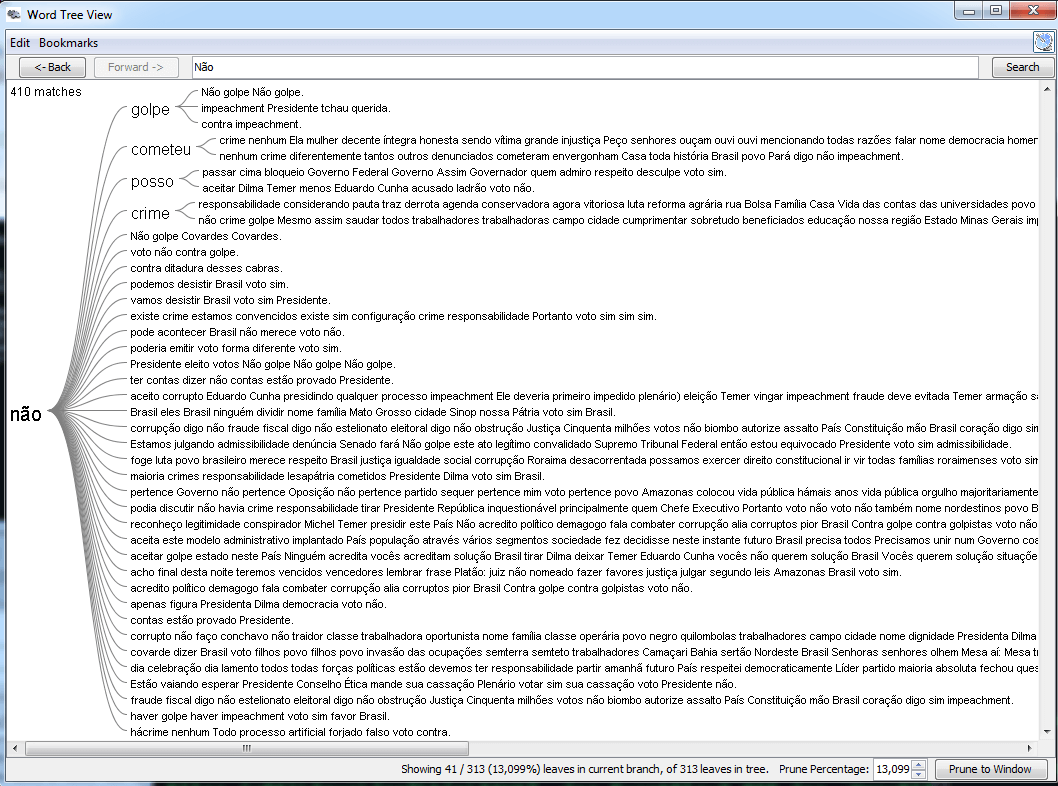
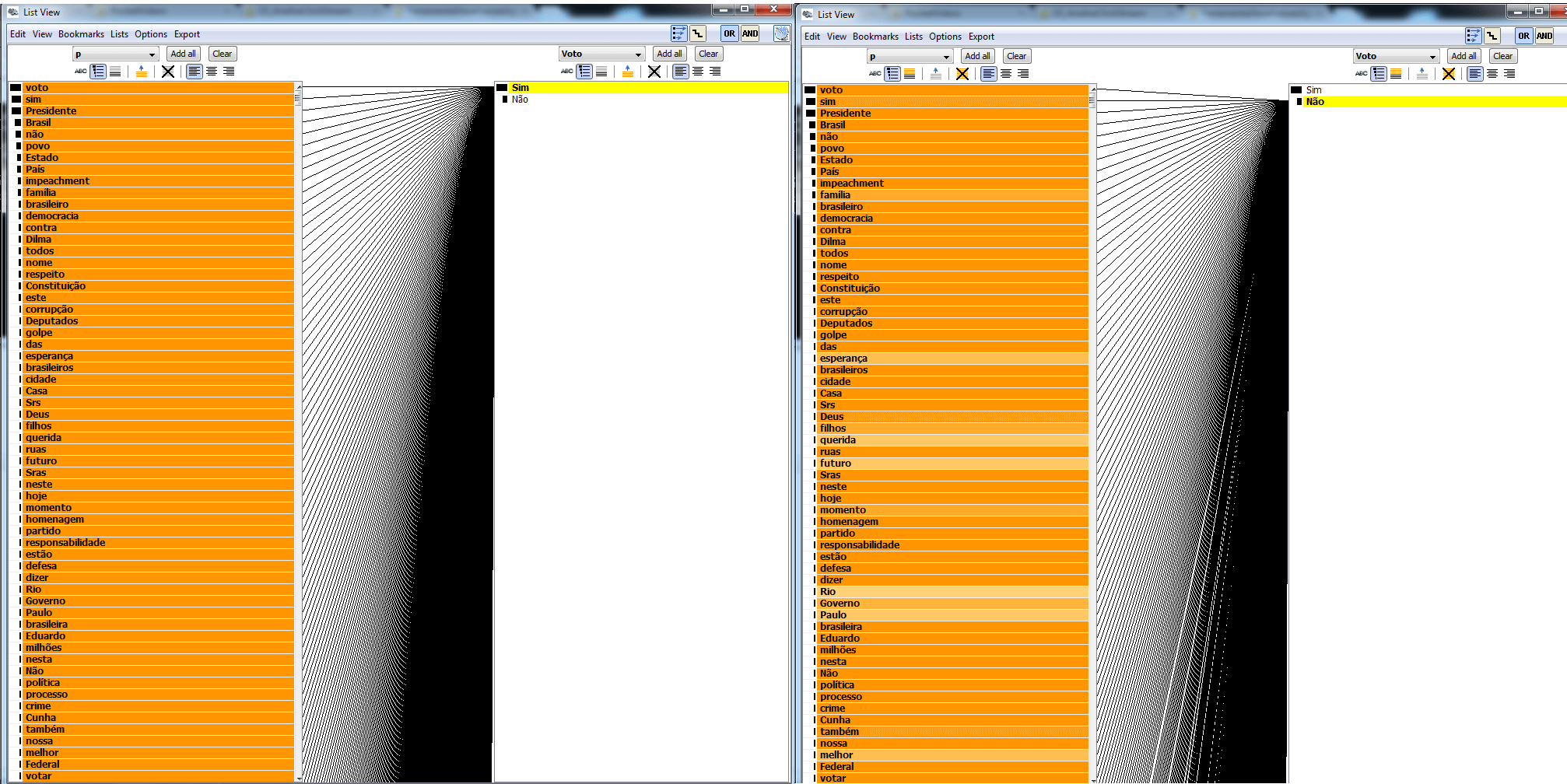
A ferramenta JigSaw também permite observar associações de palavras por meio das conexões dos elementos de duas listas verticais colocadas lado a lado. Por exemplo, podemos