



Criando um detector de sotaques com Machine Learning em PHP
No artigo de hoje vou mostrar a vocês como construir um detector de sotaques usando um algoritmo de machine learning em PHP.

Nos últimos artigos, temos falado bastante sobre machine learning, inteligência artificial e chatbots. Então, no artigo de hoje vou mostrar a vocês como construir um detector de sotaques usando um algoritmo de machine learning em PHP.
Para começar nosso trabalho, devemos criar um dicionário com algumas frases, expressões ou palavras com determinados sotaques. Depois, iremos aplicar o algoritmo de machine learning Naïve Bayes no nosso dicionário e fazer uma predição através de uma chamada de console para verificar se a predição funcionou.
Nosso dicionário de dados será criado a partir de alguns sites de internet que possuem palavras de sotaques. Iremos utilizar o Selenium WebDriver para capturar os dados do site. Caso você não saiba como utilizar o Selenium WebDriver, basta acessar esse artigo.
E para utilizar o algoritmo, iremos utilizar a biblioteca https://github.com/fieg/bayes, onde podemos fazer o treinamento dos dados e a predição utilizando a linguagem PHP.
Primeiramente, vamos criar a pasta para o projeto e instalar as dependências.
Com o git instalado, basta dar um clone no projeto:
git clone https://github.com/fieg/bayes
Depois, basta entrar na pasta e instalar o Selenium WebDriver pelo composer:
cd bayes composer require facebook/webdriver
Agora, crie um arquivo dicionario.php no diretório bayes. Esse arquivo gerará um csv (sotaque.csv) que será o arquivo com os dados para treinarmos o algoritmo.
O código para esse arquivo está abaixo. Nos comentários explico o que cada bloco significa.
<?php
//definição de namespaces, cabeçalhos e autoload de classes
namespace Facebook\WebDriver;
header("Content-type: text/html; charset=utf-8");
use Facebook\WebDriver\Remote\DesiredCapabilities;
use Facebook\WebDriver\Remote\RemoteWebDriver;
require_once('vendor/autoload.php');
//definição dos sites de fontes de dados
$siteMineiro = 'http://nacozinhadamargo.blogspot.com.br/2013/08/palavras-e-expressoes-de-minas-gerais.html';
$siteCearense = 'http://soudonordeste.com.br/dicionario-cearense-cearenses/';
$siteCarioca = 'http://diariodorio.com/um-dicionario-de-carioques-portugues/';
//inicialização do Selenium WebDriver
$host = 'http://localhost:4444/wd/hub'; // this is the default
$capabilities = DesiredCapabilities::chrome();
$driver = RemoteWebDriver::create($host, $capabilities, 5000);
//carregamento do site referente aos dados do sotaque mineiro
$driver->get($siteMineiro);
//é um array retornado os objetos html que estão na tag <i>
$linhas = $driver->findElements(
WebDriverBy::cssSelector('i')
);
foreach ($linhas as $linha) {
// separamos todos as palavras que possuirem virgulas.
$linhax = explode(',', strtolower($linha->getText()));
foreach ($linhax as $linhaz) {
//cada linha é salva no arquivo sotaque.csv
file_put_contents('sotaque.csv', trim(str_replace('-', '',trim($linhaz))) . ',mineiro' . PHP_EOL, FILE_APPEND);
}
}
//carregamento do site referente aos dados do sotaque cearense
$driver->get($siteCearense);
//é um array retornado os objetos html que estão na tag <b>
$linhas = $driver->findElements(
WebDriverBy::cssSelector('b')
);
foreach ($linhas as $linha) {
// separamos todos as palavras que possuirem virgulas.
$linhax = explode(',', strtolower($linha->getText()));
foreach ($linhax as $linhaz) {
//cada linha é salva no arquivo sotaque.csv
file_put_contents('sotaque.csv', trim(str_replace('-', '', trim($linhaz))) . ',cearense' . PHP_EOL, FILE_APPEND);
}
}
$driver->get($siteCarioca);
//é um array retornado os objetos html que estão na tag <strong> dentro de um <p>
$linhas = $driver->findElements(
WebDriverBy::cssSelector('p strong')
);
foreach ($linhas as $linha) {
// separamos todos as palavras que possuirem virgulas.
$linhax = explode(',', strtolower($linha->getText()));
foreach ($linhax as $linhaz) {
//cada linha é salva no arquivo sotaque.csv
file_put_contents('sotaque.csv', trim(str_replace('-', '', trim($linhaz))) . ',carioca' . PHP_EOL, FILE_APPEND);
}
}
// fecha o selenium
$driver->quit();
Lembre-se que você deverá ter inicializado o Selenium Server em um terminal para rodar o arquivo acima.
Então, basta rodar o arquivo pelo php que o dicionário deverá ser criado.
php dicionario.php
Ele criará um arquivo csv com algumas entradas do tipo:
“palavra”,”sotaque”
Exemplo:
- abrícafaca,mineiro
- acânho,mineiro
- acóde eu,mineiro
- agurinha,mineiro
- alííí ou,mineiro
- é pertin,mineiro
- alpendre,mineiro
…
Após criar o dicionário, devemos, então, realizar o treino dos dados e criar o arquivo para predição.
Podemos nomear como “sotaque.php”. E o código dele está abaixo, explicado novamente nos comentários.
<?php
//autoload de classes
include 'vendor/autoload.php';
use Fieg\Bayes\Classifier;
use Fieg\Bayes\Tokenizer\WhitespaceAndPunctuationTokenizer;
//criando o tokenizador e o classificador
$tokenizer = new WhitespaceAndPunctuationTokenizer();
$classifier = new Classifier($tokenizer);
//capturando cada linha do csv e treinando os dados
$file = fopen('sotaque.csv', 'r');
while (($line = fgetcsv($file, 1000, ",")) !== FALSE) {
$classifier->train($line[1], $line[0]);
}
//fazendo a predição do argv e retornando o print_r do resultado
$result = $classifier->classify($argv[1]);
print_r($result);
Bem, então é só rodar o arquivo passando um argumento e ele retornará a porcentagem de chance da expressão ser de cada um dos sotaques.
Exemplo:
php sotaque.php “trem bão”
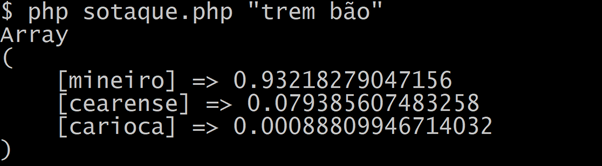
Lembrando que a porcentagem total pode ser maior que 100%. Deve se levar em consideração o maior número. Caso o algoritmo não saiba de qual sotaque é uma expressão, nesse caso ele retorna o valor 0.5 para cada sotaque.
Espero que tenham gostado, até a próxima.
MBA em Engenharia de Softwares Orientado para Serviços pela Metrocamp, Campinas/SP. Bacharel em Matemática Aplicada e Computacional pela Universidade Federal Rural do Rio de Janeiro, Community Manager do iMasters. Programador PHP desde 2002. Evangelista PHPSP. Desenvolve sistemas desde batalhas Pokemon em mIRC, a robôs automatizadores de tarefas.