explorar de forma interativa os dados e observar facilmente as palavras utilizadas por cada deputado, como mostrado nos dois exemplos abaixo.
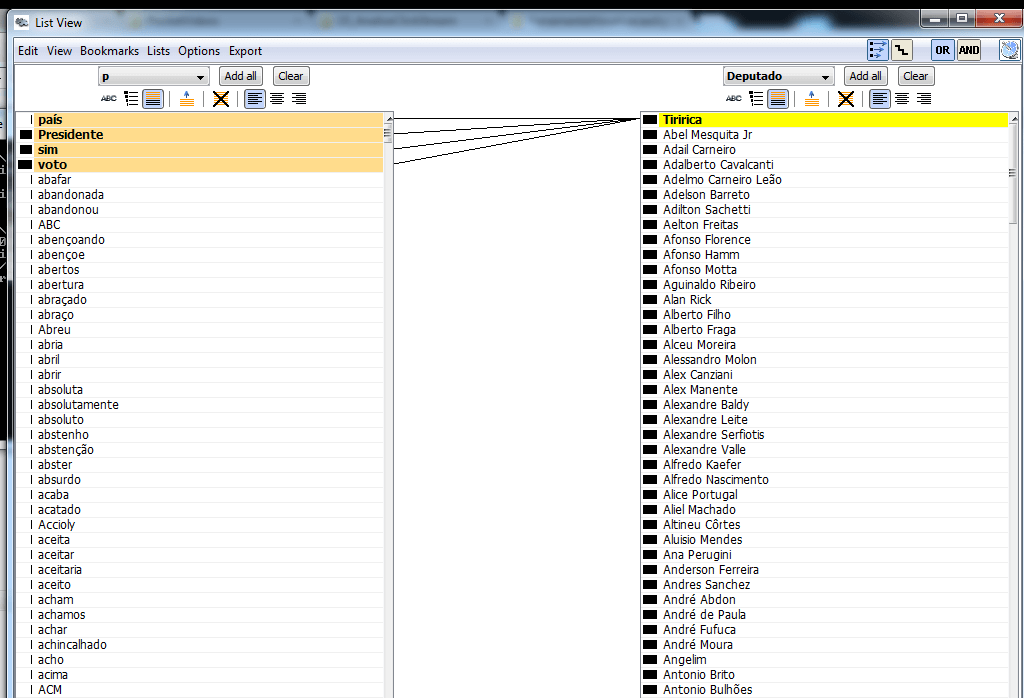
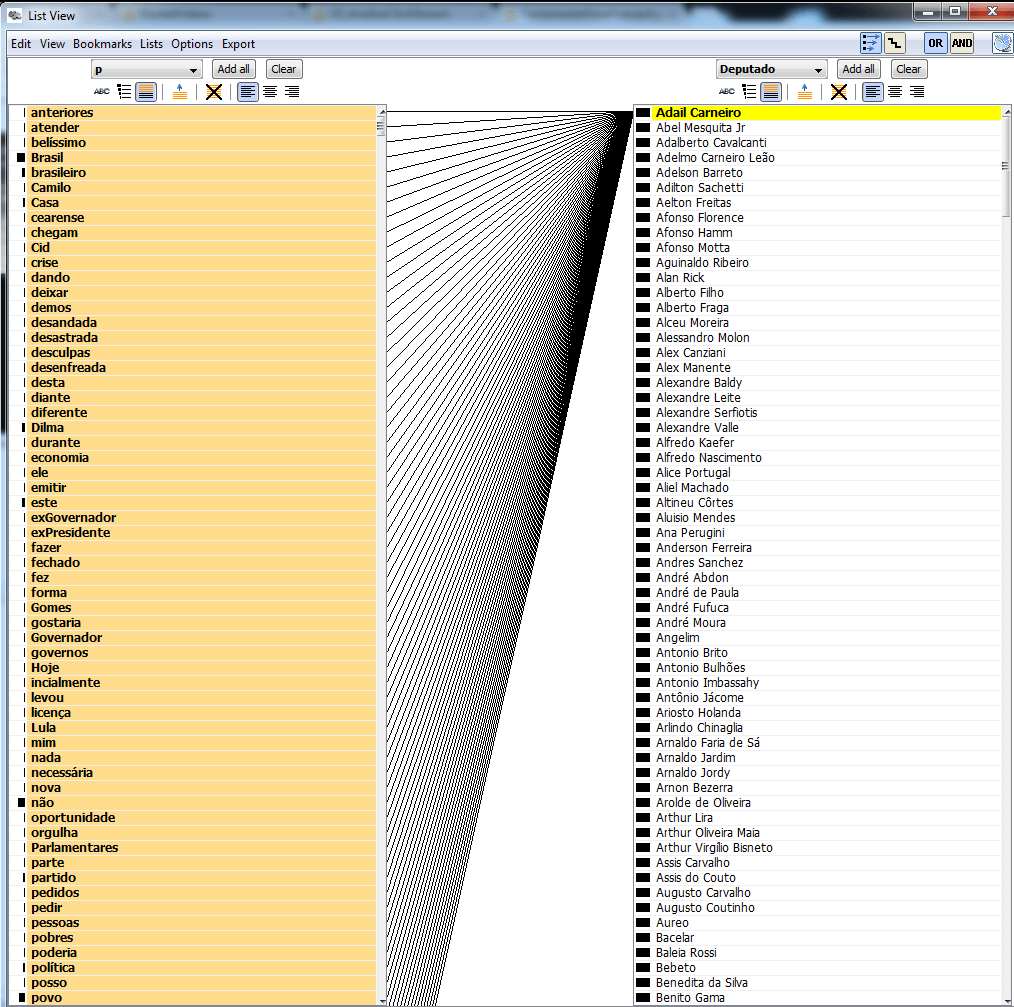
A associação de palavras pelo tipo de voto (sim – a favor; não – contra) mostra que algumas palavras foram utilizadas com menos frequência por cada grupo. Por exemplo, as palavras ESPERANÇA e FAMÍLIA não foram ditas tantas vezes pelo grupo do não quanto pelo grupo do sim.
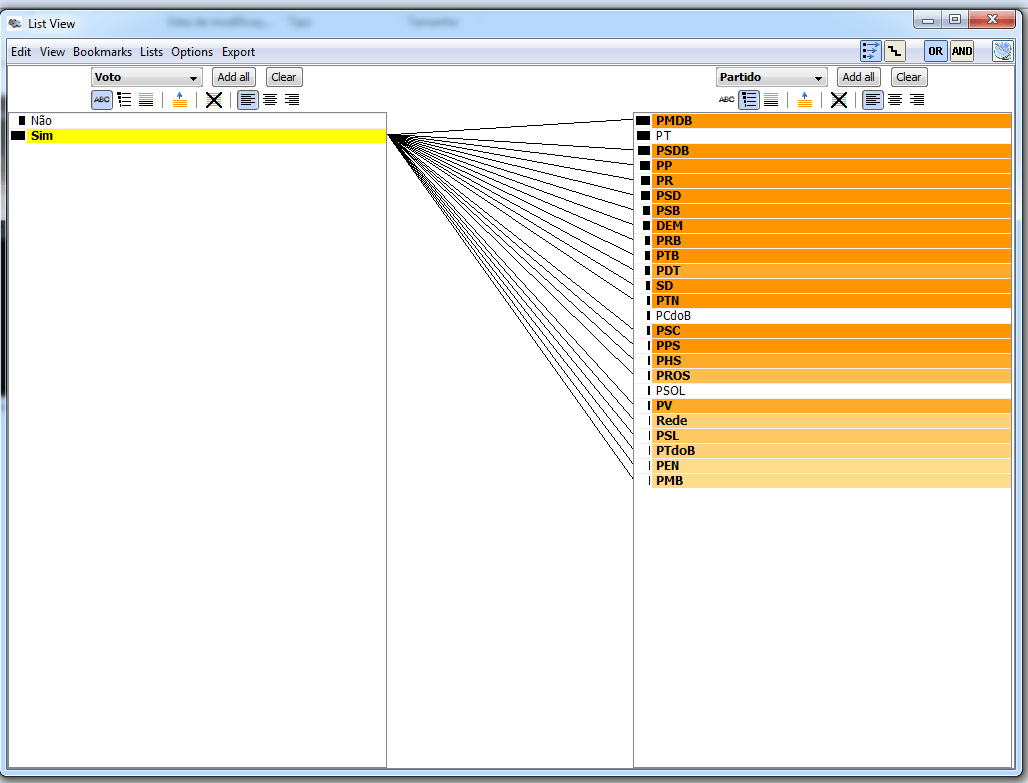
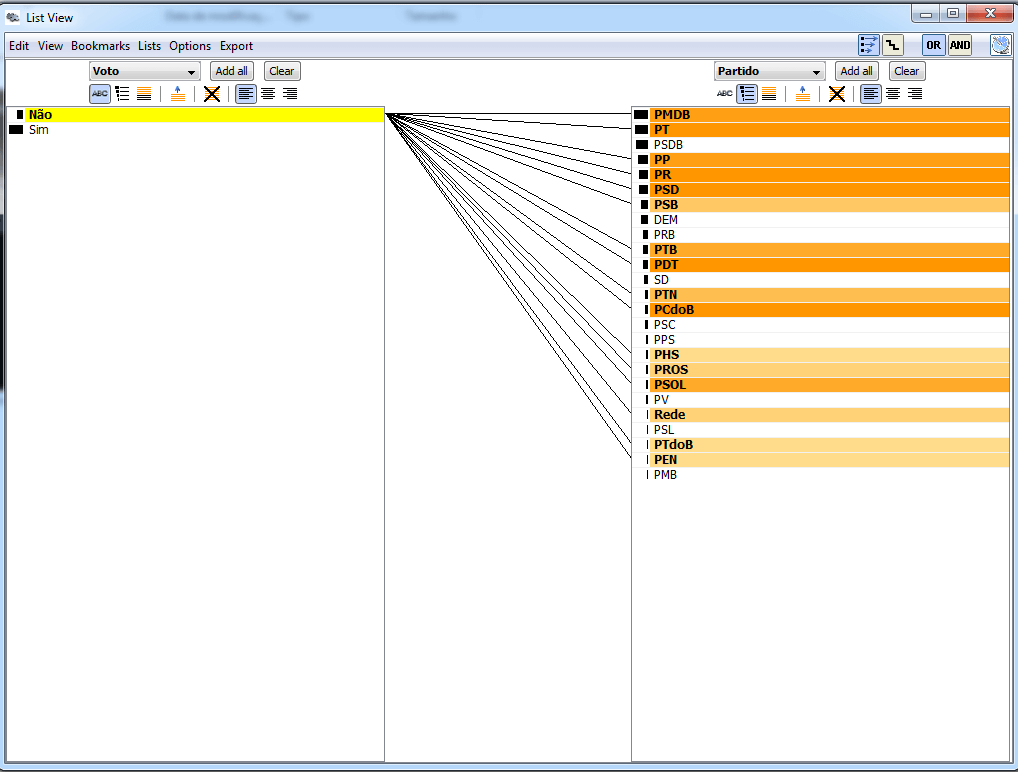
Com essas listas ligadas, também é possível relacionar outros atributos, como o voto (sim – a favor; não – contra) junto com a frequência (tonalidade da cor) de acordo com cada partido. Essas duas análises são mostradas nas figuras abaixo:
5) Semelhança de discursos
A maioria dos discursos realizados empregou muitas palavras diferentes, porém alguns deles foram parecidos. Para analisar o quão semelhantes foram os discursos, resolvi utilizar uma comparação baseada em Fuzzy Matching, ou seja, analisar as diferenças no nível de caractere. Eu utilizei como medida de distância o algoritmo Jaro-Winkler comparando cada discurso por meio do pacote jellyfish do Python. Eu poderia ter utilizado uma comparação mais complexa (usar o Tf-idf, por exemplo), mas resolvi simplificar só para ver o que poderia ser obtido.
A primeira descoberta foi que menos de 20 deputados utilizaram frases mínimas do tipo “Presidente voto sim” ou “Presidente voto não” ou ainda somente “Voto sim” ou “Voto não”. Realmente esses deputados foram exceção, pois a maioria aproveitou a oportunidade para falar muito.
Outro fato interessante que surgiu foi a semelhança entre os discursos dos deputados Angelim (PT-AC) e Bacelar (PTN-BA), que votaram contra e disseram basicamente a mesma coisa:
Angelin: “Em respeito à Constituição, em defesa da democracia e pelo povo brasileiro, voto não”.
Bacelar: “Em respeito à Constituição, à democracia e ao povo, voto não”.
Do ponto de vista de quem votou sim, os discursos dos deputados Remídio Monai (PR-RR) e João Derly (Rede-RS) também foram bem parecidos:
Remídio Monai: “Com a minha consciência, pela minha família, por Roraima e pelo Brasil, eu voto sim, Sr. Presidente”.
João Derly: “Com a minha consciência tranquila, pelo Rio Grande, pelo meu Brasil, eu voto sim”.
Vale a pena notar que os discursos desses dois casos não foram logo em seguida uns dos outros. De fato, houve vários discursos entres eles, o que pode indicar que não houve “cópia”, pelo menos não nesses casos.
6) Análise temporal de palavras
A análise temporal de eventos é uma das técnicas que, infelizmente, não tem recebido a devida atenção. Com ela, é possível descobrir diversos padrões interessantes por meio da análise visual e algorítmica dos dados. Esse assunto é tão importante que eu fiz uma palestra sobre ele em 2015 no evento TDC (The Developers Conference), em São Paulo.
Para realizar a análise temporal das palavras empregadas nos discursos, eu utilizei uma ferramenta pouco conhecida chamada EventFlow. Com ela, é possível visualizar a ocorrência de eventos que, no meu cenário, são as palavras. Como não havia dados disponíveis sobre o índice de tempo de cada palavra, considerei um intervalo uniforme, ou seja, cada palavra sendo falada em um segundo. Além disso, utilizei somente as top 10 palavras mais ditas para não sobrecarregar a interface. Dessa forma, foi possível visualizar na ferramenta alguns padrões interessantes, tal como o fato de que uma parte significativa dos discursos conter a palavra PRESIDENTE logo no início.
As figuras abaixo mostram as ocorrências temporais das 10 palavras separadas pelo tipo de voto (a favor ou contra). Novamente, clique na figura para visualizá-la por inteiro.
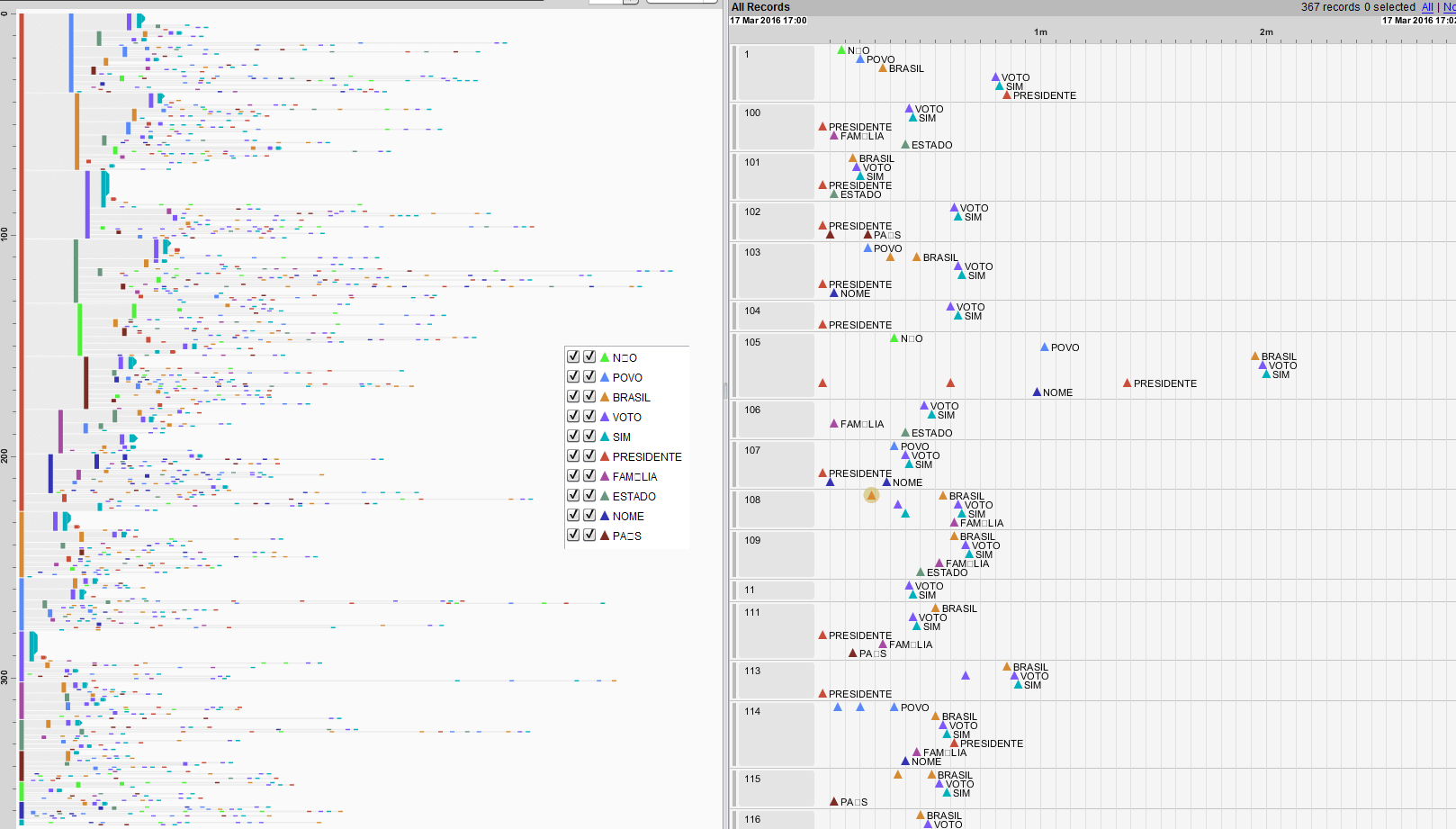
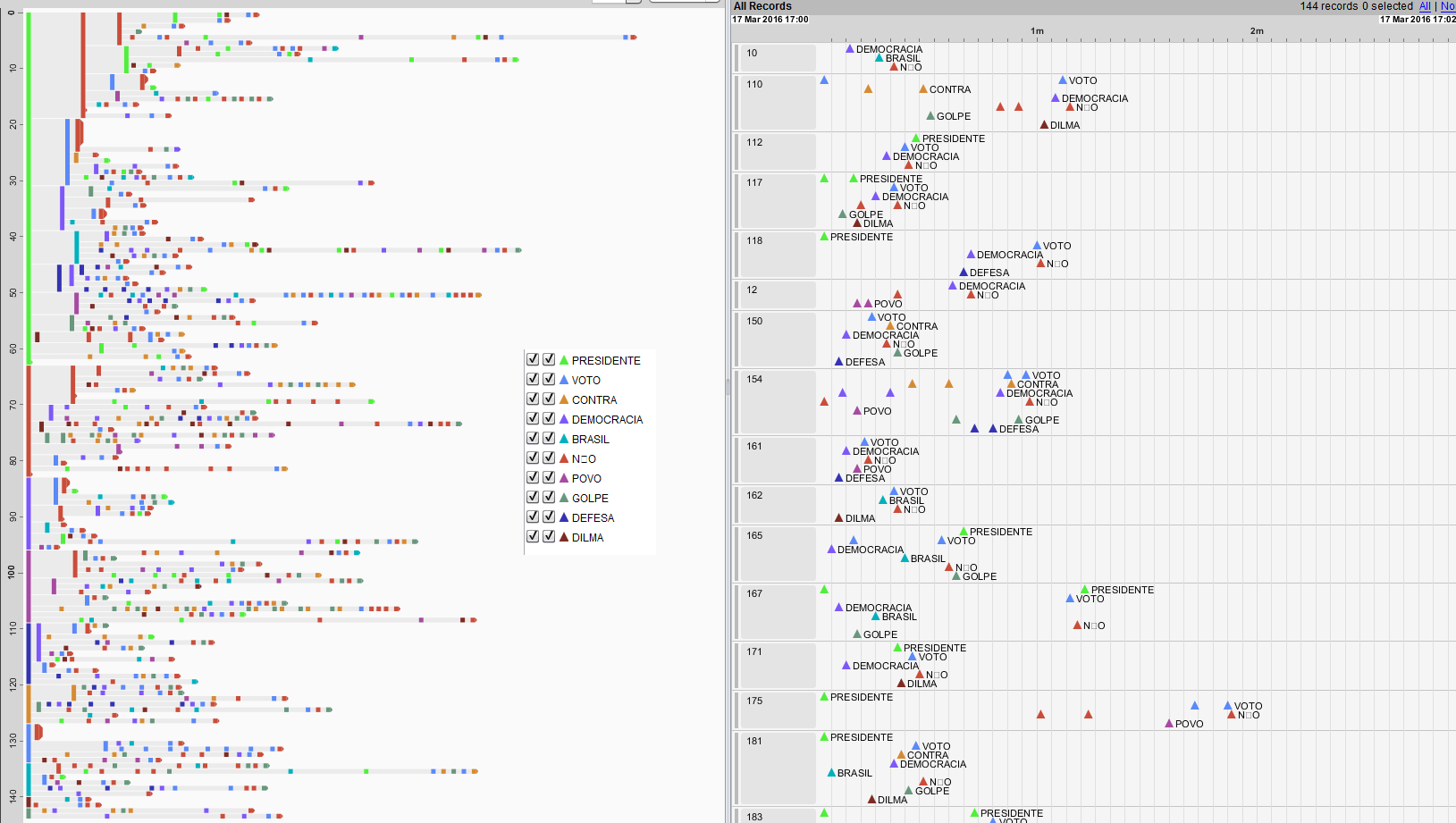
Considerando apenas as palavras SIM e NÃO de todos os deputados, pode-se notar que a palavra SIM foi muito mais utilizada do que o NÃO, em particular no começo do discurso. Esse tipo de conclusão pode ser obtida filtrando o tipo de palavra dita na interface do EventFlow, como a figura abaixo mostra.
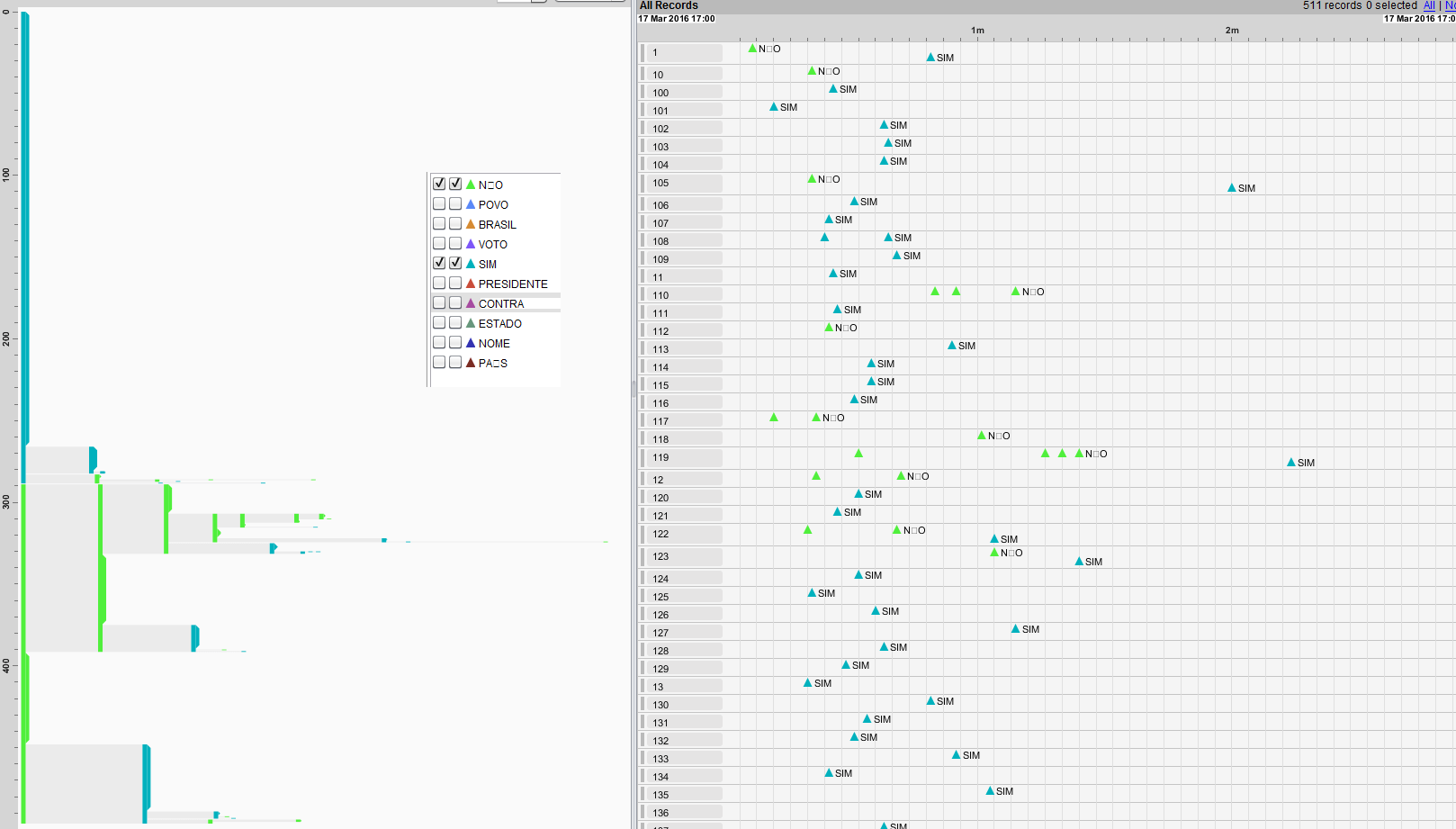
7) Predição de voto por palavra
Um dos aspectos que eu estudei foi a possibilidade de classificar um voto a favor ou contra de acordo com uma ou várias palavras. Para realizar esse tipo de classificação, eu empreguei algumas técnicas de machine learning que criam modelos de classificação.
Devido à característica dos dados, não consegui obter modelos muito bons, isto é, com uma alta taxa de predição. Contudo, descobri alguns fatos interessantes. Por exemplo, a palavra PAI aparece em 21 dos 511 discursos, e toda a vez que ela aparece o voto é sim (a favor). De fato, essa palavra foi o “atributo” que melhor classificou a amostra a favor. Além disso, podemos dizer que um discurso “médio” de um deputado que votou a favor provavelmente vai conter as palavras PAI (21), ESPOSA (18), PARANÁ (16), SANTA (15) e MÃE (13). Os números entre parênteses indicam a quantidade de discursos a favor em que essas palavras foram utilizadas.
A palavra que melhor caracterizou quem votou contra foi LUTARAM, com 7 ocorrências. De forma semelhante ao discurso a favor, podemos caracterizar o discurso “médio” de um deputado que votou contra pelas palavras LUTARAM (7), HIPOCRISIA (6), AGRÁRIA (6), TRABALHADORAS (6) e SOBERANIA (5). Os números entre parênteses indicam a quantidade de discursos contra em que essas palavras foram utilizadas. Vale a pena destacar que sempre que a palavra REFORMA foi utilizada junto de AGRÁRIA o voto foi contra.
Em termos de modelos e algoritmos, optei pela árvore de decisão, pois ela gera um resultado visual interessante. Contudo, devido às características dos dados, as árvores de decisão geradas foram excessivamente grandes. Porém, uma análise parcial com apenas 100 discursos aleatórios gerou a árvore abaixo:
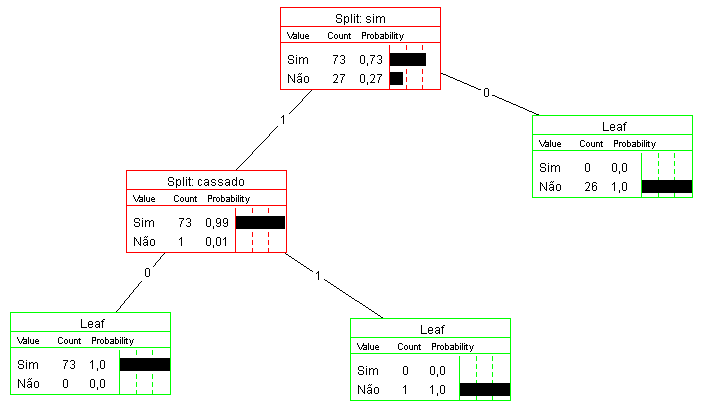
O interessante dessa árvore é notar que o “atributo” SIM foi o que representou melhor ganho, i.e. classificou os dados como NÃO (contra) quando não existia a palavra SIM no discurso. Contudo, essa árvore contou com somente 100 discursos, e a árvore gerada com o total de dados (511) ficou com mais de 40 nós.
Para finalizar, destaco que durante a análise de dados como discursos vale a pena investir e explorar outras ferramentas e técnicas de análise que vão além dos gráficos simples e nuvem de palavras. Em particular, as ferramentas interativas de análise visual, os algoritmos de mineração de dados e machine learning podem fornecer uma novo ponto de vista e descobrir padrões ‘ocultos’ nos dados que podem revelar fatos novos, algo muito procurado por jornalistas.

De 0 a 10, o quanto você recomendaria este artigo para um amigo?